Original Source: https://www.smashingmagazine.com/2018/11/pitfalls-automatically-inlined-code/
Avoiding The Pitfalls Of Automatically Inlined Code
Avoiding The Pitfalls Of Automatically Inlined Code
Leonardo Losoviz
2018-11-26T14:00:08+01:00
2018-11-26T18:45:55+00:00
Inlining is the process of including the contents of files directly in the HTML document: CSS files can be inlined inside a style element, and JavaScript files can be inlined inside a script element:
<style>
/* CSS contents here */
</style>
<script>
/* JS contents here */
</script>
By printing the code already in the HTML output, inlining avoids render-blocking requests and executes the code before the page is rendered. As such, it is useful for improving the perceived performance of the site (i.e. the time it takes for a page to become usable.) For instance, we can use the buffer of data delivered immediately when loading the site (around 14kb) to inline the critical styles, including styles of above-the-fold content (as had been done on the previous Smashing Magazine site), and font sizes and layout widths and heights to avoid a jumpy layout re-rendering when the rest of the data is delivered.
However, when overdone, inlining code can also have negative effects on the performance of the site: Because the code is not cacheable, the same content is sent to the client repeatedly, and it can’t be pre-cached through Service Workers, or cached and accessed from a Content Delivery Network. In addition, inline scripts are considered not safe when implementing a Content Security Policy (CSP). Then, it makes a sensible strategy to inline those critical portions of CSS and JS that make the site load faster but avoided as much as possible otherwise.
With the objective of avoiding inlining, in this article we will explore how to convert inline code to static assets: Instead of printing the code in the HTML output, we save it to disk (effectively creating a static file) and add the corresponding <script> or <link> tag to load the file.
Let’s get started!
Recommended reading: WordPress Security As A Process
Front-end is messy and complicated these days. That’s why we publish articles, printed books and webinars with useful techniques to improve your work. Even better: Smashing Membership with a growing selection of front-end & UX goodies. So you get your work done, better and faster.
Explore Smashing Membership ↬

When To Avoid Inlining
There is no magic recipe to establish if some code must be inlined or not, however, it can be pretty evident when some code must not be inlined: when it involves a big chunk of code, and when it is not needed immediately.
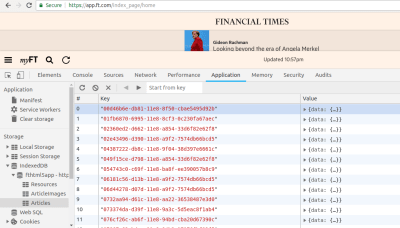
As an example, WordPress sites inline the JavaScript templates to render the Media Manager (accessible in the Media Library page under /wp-admin/upload.php), printing a sizable amount of code:
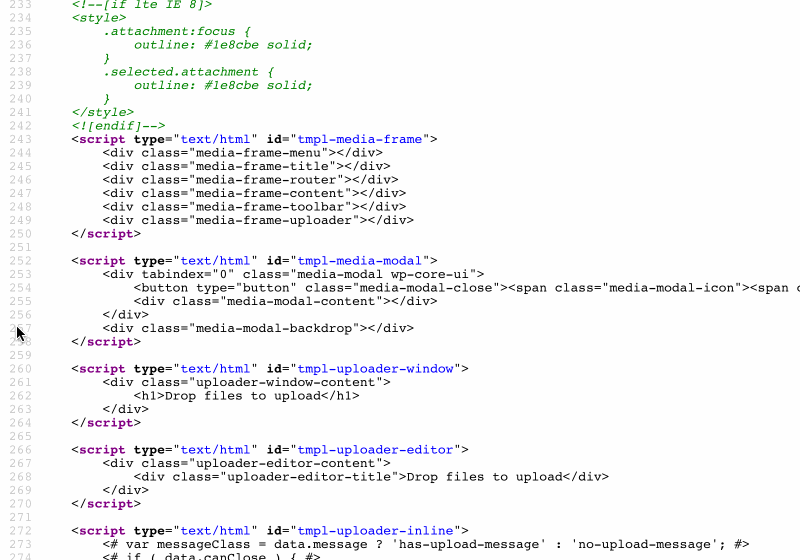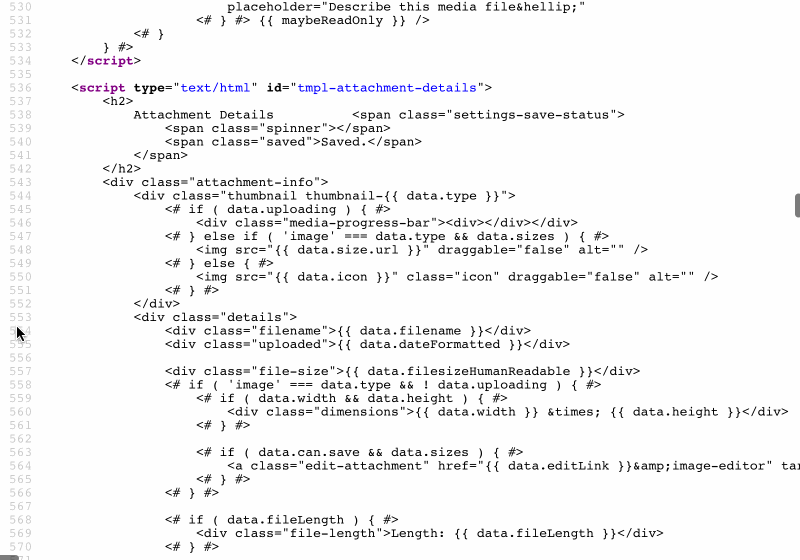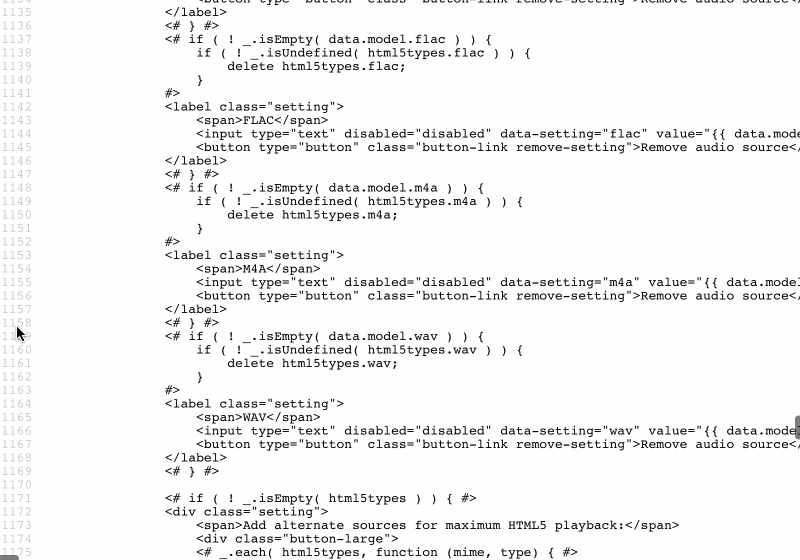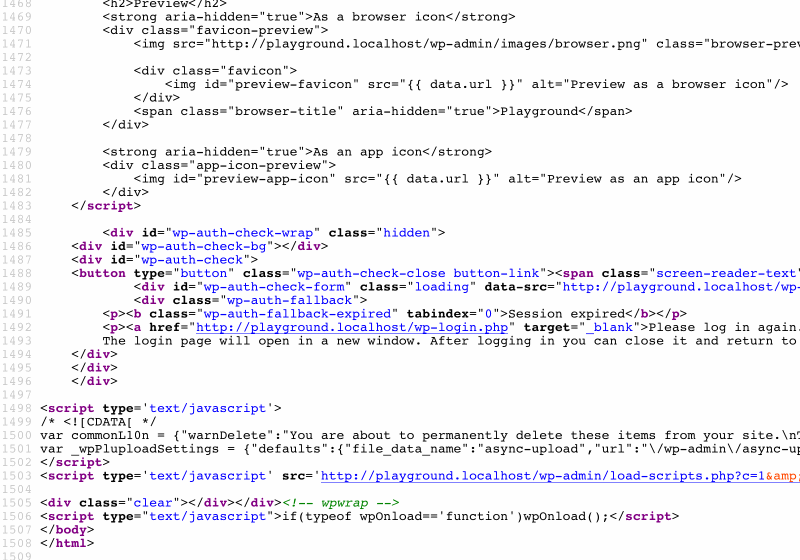 JavaScript templates inlined by the WordPress Media Manager.
JavaScript templates inlined by the WordPress Media Manager.
Occupying a full 43kb, the size of this piece of code is not negligible, and since it sits at the bottom of the page it is not needed immediately. Hence, it would make plenty of sense to serve this code through static assets instead or printing it inside the HTML output.
Let’s see next how to transform inline code into static assets.
Triggering The Creation Of Static Files
If the contents (the ones to be inlined) come from a static file, then there is not much to do other than simply request that static file instead of inlining the code.
For dynamic code, though, we must plan how/when to generate the static file with its contents. For instance, if the site offers configuration options (such as changing the color scheme or the background image), when should the file containing the new values be generated? We have the following opportunities for creating the static files from the dynamic code:
On request
When a user accesses the content for the first time.
On change
When the source for the dynamic code (e.g. a configuration value) has changed.
Let’s consider on request first. The first time a user accesses the site, let’s say through /index.html, the static file (e.g. header-colors.css) doesn’t exist yet, so it must be generated then. The sequence of events is the following:
The user requests /index.html;
When processing the request, the server checks if the file header-colors.css exists. Since it does not, it obtains the source code and generates the file on disk;
It returns a response to the client, including tag <link rel="stylesheet" type="text/css" href="/staticfiles/header-colors.css">
The browser fetches all the resources included in the page, including header-colors.css;
By then this file exists, so it is served.
However, the sequence of events could also be different, leading to an unsatisfactory outcome. For instance:
The user requests /index.html;
This file is already cached by the browser (or some other proxy, or through Service Workers), so the request is never sent to the server;
The browser fetches all the resources included in the page, including header-colors.css. This image is, however, not cached in the browser, so the request is sent to the server;
The server hasn’t generated header-colors.css yet (e.g. it was just restarted);
It will return a 404.
Alternatively, we could generate header-colors.css not when requesting /index.html, but when requesting /header-colors.css itself. However, since this file initially doesn’t exist, the request is already treated as a 404. Even though we could hack our way around it, altering the headers to change the status code to a 200, and returning the content of the image, this is a terrible way of doing things, so we will not entertain this possibility (we are much better than this!)
That leaves only one option: generating the static file after its source has changed.
Creating The Static File When The Source Changes
Please notice that we can create dynamic code from both user-dependant and site-dependant sources. For instance, if the theme enables to change the site’s background image and that option is configured by the site’s admin, then the static file can be generated as part of the deployment process. On the other hand, if the site allows its users to change the background image for their profiles, then the static file must be generated on runtime.
In a nutshell, we have these two cases:
User Configuration
The process must be triggered when the user updates a configuration.
Site Configuration
The process must be triggered when the admin updates a configuration for the site, or before deploying the site.
If we considered the two cases independently, for #2 we could design the process on any technology stack we wanted. However, we don’t want to implement two different solutions, but a unique solution which can tackle both cases. And because from #1 the process to generate the static file must be triggered on the running site, then it is compelling to design this process around the same technology stack the site runs on.
When designing the process, our code will need to handle the specific circumstances of both #1 and #2:
Versioning
The static file must be accessed with a “version” parameter, in order to invalidate the previous file upon the creation of a new static file. While #2 could simply have the same versioning as the site, #1 needs to use a dynamic version for each user, possibly saved in the database.
Location of the generated file
#2 generates a unique static file for the whole site (e.g. /staticfiles/header-colors.css), while #1 creates a static file for each user (e.g. /staticfiles/users/leo/header-colors.css).
Triggering event
While for #1 the static file must be executed on runtime, for #2 it can also be executed as part of a build process in our staging environment.
Deployment and distribution
Static files in #2 can be seamlessly integrated inside the site’s deployment bundle, presenting no challenges; static files in #1, however, cannot, so the process must handle additional concerns, such as multiple servers behind a load balancer (will the static files be created in 1 server only, or in all of them, and how?).
Let’s design and implement the process next. For each static file to be generated we must create an object containing the file’s metadata, calculate its content from the dynamic sources, and finally save the static file to disk. As a use case to guide the explanations below, we will generate the following static files:
header-colors.css, with some style from values saved in the database
welcomeuser-data.js, containing a JSON object with user data under some variable: window.welcomeUserData = {name: "Leo"};.
Below, I will describe the process to generate the static files for WordPress, for which we must base the stack on PHP and WordPress functions. The function to generate the static files before deployment can be triggered by loading a special page executing shortcode [create_static_files] as I have described in a previous article.
Further recommended reading: Making A Service Worker: A Case Study
Representing The File As An Object
We must model a file as a PHP object with all corresponding properties, so we can both save the file on disk on a specific location (e.g. either under /staticfiles/ or /staticfiles/users/leo/), and know how to request the file consequently. For this, we create an interface Resource returning both the file’s metadata (filename, dir, type: “css” or “js”, version, and dependencies on other resources) and its content.
interface Resource {
function get_filename();
function get_dir();
function get_type();
function get_version();
function get_dependencies();
function get_content();
}
In order to make the code maintainable and reusable we follow the SOLID principles, for which we set an object inheritance scheme for resources to gradually add properties, starting from the abstract class ResourceBase from which all our Resource implementations will inherit:
abstract class ResourceBase implements Resource {
function get_dependencies() {
// By default, a file has no dependencies
return array();
}
}
Following SOLID, we create subclasses whenever properties differ. As stated earlier, the location of the generated static file, and the versioning to request it will be different depending on the file being about the user or site configuration:
abstract class UserResourceBase extends ResourceBase {
function get_dir() {
// A different file and folder for each user
$user = wp_get_current_user();
return “/staticfiles/users/{$user->user_login}/”;
}
function get_version() {
// Save the resource version for the user under her meta data.
// When the file is regenerated, must execute `update_user_meta` to increase the version number
$user_id = get_current_user_id();
$meta_key = “resource_version_”.$this->get_filename();
return get_user_meta($user_id, $meta_key, true);
}
}
abstract class SiteResourceBase extends ResourceBase {
function get_dir() {
// All files are placed in the same folder
return “/staticfiles/”;
}
function get_version() {
// Same versioning as the site, assumed defined under a constant
return SITE_VERSION;
}
}
Finally, at the last level, we implement the objects for the files we want to generate, adding the filename, the type of file, and the dynamic code through function get_content:
class HeaderColorsSiteResource extends SiteResourceBase {
function get_filename() {
return “header-colors”;
}
function get_type() {
return “css”;
}
function get_content() {
return sprintf(
”
.site-title a {
color: #%s;
}
“, esc_attr(get_header_textcolor())
);
}
}
class WelcomeUserDataUserResource extends UserResourceBase {
function get_filename() {
return “welcomeuser-data”;
}
function get_type() {
return “js”;
}
function get_content() {
$user = wp_get_current_user();
return sprintf(
“window.welcomeUserData = %s;”,
json_encode(
array(
“name” => $user->display_name
)
)
);
}
}
With this, we have modeled the file as a PHP object. Next, we need to save it to disk.
Saving The Static File To Disk
Saving a file to disk can be easily accomplished through the native functions provided by the language. In the case of PHP, this is accomplished through the function fwrite. In addition, we create a utility class ResourceUtils with functions providing the absolute path to the file on disk, and also its path relative to the site’s root:
class ResourceUtils {
protected static function get_file_relative_path($fileObject) {
return $fileObject->get_dir().$fileObject->get_filename().”.”.$fileObject->get_type();
}
static function get_file_path($fileObject) {
// Notice that we must add constant WP_CONTENT_DIR to make the path absolute when saving the file
return WP_CONTENT_DIR.self::get_file_relative_path($fileObject);
}
}
class ResourceGenerator {
static function save($fileObject) {
$file_path = ResourceUtils::get_file_path($fileObject);
$handle = fopen($file_path, “wb”);
$numbytes = fwrite($handle, $fileObject->get_content());
fclose($handle);
}
}
Then, whenever the source changes and the static file needs to be regenerated, we execute ResourceGenerator::save passing the object representing the file as a parameter. The code below regenerates, and saves on disk, files “header-colors.css” and “welcomeuser-data.js”:
// When need to regenerate header-colors.css, execute:
ResourceGenerator::save(new HeaderColorsSiteResource());
// When need to regenerate welcomeuser-data.js, execute:
ResourceGenerator::save(new WelcomeUserDataUserResource());
Once they exist, we can enqueue files to be loaded through the <script> and <link> tags.
Enqueuing The Static Files
Enqueuing the static files is no different than enqueuing any resource in WordPress: through functions wp_enqueue_script and wp_enqueue_style. Then, we simply iterate all the object instances and use one hook or the other depending on their get_type() value being either "js" or "css".
We first add utility functions to provide the file’s URL, and to tell the type being either JS or CSS:
class ResourceUtils {
// Continued from above…
static function get_file_url($fileObject) {
// Add the site URL before the file path
return get_site_url().self::get_file_relative_path($fileObject);
}
static function is_css($fileObject) {
return $fileObject->get_type() == “css”;
}
static function is_js($fileObject) {
return $fileObject->get_type() == “js”;
}
}
An instance of class ResourceEnqueuer will contain all the files that must be loaded; when invoked, its functions enqueue_scripts and enqueue_styles will do the enqueuing, by executing the corresponding WordPress functions (wp_enqueue_script and wp_enqueue_style respectively):
class ResourceEnqueuer {
protected $fileObjects;
function __construct($fileObjects) {
$this->fileObjects = $fileObjects;
}
protected function get_file_properties($fileObject) {
$handle = $fileObject->get_filename();
$url = ResourceUtils::get_file_url($fileObject);
$dependencies = $fileObject->get_dependencies();
$version = $fileObject->get_version();
return array($handle, $url, $dependencies, $version);
}
function enqueue_scripts() {
$jsFileObjects = array_map(array(ResourceUtils::class, ‘is_js’), $this->fileObjects);
foreach ($jsFileObjects as $fileObject) {
list($handle, $url, $dependencies, $version) = $this->get_file_properties($fileObject);
wp_register_script($handle, $url, $dependencies, $version);
wp_enqueue_script($handle);
}
}
function enqueue_styles() {
$cssFileObjects = array_map(array(ResourceUtils::class, ‘is_css’), $this->fileObjects);
foreach ($cssFileObjects as $fileObject) {
list($handle, $url, $dependencies, $version) = $this->get_file_properties($fileObject);
wp_register_style($handle, $url, $dependencies, $version);
wp_enqueue_style($handle);
}
}
}
Finally, we instantiate an object of class ResourceEnqueuer with a list of the PHP objects representing each file, and add a WordPress hook to execute the enqueuing:
// Initialize with the corresponding object instances for each file to enqueue
$fileEnqueuer = new ResourceEnqueuer(
array(
new HeaderColorsSiteResource(),
new WelcomeUserDataUserResource()
)
);
// Add the WordPress hooks to enqueue the resources
add_action(‘wp_enqueue_scripts’, array($fileEnqueuer, ‘enqueue_scripts’));
add_action(‘wp_print_styles’, array($fileEnqueuer, ‘enqueue_styles’));
That’s it: Being enqueued, the static files will be requested when loading the site in the client. We have succeeded to avoid printing inline code and loading static resources instead.
Next, we can apply several improvements for additional performance gains.
Recommended reading: An Introduction To Automated Testing Of WordPress Plugins With PHPUnit
Bundling Files Together
Even though HTTP/2 has reduced the need for bundling files, it still makes the site faster, because the compression of files (e.g. through GZip) will be more effective, and because browsers (such as Chrome) have a bigger overhead processing many resources.
By now, we have modeled a file as a PHP object, which allows us to treat this object as an input to other processes. In particular, we can repeat the same process above to bundle all files from the same type together and serve the bundled version instead of all the independent files. For this, we create a function get_content which simply extracts the content from every resource under $fileObjects, and prints it again, producing the aggregation of all content from all resources:
abstract class SiteBundleBase extends SiteResourceBase {
protected $fileObjects;
function __construct($fileObjects) {
$this->fileObjects = $fileObjects;
}
function get_content() {
$content = “”;
foreach ($this->fileObjects as $fileObject) {
$content .= $fileObject->get_content().PHP_EOL;
}
return $content;
}
}
We can bundle all files together into the file bundled-styles.css by creating a class for this file:
class StylesSiteBundle extends SiteBundleBase {
function get_filename() {
return “bundled-styles”;
}
function get_type() {
return “css”;
}
}
Finally, we simply enqueue these bundled files, as before, instead of all the independent resources. For CSS, we create a bundle containing files header-colors.css, background-image.css and font-sizes.css, for which we simply instantiate StylesSiteBundle with the PHP object for each of these files (and likewise we can create the JS bundle file):
$fileObjects = array(
// CSS
new HeaderColorsSiteResource(),
new BackgroundImageSiteResource(),
new FontSizesSiteResource(),
// JS
new WelcomeUserDataUserResource(),
new UserShoppingItemsUserResource()
);
$cssFileObjects = array_map(array(ResourceUtils::class, ‘is_css’), $fileObjects);
$jsFileObjects = array_map(array(ResourceUtils::class, ‘is_js’), $fileObjects);
// Use this definition of $fileEnqueuer instead of the previous one
$fileEnqueuer = new ResourceEnqueuer(
array(
new StylesSiteBundle($cssFileObjects),
new ScriptsSiteBundle($jsFileObjects)
)
);
That’s it. Now we will be requesting only one JS file and one CSS file instead of many.
A final improvement for perceived performance involves prioritizing assets, by delaying loading those assets which are not needed immediately. Let’s tackle this next.
async/defer Attributes For JS Resources
We can add attributes async and defer to the <script> tag, to alter when the JavaScript file is downloaded, parsed and executed, as to prioritize critical JavaScript and push everything non-critical for as late as possible, thus decreasing the site’s apparent loading time.
To implement this feature, following the SOLID principles, we should create a new interface JSResource (which inherits from Resource) containing functions is_async and is_defer. However, this would close the door to <style> tags eventually supporting these attributes too. So, with adaptability in mind, we take a more open-ended approach: we simply add a generic method get_attributes to interface Resource as to keep it flexible to add to any attribute (either already existing ones or yet to be invented) for both <script> and <link> tags:
interface Resource {
// Continued from above…
function get_attributes();
}
abstract class ResourceBase implements Resource {
// Continued from above…
function get_attributes() {
// By default, no extra attributes
return ”;
}
}
WordPress doesn’t offer an easy way to add extra attributes to the enqueued resources, so we do it in a rather hacky way, adding a hook that replaces a string inside the tag through function add_script_tag_attributes:
class ResourceEnqueuerUtils {
protected static tag_attributes = array();
static function add_tag_attributes($handle, $attributes) {
self::tag_attributes[$handle] = $attributes;
}
static function add_script_tag_attributes($tag, $handle, $src) {
if ($attributes = self::tag_attributes[$handle]) {
$tag = str_replace(
” src=’${src}’>”,
” src=’${src}’ “.$attributes.”>”,
$tag
);
}
return $tag;
}
}
// Initize by connecting to the WordPress hook
add_filter(
‘script_loader_tag’,
array(ResourceEnqueuerUtils::class, ‘add_script_tag_attributes’),
PHP_INT_MAX,
3
);
We add the attributes for a resource when creating the corresponding object instance:
abstract class ResourceBase implements Resource {
// Continued from above…
function __construct() {
ResourceEnqueuerUtils::add_tag_attributes($this->get_filename(), $this->get_attributes());
}
}
Finally, if resource welcomeuser-data.js doesn’t need to be executed immediately, we can then set it as defer:
class WelcomeUserDataUserResource extends UserResourceBase {
// Continued from above…
function get_attributes() {
return “defer=’defer'”;
}
}
Because it is loaded as deferred, a script will load later, bringing forward the point in time in which the user can interact with the site. Concerning performance gains, we are all set now!
There is one issue left to resolve before we can relax: what happens when the site is hosted on multiple servers?
Dealing With Multiple Servers Behind A Load Balancer
If our site is hosted on several sites behind a load balancer, and a user-configuration dependant file is regenerated, the server handling the request must, somehow, upload the regenerated static file to all the other servers; otherwise, the other servers will serve a stale version of that file from that moment on. How do we do this? Having the servers communicate to each other is not just complex, but may ultimately prove unfeasible: What happens if the site runs on hundreds of servers, from different regions? Clearly, this is not an option.
The solution I came up with is to add a level of indirection: instead of requesting the static files from the site URL, they are requested from a location in the cloud, such as from an AWS S3 bucket. Then, upon regenerating the file, the server will immediately upload the new file to S3 and serve it from there. The implementation of this solution is explained in my previous article Sharing Data Among Multiple Servers Through AWS S3.
Conclusion
In this article, we have considered that inlining JS and CSS code is not always ideal, because the code must be sent repeatedly to the client, which can have a hit on performance if the amount of code is significant. We saw, as an example, how WordPress loads 43kb of scripts to print the Media Manager, which are pure JavaScript templates and could perfectly be loaded as static resources.
Hence, we have devised a way to make the website faster by transforming the dynamic JS and CSS inline code into static resources, which can enhance caching at several levels (in the client, Service Workers, CDN), allows to further bundle all files together into just one JS/CSS resource as to improve the ratio when compressing the output (such as through GZip) and to avoid an overhead in browsers from processing several resources concurrently (such as in Chrome), and additionally allows to add attributes async or defer to the <script> tag to speed up the user interactivity, thus improving the site’s apparent loading time.
As a beneficial side effect, splitting the code into static resources also allows the code to be more legible, dealing with units of code instead of big blobs of HTML, which can lead to a better maintenance of the project.
The solution we developed was done in PHP and includes a few specific bits of code for WordPress, however, the code itself is extremely simple, barely a few interfaces defining properties and objects implementing those properties following the SOLID principles, and a function to save a file to disk. That’s pretty much it. The end result is clean and compact, straightforward to recreate for any other language and platform, and not difficult to introduce to an existing project — providing easy performance gains.

(rb, ra, yk, il)

















 DOMmy.js is a super-lightweight, standalone Javascript library, designed to work easily with the DOM and produce powerful CSS3 animations via JS.
DOMmy.js is a super-lightweight, standalone Javascript library, designed to work easily with the DOM and produce powerful CSS3 animations via JS.