Creating Voice Skills For Google Assistant And Amazon Alexa
Original Source: https://www.smashingmagazine.com/2019/12/voice-skills-google-assistant-amazon-alexa/
Creating Voice Skills For Google Assistant And Amazon Alexa
Creating Voice Skills For Google Assistant And Amazon Alexa
Tris Tolliday
2019-12-23T12:00:00+00:00
2019-12-24T12:35:33+00:00
Over the past decade, there has been a seismic shift towards conversational interfaces. As people reach ‘peak screen’ and even begin to scale back their device usage with digital wellbeing features being baked into most operating systems.
To combat screen fatigue, voice assistants have entered the market to become a preferred option for quickly retrieving information. A well-repeated stat states that 50% of searches will be done by voice in year 2020. Also, as adoption rises, it’s up to developers to add “Conversational Interfaces” and “Voice Assistants” to their tool belt.
Designing The Invisible
For many, embarking on a voice UI (VUI) project can be a bit like entering the Unknown. Find out more about the lessons learned by William Merrill when designing for voice. Read article →
What Is A Conversational Interface?
A Conversational Interface (sometimes shortened to CUI, is any interface in a human language. It is tipped to be a more natural interface for the general public than the Graphic User Interface GUI, which front end developers are accustomed to building. A GUI requires humans to learn its specific syntaxes of the interface (think buttons, sliders, and drop-downs).
This key difference in using human language makes CUI more natural for people; it requires little knowledge and puts the burden of understanding on the device.
Commonly CUIs comes in two guises: Chatbots and Voice Assistants. Both have seen a massive rise in uptake over the last decade thanks to advances in Natural Language Processing (NLP).
Understanding Voice Jargon

(Large preview)
Keyword
Meaning
Skill/Action
A voice application, which can fulfill a series of intents
Intent
Intended action for the skill to fulfill, what the user wants the skill to do in response to what they say.
Utterance
The sentence a user says, or utters.
Wake Word
The word or phrase used to start a voice assistant listening, e.g. ‘Hey google’, ‘Alexa’ or ‘Hey Siri’
Context
The pieces of contextual information within an utterance, that helps the skill fulfill an intent, e.g. ‘today’, ‘now’, ‘when I get home’.
What Is A Voice Assistant?
A voice assistant is a piece of software capable of NLP (Natural Language Processing). It receives a voice command and returns an answer in audio format. In recent years the scope of how you can engage with an assistant is expanding and evolving, but the crux of the technology is natural language in, lots of computation, natural language out.
For those looking for a bit more detail:
The software receives an audio request from a user, processes the sound into phonemes, the building blocks of language.
By the magic of AI (Specifically Speech-To-Text), these phonemes are converted into a string of the approximated request, this is kept within a JSON file which also contains extra information about the user, the request and the session.
The JSON is then processed (usually in the cloud) to work out the context and intent of the request.
Based on the intent, a response is returned, again within a larger JSON response, either as a string or as SSML (more on that later)
The response is processed back using AI (naturally the reverse – Text-To-Speech) which is then returned to the user.
There’s a lot going on there, most of which don’t require a second thought. But each platform does this differently, and it’s the nuances of the platform that require a bit more understanding.

(Large preview)
Voice-Enabled Devices
The requirements for a device to be able to have a voice assistant baked in are pretty low. They require a Microphone, an internet connection, and a Speaker. Smart Speakers like the Nest Mini & Echo Dot provide this kind of low-fi voice control.
Next up in the ranks is voice + screen, this is known as a ‘Multimodal’ device (more on these later), and are devices like the Nest Hub and the Echo Show. As smartphones have this functionality, they can also be considered a type of Multimodal voice-enabled device.
Voice Skills
First off, every platform has a different name for their ‘Voice Skills’, Amazon goes with skills, which I will be sticking with as a universally understood term. Google opts for ‘Actions’, and Samsung goes for ‘capsules’.
Each platform has its own baked-in skills, like asking the time, weather and sports games. Developer-made (third-party) skills can be invoked with a specific phrase, or, if the platform likes it, can be implicitly invoked, without a key phrase.
Explicit Invocation: ”Hey Google, Talk to <app name>.”
It is explicitly stated which skill is being asked for:
Implicit Invocation: ”Hey Google, what is the weather like today?”
It is implied by the context of the request what service the user wants.
What Voice Assistants Are There?
In the western market, voice assistants are very much a three-horse race. Apple, Google and Amazon have very different approaches to their assistants, and as such, appeal to different types of developers and customers.
Apple’s Siri
Device Names: ”Google Home, Nest”
Wake Phrase: ”Hey Siri”
Siri has over 375 million active users, but for the sake of brevity, I am not going into too much detail for Siri. While it may be globally well adopted, and baked into most Apple devices, it requires developers to already have an app on one of Apple’s platforms and is written in swift (whereas the others can be written in everyone’s favorite: Javascript). Unless you are an app developer who wants to expand their app’s offering, you can currently skip past apple until they open up their platform.
Google Assistant
Device Names: ”Google Home, Nest”
Wake Phrase: ”Hey Google”
Google has the most devices of the big three, with over 1 Billion worldwide, this is mostly due to the mass of Android devices that have Google Assistant baked in, with regards to their dedicated smart speakers, the numbers are a little smaller. Google’s overall mission with its assistant is to delight users, and they have always been very good at providing light and intuitive interfaces.
Their primary aim on the platform is to use time — with the idea of becoming a regular part of customers’ daily routine. As such, they primarily focus on utility, family fun, and delightful experiences.
Skills built for Google are best when they are engagement pieces and games, focusing primarily on family-friendly fun. Their recent addition of canvas for games is a testament to this approach. The Google platform is much stricter for submissions of skills, and as such, their directory is a lot smaller.
Amazon Alexa
Device Names: “Amazon Fire, Amazon Echo”
Wake Phrase: “Alexa”
Amazon has surpassed 100 million devices in 2019, this predominantly comes from sales of their smart speakers and smart displays, as well as their ‘fire’ range or tablets and streaming devices.
Skills built for Amazon tend to be aimed at in skill purchasing. If you are looking for a platform to expand your e-commerce/service, or offer a subscription then Amazon is for you. That being said, ISP isn’t a requirement for Alexa Skills, they support all sorts of uses, and are much more open to submissions.
The Others
There are even more Voice assistants out there, such as Samsung’s Bixby, Microsoft’s Cortana, and the popular open-source voice assistant Mycroft. All three have a reasonable following, but are still in the minority compared to the three Goliaths of Amazon, Google and Apple.
Building On Amazon Alexa
Amazons Ecosystem for voice has evolved to allow developers to build all of their skills within the Alexa console, so as a simple example, I am going to use its built-in features.
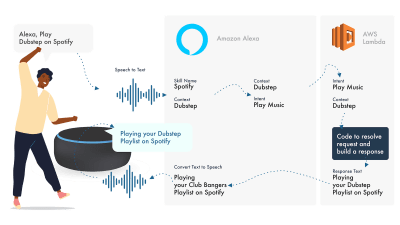
(Large preview)
Alexa deals with the Natural Language Processing and then finds an appropriate Intent, which is passed to our Lambda function to deal with the logic. This returns some conversational bits (SSML, text, cards, and so on) to Alexa, which converts those bits to audio and visuals to show on the device.
Working on Amazon is relatively simple, as they allow you to create all parts of your skill within the Alexa Developer Console. The flexibility is there to use AWS or an HTTPS endpoint, but for simple skills, running everything within the Dev console should be sufficient.
Let’s Build A Simple Alexa Skill
Head over to the Amazon Alexa console, create an account if you don’t have one, and log in,
Click Create Skill then give it a name,
Choose custom as your model,
and choose Alexa-Hosted (Node.js) for your backend resource.
Once it is done provisioning, you will have a basic Alexa skill, It will have your intent built for you, and some back end code to get you started.
If you click on the HelloWorldIntent in your Intents, you will see some sample utterances already set up for you, let’s add a new one at the top. Our skill is called hello world, so add Hello World as a sample utterance. The idea is to capture anything the user might say to trigger this intent. This could be “Hi World”, “Howdy World”, and so on.
What’s Happening In The Fulfillment JS?
So what is the code doing? Here is the default code:
const HelloWorldIntentHandler = {
canHandle(handlerInput) {
return Alexa.getRequestType(handlerInput.requestEnvelope) === ‘IntentRequest’
&& Alexa.getIntentName(handlerInput.requestEnvelope) === ‘HelloWorldIntent’;
},
handle(handlerInput) {
const speakOutput = ‘Hello World!’;
return handlerInput.responseBuilder
.speak(speakOutput)
.getResponse();
}
};
This is utilizing the ask-sdk-core and is essentially building JSON for us. canHandle is letting ask know it can handle intents, specifically ‘HelloWorldIntent’. handle takes the input, and builds the response. What this generates looks like this:
{
“body”: {
“version”: “1.0”,
“response”: {
“outputSpeech”: {
“type”: “SSML”,
“ssml”: “Hello World!”
},
“type”: “_DEFAULT_RESPONSE”
},
“sessionAttributes”: {},
“userAgent”: “ask-node/2.3.0 Node/v8.10.0”
}
}
We can see that speak outputs ssml in our json, which is what the user will hear as spoken by Alexa.
Building For Google Assistant
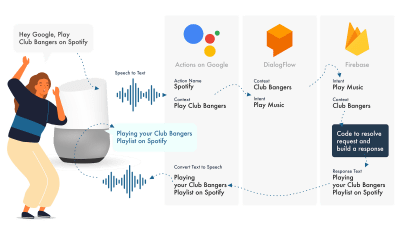
(Large preview)
The simplest way to build Actions on Google is to use their AoG console in combination with Dialogflow, you can extend your skills with firebase, but as with the Amazon Alexa tutorial, let’s keep things simple.
Google Assistant uses three primary parts, AoG, which deals with the NLP, Dialogflow, which works out your intents, and Firebase, that fulfills the request, and produces the response that will be sent back to AoG.
Just like with Alexa, Dialogflow allows you to build your functions directly within the platform.
Let’s Build An Action On Google
There are three platforms to juggle at once with Google’s solution, which are accessed by three different consoles, so tab up!
Setting Up Dialogflow
Let’s start by logging into the Dialogflow console. Once you have logged in, create a new agent from the dropdown just below the Dialogflow logo.
Give your agent a name, and add on the ‘Google Project Dropdown’, while having “Create a new Google project” selected.
Click the create button, and let it do its magic, it will take a little bit of time to set up the agent, so be patient.
Setting Up Firebase Functions
Right, now we can start to plug in the Fulfillment logic.
Head on over to the Fulfilment tab. Tick to enable the inline editor, and use the JS snippets below:
index.js
‘use strict’;
// So that you have access to the dialogflow and conversation object
const { dialogflow } = require(‘actions-on-google’);
// So you have access to the request response stuff >> functions.https.onRequest(app)
const functions = require(‘firebase-functions’);
// Create an instance of dialogflow for your app
const app = dialogflow({debug: true});
// Build an intent to be fulfilled by firebase,
// the name is the name of the intent that dialogflow passes over
app.intent(‘Default Welcome Intent’, (conv) => {
// Any extra logic goes here for the intent, before returning a response for firebase to deal with
return conv.ask(`Welcome to a firebase fulfillment`);
});
// Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it
exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);
package.json
{
“name”: “functions”,
“description”: “Cloud Functions for Firebase”,
“scripts”: {
“lint”: “eslint .”,
“serve”: “firebase serve –only functions”,
“shell”: “firebase functions:shell”,
“start”: “npm run shell”,
“deploy”: “firebase deploy –only functions”,
“logs”: “firebase functions:log”
},
“engines”: {
“node”: “10”
},
“dependencies”: {
“actions-on-google”: “^2.12.0”,
“firebase-admin”: “~7.0.0”,
“firebase-functions”: “^3.3.0”
},
“devDependencies”: {
“eslint”: “^5.12.0”,
“eslint-plugin-promise”: “^4.0.1”,
“firebase-functions-test”: “^0.1.6”
},
“private”: true
}
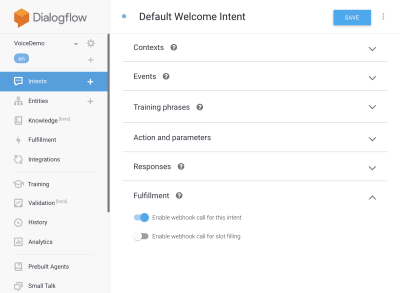
Now head back to your intents, go to Default Welcome Intent, and scroll down to fulfillment, make sure ‘Enable webhook call for this intent’ is checked for any intents your wish to fulfill with javascript. Hit Save.
(Large preview)
Setting Up AoG
We are getting close to the finish line now. Head over to the Integrations Tab, and click Integration Settings in the Google Assistant Option at the top. This will open a modal, so let’s click test, which will get your Dialogflow integrated with Google, and open up a test window on Actions on Google.
On the test window, we can click Talk to my test app (We will change this in a second), and voila, we have the message from our javascript showing on a google assistant test.
We can change the name of the assistant in the Develop tab, up at the top.
So What’s Happening In The Fulfillment JS?
First off, we are using two npm packages, actions-on-google which provides all the fulfillment that both AoG and Dialogflow need, and secondly firebase-functions, which you guessed it, contains helpers for firebase.
We then create the ‘app’ which is an object that contains all of our intents.
Each intent that is created passed ‘conv’ which is the conversation object Actions On Google sends. We can use the content of conv to detect information about previous interactions with the user (such as their ID and information about their session with us).
We return a ‘conv.ask object’, which contains our return message to the user, ready for them to respond with another intent. We could use ‘conv.close’ to end the conversation if we wanted to end the conversation there.
Finally, we wrap everything up in a firebase HTTPS function, that deals with the server-side request-response logic for us.
Again, if we look at the response that is generated:
{
“payload”: {
“google”: {
“expectUserResponse”: true,
“richResponse”: {
“items”: [
{
“simpleResponse”: {
“textToSpeech”: “Welcome to a firebase fulfillment”
}
}
]
}
}
}
}
We can see that conv.ask has had its text injected into the textToSpeech area. If we had chosen conv.close the expectUserResponse would be set to false and the conversation would close after the message had been delivered.
Third-Party Voice Builders
Much like the app industry, as voice gains traction, 3rd party tools have started popping up in an attempt to alleviate the load on developers, allowing them to build once deploy twice.
Jovo and Voiceflow are currently the two most popular, especially since PullString’s acquisition by Apple. Each platform offers a different level of abstraction, so It really just depends on how simplified you’re like your interface.
Extending Your Skill
Now that you have gotten your head around building a basic ‘Hello World’ skill, there are bells and whistles aplenty that can be added to your skill. These are the cherry on top of the cake of Voice Assistants and will give your users a lot of extra value, leading to repeat custom, and potential commercial opportunity.
SSML
SSML stands for speech synthesis markup language and operates with a similar syntax to HTML, the key difference being that you are building up a spoken response, not content on a webpage.
‘SSML’ as a term is a little misleading, it can do so much more than speech synthesis! You can have voices going in parallel, you can include ambiance noises, speechcons (worth a listen to in their own right, think emojis for famous phrases), and music.
When Should I Use SSML?
SSML is great; it makes a much more engaging experience for the user, but what is also does, is reduce the flexibility of the audio output. I recommend using it for more static areas of speech. You can use variables in it for names etc, but unless you intend on building an SSML generator, most SSML is going to be pretty static.
Start with simple speech in your skill, and once it is complete, enhance areas which are more static with SSML, but get your core right before moving on to the bells and whistles. That being said, a recent report says 71% of users prefer a human (real) voice over a synthesized one, so if you have the facility to do so, go out and do it!

(Large preview)
In Skill Purchases
In-skill purchases (or ISP) are similar to the concept of in-app purchases. Skills tend to be free, but some allow for the purchase of ‘premium’ content/subscriptions within the app, these can enhance the experience for a user, unlock new levels on games, or allow access to paywalled content.
Multimodal
Multimodal responses cover so much more than voice, this is where voice assistants can really shine with complementary visuals on devices that support them. The definition of multimodal experiences is much broader and essentially means multiple inputs (Keyboard, Mouse, Touchscreen, Voice, and so on.).
Multimodal skills are intended to complement the core voice experience, providing extra complementary information to boost the UX. When building a multimodal experience, remember that voice is the primary carrier of information. Many devices don’t have a screen, so your skill still needs to work without one, so make sure to test with multiple device types; either for real or in the simulator.

(Large preview)
Multilingual
Multilingual skills are skills that work in multiple languages and open up your skills to multiple markets.
The complexity of making your skill multilingual is down to how dynamic your responses are. Skills with relatively static responses, e.g. returning the same phrase every time, or only using a small bucket of phrases, are much easier to make multilingual than sprawling dynamic skills.
The trick with multilingual is to have a trustworthy translation partner, whether that is through an agency or a translator on Fiverr. You need to be able to trust the translations provided, especially if you don’t understand the language being translated into. Google translate will not cut the mustard here!
Conclusion
If there was ever a time to get into the voice industry, it would be now. Both in its prime and infancy, as well as the big nine, are plowing billions into growing it and bringing voice assistants into everybody’s homes and daily routines.
Choosing which platform to use can be tricky, but based on what you intend to build, the platform to use should shine through or, failing that, utilize a third-party tool to hedge your bets and build on multiple platforms, especially if your skill is less complicated with fewer moving parts.
I, for one, am excited about the future of voice as it becomes ubiquitous; screen reliance will reduce and customers will be able to interact naturally with their assistant. But first, it’s up to us to build the skills that people will want from their assistant.
![]()
(dm, il)


Leave a Reply
Want to join the discussion?Feel free to contribute!