VSDC Free Video Editor Review – Everything You Need to Know
Original Source: https://inspiredm.com/vsdc-free-video-editor-review-everything-you-need-to-know/
Fact is- we all need video editing solutions from time to time. The most ideal type to use, however, is a different thing altogether.
You see, there has been an unending debate about paid and free video editors. While most people would overwhelmingly prefer free, it turns out that the real features are hoarded by the paid versions.
Think about it. Although you might be able to mention numerous free options, most of them pretty much end up being useless. They commonly provide very limited features, which are usually incapable of consistently generating decently edited videos.
And right when you assume that you’ve luckily stumbled on a different one with impressive features, you suddenly discover that you’re permanently stuck with watermarks and the likes. Then to make the situation worse, they probably also throw in a couple of annoying ads.
From limited trial periods to incomplete video outputs, you name it- I’ve tried it all out when it comes to free editors. And frankly, I’ve repeatedly given up on finding a solid one on many occasions.
So, I have to admit that I was not really excited about the VSDC Free Video Editor when I came across it. I thought it would end up being the same old tale with a different title. But surprisingly, things turned out contrary to my expectations…

VSDC Free Video Editor Review: Overview
Developed by Flash-Integro LLC, VSDC Free Video Editor is essentially a nonlinear video editing solution for video, audio, and images.
What does this mean?
Well, if you’ve tried out several standard video editors, you must have noticed the same old framework of placing media in a linear pattern for editing. But VSDC, on the other hand, uses a different non-linear approach. You’re allowed to set any combination or sequence as you work on your videos.
For instance, you can put videos directly opposite each other for a side-by-side outlook, or stack one over the other for a picture-in-picture setup. And that’s not all. There are numerous additional parameters you’re allowed to adjust- like media shape and position.

But, here’s the best thing about it. It’s completely free. The system will not lock you out after some time to force an upgrade.
Now, let’s be honest. We’ve seen numerous “free” video editing tools hiding behind that fact only to hit you with a caveat after installation. They usually paste ugly watermarks on your media output to market their brands. Or perhaps force you to install secondary apps they’ve partnered with.
Thankfully, VSDC free video editor doesn’t come with either. It doesn’t announce itself to the world with watermarks or introduce extra applications. You basically get what you see.
And speaking of which, it looks and feels like a genuinely professional tool. The interface is packed with a myriad of editing components that allow you to merge, split, cut, rotate, zoom, crop, and much more. You also get to do things like adding subtitles and shapes, hiding elements, blending, correcting colors, blurring, plus placing Instagram-like filters.

All these are possible on a wide array of video formats and codecs- including mainstream ones like AVI and MP4, plus unconventional versions like SWF and RM. The subsequent output options are also extensive, and you can even choose to produce a DVD video from its disc burner feature.
That said, VSDC is not only about free software. There’s an option of upgrading to a PRO version, which costs $19.99 per year.
But that would only be necessary if you need masking, subpixel accuracy, and video stabilization features, plus hardware acceleration to produce videos much faster. Our principal interest at the moment is the free version.
So, is VSDC free video editing software capable of living up to our expectations? How powerful are its features? And how does it even generate revenue if it’s actually free to use?
Well, let’s find out. This VSDC free video editor review covers all the critical matters- its features, editing tools, monetization model, plus its overall suitability.
VSDC Free Video Editor Review: Features
System Requirements
Admittedly, the biggest problem with video editors is the fact that they all require insanely extensive PC resources to run. You pretty much cannot edit a solid HD video without gaming rig-like PC components.
So, of course, I was extremely curious about the system requirements for VSDC free video editor. And it turns out that the minimum you need to run the software without issues is:
Microsoft DirectX 9.0c or later versions
50 MB disk space for installation
256 MB RAM
1024 × 768 pixels display with 16-bit color
Intel or AMD chipset with a clock rate of at least 1.5 GHz
Windows OS (XP SP3 or later versions)

Now hang on a minute. Does this mean you can edit videos on your old PC? Interestingly, yes- a standard PC can comfortably host and run this software. As a matter of fact, it only takes up 200MB of space in your local disk.
And when it comes operating systems, these are the supported ones:
Windows 10
Windows 8
Windows 7
Windows Vista
Windows XP SP3
Sadly, sorry Mac users. You might have to check later if they’ve released a compatible version. Let’s hope they ultimately do.
As for Windows users, let’s see how it actually performs on your PC…
User Friendliness
Once you run the application, you’ll notice that the primary interface is dark with clear labels on the tools. And to help you get the hang of it all, the system greets you with a pop-up that essentially walks you through the process of opening a new project, starting the editing stage, and exporting a project.

However, you don’t have to go through all that. I found the overall interface surprisingly simple and straightforward.
Starting a project, for instance, is as simple as choosing either screen capture, video capture, import content, create a slideshow, or blank project. You’ll see all these options from a projects tab that kicks in after the pop-up tutorial.
In case you need additional help, you can access the “Get To Know Top Feature” option at the bottom. It contains additional pointers about elements like:
3D pro charts
Multimedia combiner
Waveform
Chroma key
UHD and HD
Blending
Video effects
Now, let’s face it. It might take a beginner some time to get used to everything here. But, I guess that’s something we should expect on a software solution laden with such an array of tools. At least the learning curve is not as steep as we’ve seen with Adobe’s Premiere.
When it comes to the actual editing process, I admit that I haven’t experienced any issue so far. The progress has been smooth all along. However, it’s worth noting that the software’s overall performance depends on your PC’s hardware resources.
The rendering speed, for example, increases slightly as you upgrade the hardware components. It’s not the fastest we’ve seen, but it’s satisfyingly good for a free tool. Only Pro users get optimized speeds thanks to the hardware acceleration feature that VSDC unlocks after an upgrade.
Fortunately, that variation doesn’t affect the video quality at all. I was impressed that the VSDC free video editor can support both HD and UHD output resolutions. In fact, it can produce even H265/HEVC, which is a popular codec that compresses the file size without compromising the quality.

Editing Features
Video Capturing Tool
The video capturing tool connects VSDC with all cameras linked to your computer. You can shoot a video directly through IP cameras and webcams, then save or tweak them with the editor.
Screen Capturing Tool
The screen capturing tool comes in handy when you need to prepare solid video tutorials showing your PC display. It essentially prepares a footage of your activities on the computer monitor. You can then capitalize on the editor to adjust the resultant video accordingly.

DVD Burning Tool
Perhaps you’d like to catch up with your videos on a DVD player. Well, this is basically what you use.
The DVD burning tool allows you to save a DVD version of your video directly to a compatible disc in your PC’s optical drive.
Video Converter Tool
The video converter tool controls the conversion process, allowing you to transform a video file from one format to another. In addition to that, you can use it to merge clips into a single file, or split one into several videos.
Export Video to Social Networks
It goes without saying that YouTube is, by far, the biggest video directory on the web. So, of course, it makes sense to provide a tool that basically connects the app directly with YouTube to help you effortlessly upload a video immediately after editing.
Apart from that, you can also export and publish videos on Vimeo, Twitter, Instagram, and Facebook.
Create 3D Charts
VSDC free video editor goes beyond typical video editing to help users enhance their professional presentation videos. You can capitalize on the 3D charts feature to create a funnel, point, pyramid, scatter line, pie stacked bar, general bar, and much more- as part of your final video.
Blending Modes and Instagram-Like Filters
By now, you’ve probably tried out color blending on photos. Well, it turns out that you can also play around with this function as you edit your videos on VSDC. In fact, it also offers effects that are as powerful as Instagram filters- one click alone can adjust the temperature, contrast, or grayscale levels.
Supported Media Formats
The respective formats you can import to edit are:
Image Formats: PNG, BMP, GIF, JPEG, JPG, PSD, CUR, ICO
Audio Formats: MP3, RAM, AC3, CDA, WMA, FLAC, WAV, AIFF, AU, M4A, AAC, RA, CUE, OGG, VOC, MPA, WAV, APE
Video Formats: AVI, HDVideo/AVCHD (TOD, MOD, MTS, M2TS, TS), DVD/VOB, VCD/SVCD, QuickTime (MP4, MOV, 3GP, QT), MKV, Flash Video (FLV, SWF), MPEG, MJPEG, H.264/MPEG-4, XviD, AMV, MTV, Media Video (RM, RMVB), DV, NUT, Windows Media (DVR-MS, WMV, ASF)

Then after editing, you can export them as:
Image Formats: PNG, JPEG, BMP, GIF
Audio Formats: MP3, AAC, WAV, OGG, M4A, AMR
Video Formats: MP4, AVI, DVD, VCD/SVCD, MOV, 3GP, MKV, FLV, SWF, MTV, AMV, WMV, MV4, RM, RMVB
Overall Features
YouTube uploader
Export to social networking sites
Create videos for selected multimedia devices
Video file converter
Shoot videos directly from IP cameras, webcams, and video tuners
Capture PC screen video
Built-in DVD burning capability
Universal format support
4K and HD support
Create charts and diagrams
Color blending and Instagram-like filters
Visual and audio effects
Non-linear video editing
VSDC Pro Tools
Subpixel Accuracy
VSDC Pro employs subpixel accuracy when placing or positioning elements in a video scene. Consequently, the quality of the footage is preserved even after adjusting the angles, skewing, or introducing other visual effects.
Masking
The video editing process occasionally involves eliminating or hiding some objects like watermarks- and VSDC Pro provides a masking feature for precisely that. You can even blur faces to hide the identities of individuals in a video.
Video Stabilization Tool
Have you ever shot a video while moving only to end up with an annoyingly shaky clip? This is particularly common with drones and smartphones.
To help you rectify the problem, VSDC Pro provides a video stabilization tool. It pretty much eliminates the shaking frames to produce a much smoother footage.

Who Should Consider Using VSDC Free Video Editor?
Sadly, most of the free video editing software available on the web provide extremely basic features that would only be ideal for small beginner projects. VSDC Free Video Editor, however, is one of the few ones that provide the entire stack of features without substantial limitations. It’s pretty solid for a tool that won’t ask you to pay anything or embed watermarks on your videos.
That said, anyone can use this software- from beginners to established professionals in the graphic design space. However, I bet the bulk of its user-base is made of people who regularly post videos on social media. They would certainly appreciate a free editor that combines unlimited 4K video editing with social media uploaders.
So, how would you rate this one compared to other free video editors in the market?
header image courtesy of Lily
The post VSDC Free Video Editor Review – Everything You Need to Know appeared first on Inspired Magazine.










 Create Frames in Photoshop. (Large preview)
Create Frames in Photoshop. (Large preview)

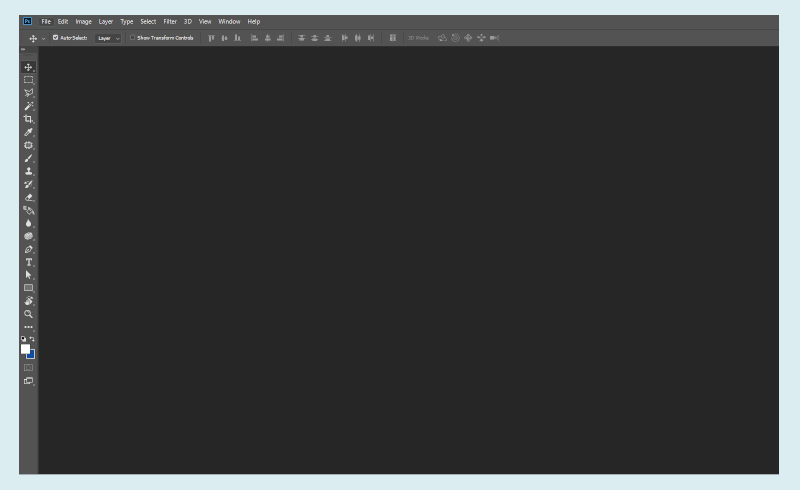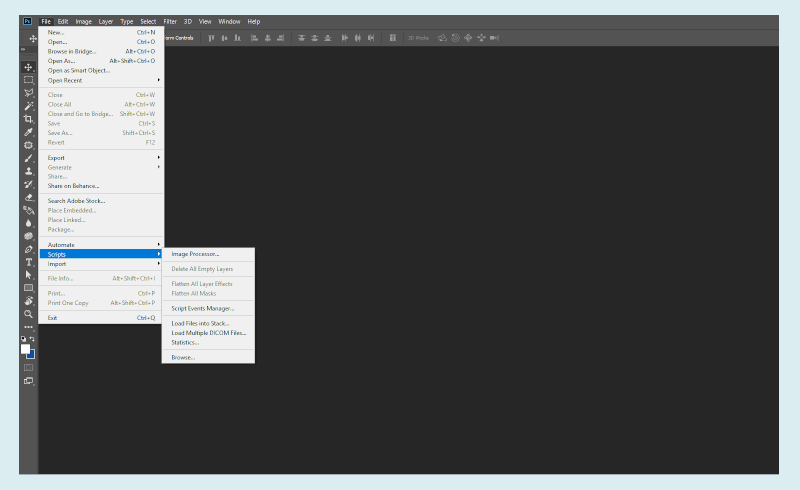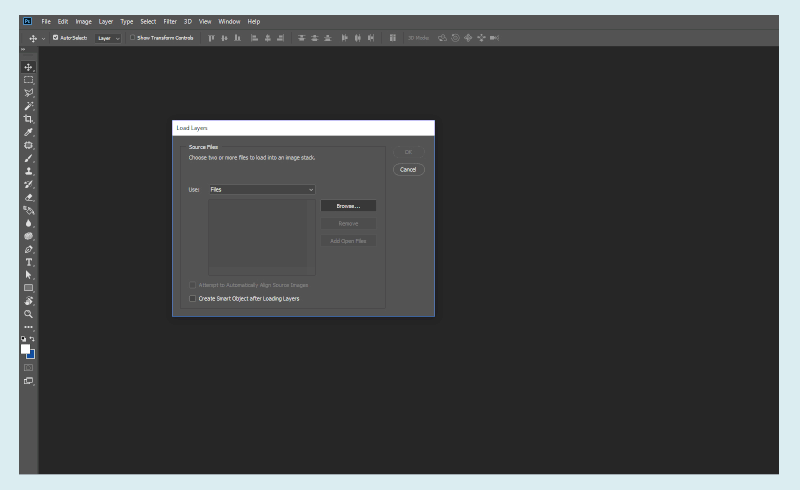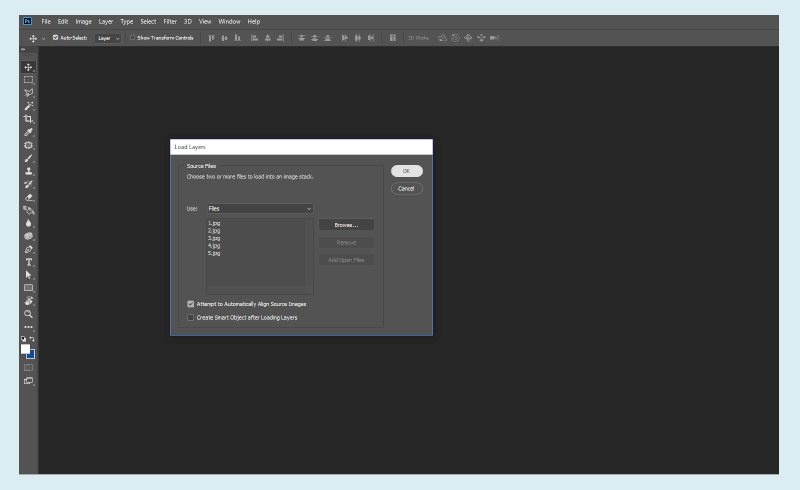 Load Files into Stack. (Large preview)
Load Files into Stack. (Large preview) Set the Frames. (Large preview)
Set the Frames. (Large preview)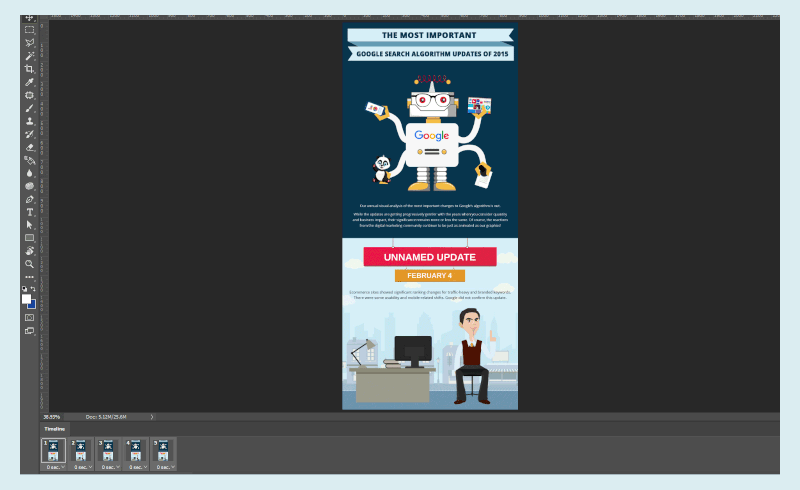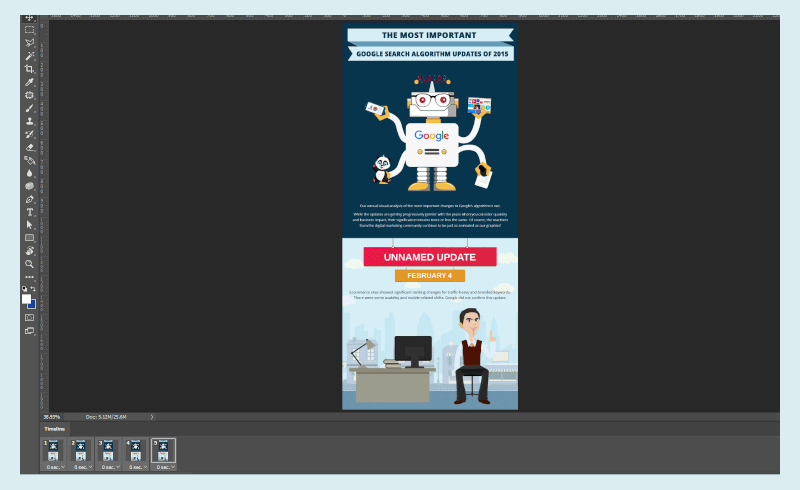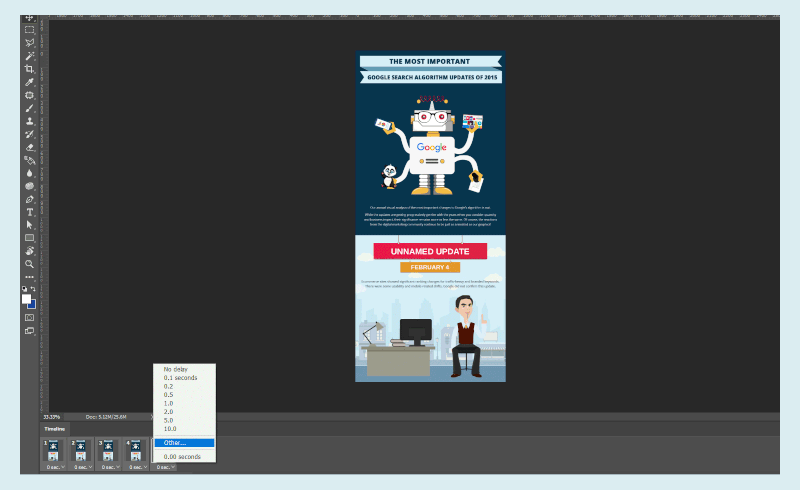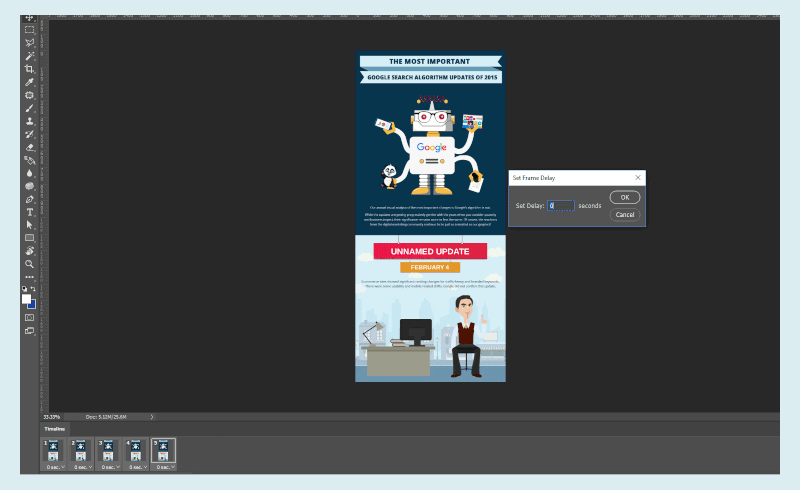 Set the Animation Speed. (Large preview)
Set the Animation Speed. (Large preview)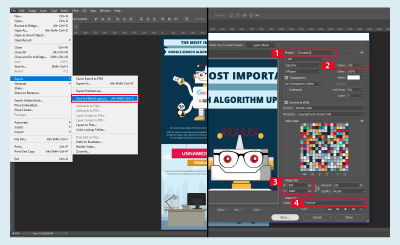

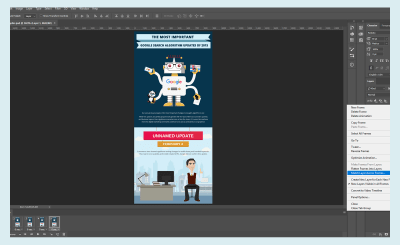


 Pantone’s annual quest to dominate the “and finally…” portion of the pre-festive news has kicked off, with the announcement of its Color of the Year for 2019.
Pantone’s annual quest to dominate the “and finally…” portion of the pre-festive news has kicked off, with the announcement of its Color of the Year for 2019.
 WordPess 5.0 (codenamed “Bebo”) is officially out and prowling among the servers.
WordPess 5.0 (codenamed “Bebo”) is officially out and prowling among the servers.