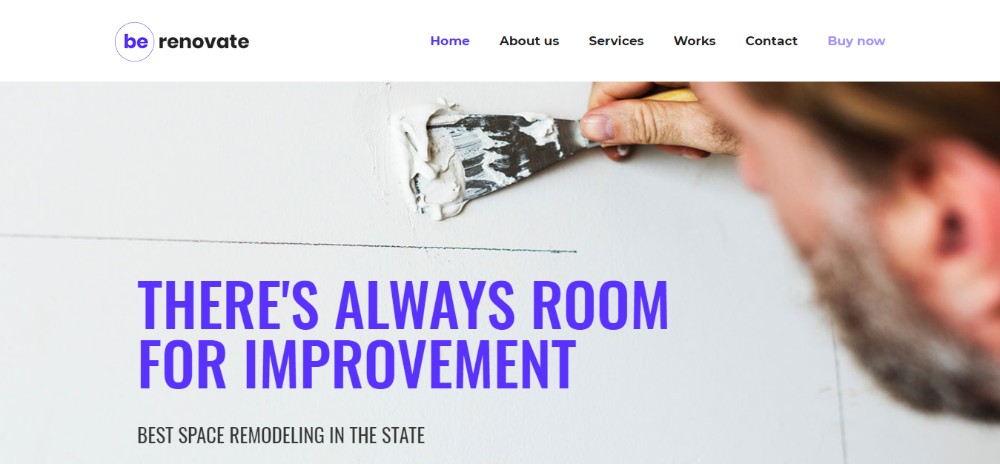
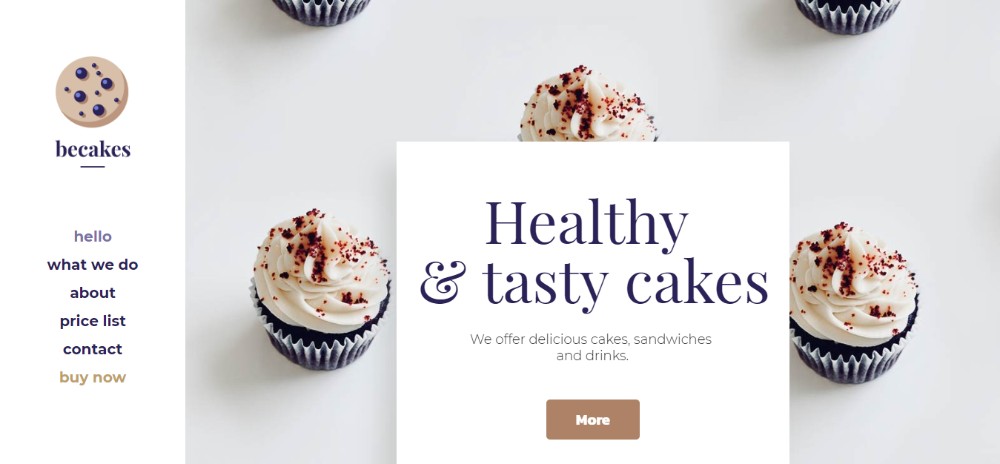
Original Source: https://inspiredm.com/ui-trends-that-will-shape-2019/
Allow me to ask you something that might sound a little bit like science-fiction. Has it ever occurred to you that maybe planet Earth has been moving a little bit faster of late – but we’re yet to notice? Seems like it was only yesterday that we reviewed what we expected as we moved into 2018. Yet strangely, it’s almost 2019 already!
Come to think of it, however, 2018 has been one heck of a year for UI design. Things are now much simpler compared to previous years- thanks to the exponential growth design tools have experienced in recent times. You don’t even have to be a coding guru anymore to create a professional-looking site with great UI in just a matter of minutes.
And that barely covers the base. Changes in user preferences have also extensively impacted how we’ve been designing interfaces in 2018.
To put it into perspective, 94% of internet users stopped trusting sites with poor design- so there’s simply no room for compromises anymore.
Then since scrolling is now widely accepted, sites are no longer prioritizing on placing the best stuff at the top. You can spread them proportionately within the interface. But then again, we’ve learned to be extremely careful about that considering 40% of the visitors will leave if the overall layout turns out to be shabby.
And that’s not all they hate. Users have also grown tired of content sliders- only 1% will click on them. Interestingly, mitigating that by eliminating content would also be a wrong move since 86% of site visitors want to see critical product and service info as soon as the land on the homepage.
Fascinating, right?
So, let’s be honest- UI design has never been this exciting. Users are morphing, device tech is developing astronomically, internet speed is now at Formula 1 level, and we’re backed by a wide range of design tools on the web. Combine all that with the modern UI designer skillsets, and you’ll certainly agree that 2019 is bound to be even more impactful.
So, what trends are we looking forward to?
Mobile First
Mobile optimization is a buzzword that is seemingly not retiring any time soon. The trend has been around for a couple of years now, to say the least. And you’d be right to predict that we’ll see increased adoption of mobile-based UI designs in 2019.
You might also assume that apart from the corresponding tech, there’s nothing new that might be forthcoming in this space- at least for the next 12 months or so. Fair enough, but get this…
You see, for quite some time now, we’ve been using the same old approach- designing for PC first, before shifting to mobile. Retrospectively, desktop UI was the principal focus because the bulk of the traffic came from PC users.
Then something interesting occurred in late 2016- mobile traffic ultimately surpassed PC traffic. By the end of that year, mobile phones had hit 50.31% of the market share, while tablets added up to 4.9%.

However, that notwithstanding, we still prioritized on the desktop interface because it so happened that PC users maintained the lead in the cumulative amount of time spent online. In North America, for instance, mobile phone surfing was still lagging behind in 2017, accounting for 33% of the surfing time.

Well, come to think of it, we all knew that it was only time before mobile ultimately caught up with PCs in this too. And by 2018, tables had completely turned, with mobile taking up 52.2% of all global web pages.

What does this mean for UI?
For starters, we expect a shift in UI design approach. Developers will start changing their priorities by focusing on mobile UI first before designing for PC. Mobile users will take precedence over PC users.
Use of Shadows and Depth
There’s no denying that flat UI designs have their benefits. But let’s face it. They’ve now become too monotonous and, admittedly, quite boring.
Unfortunately, using 3D designs was challenging because of the resultant cumbersome graphics. Loading a webpage with a 3D interface, for instance, typically took longer than one with a flat design.
Well, until web browsers started improving substantially. And designers, on the other hand, developed an exceptional technique of taking advantage of shadows to introduce the illusion of depth.

In 2019, therefore, we expect to see progressive use of shadow variations to achieve different 3D interface outlooks.
For example- designers seeking to draw attention to specific elements can create false shadows with varying degrees of softness and intensity. The end result is an element that might appear to hover over the rest in 3D.
Another popular technique is placing shadows in patterns to create various levels of textures, and subsequently bring the interface elements to life.
Then guess what? Recent advancements in UI design tools have further extended the dynamics that come with these design approaches. You can now easily combine shadows with grids and parallax layouts to systematically extend the corresponding depth, and consequently achieve more realistic 3D illusions.
In other words, advanced use of shadows will continue to achieve more refined depth on 2D display. And in so doing, eliminate the need for special 3D screens.
Minimalism
In the year 2000, the average human attention span, at least according to a study by Microsoft, was 12 seconds. Then guess what? By 2015, it had surprisingly dropped to 8 seconds- amusingly shorter than a standard goldfish.
Well, just when we thought it couldn’t possibly get any worse, the internet made people more impatient- 47% of your site visitors now expect your pages to load in less than 2 seconds. They simply can’t stand waiting for longer. As a matter of fact, 40% of them will leave if it takes longer than 3 seconds.
Surprisingly enough, many web designers haven’t been taking this seriously. The current average page loading speed is 8.66 seconds– despite Google’s recommendation of fewer than 3 seconds for 2018.

And that’s not all. It turns out the situation is considerably poorer for mobile sites since they take an average of 22 seconds to load. Yet, regrettably, 53% of mobile page visitors do not hang around for more than three seconds.
But, how does this relate to UI?
While page loading speeds are usually determined by several factors, the overall design of the user interface is particularly extremely critical. That’s where the chain reaction begins.
So, what does this mean for 2019?
Well, Google’s speed update in July 2018 was the beginning of the end of complex, graphics-heavy UIs that substantially compromise loading speeds. We are now increasingly shifting towards well-streamlined lean minimalistic UIs that load much faster.
In essence, minimalism entails achieving an ideal balance between simplicity, convenience, and functionality. This manages to not only improve overall speeds and search engine ranking but also decrease the corresponding traffic bounce rate.
Overlapping Effects
The modern era of graphical design introduced overlapping effects to combine multiple layers, create a sense of space, and most importantly, make interfaces more captivating.
But hold on. What is an overlapping effect in the first place?
Generally, this involves placing elements like images, text, and colors to stylishly overlap each other. I bet you’ve already come across overlapping graphics on several websites by now.

Well, admittedly, the design trend has been picking up considerably well over the past couple of years. But, with modern devices now coming with much better color gradient reproduction, it’s expected that 2019 will trigger extensive adoption of overlapping effects on both PC and mobile UIs.
Samsung Mobile, for example, switched from LCD displays to the much-advanced OLED technology when they released the Galaxy S7 two years ago. Then Apple joined the bandwagon with the iPhone X, which now has a greater display contrast than its LCD predecessors. The company even has plans of maintaining this on all iPhone models scheduled for 2019.
And who stands to benefit the most?
As expected, the graphical design world is exceedingly taking advantage of this to create overlaps with sharper, crispier gradients that look more natural. We love how OLED displays have substantially mitigated the biggest problem with overlapping elements- users getting distracted by the underlying secondary elements due to poor contrast.
This trend will also trigger the development of transparency in UI designs. We’ll see increased use of “glass-like” textures on UIs as designers capitalize on transparency to bring out both primary and secondary graphics simultaneously, without necessarily interfering with the intended emphasis.
Frameless Designs
And still on modern devices, you’ve certainly noticed the most outstanding thing about their overall exterior design nowadays. No, I’m not talking about how they are now overusing glass on pretty much every surface.
Ok, I admit it might have something to do with that. For some strange reason, everyone now seemingly hates display frames. Major smartphone and TV screen makers are gradually decreasing the space between the display outline and their corresponding device edges. Then to complete the look, they choose to combine that with rounded device edges.
Samsung has even gone ahead to eliminate edge frames altogether by extending some of their smartphone screens past the edges. Apple, on the other hand, has decided to cover the entire iPhone face with the display screen, leaving room for only the earpiece.

Come to think of it, I guess it has everything to do with the infinity illusion- the need to make the screen seem like a part of the natural environment. And, to be honest, it’s working quite well for users, who are reportedly finding the displays to be more immersive.
Perhaps unsurprisingly, this trend has spilled over to the app industry. The UIs are progressively shifting from framed outlines to smooth lines combined with rounded edges. Consequently, this has helped interfaces to seamlessly integrate with the device screens, and subsequently create a full-screen frameless outlook.
As device manufacturers continue this trend into 2019, we expect UIs to progressively drop the old generation sharp edges for smooth, rounded, frameless designs.
Micro-Animations
They are subtle and might seem insignificant at times. But, the simple truth is this- micro-animations in UIs have proven to be extremely powerful at engaging and helping users as they navigate.
Have you seen those buttons that change color when you scroll over or click on them? You’ve definitely also come across menu layouts that pop to display additional options as soon as the pointer lands on them. Well, they are all examples of micro-animations that create small visual effects to enrich user experience.

Since moving elements are particularly effectual at capturing attention, many designers are already leveraging them to drive users towards various conversion points. This trend is so prevalent by now that I’d be willing to bet a fortune that you can’t find more than five sites that haven’t yet implemented some form of micro-animations.
Then get this. All the dominant web browsers currently support micro-animations satisfyingly well on both PC and mobile. So I’d say that the trend is here to stay as we approach 2019- expect UIs to come with systematically structured visual hierarchies.
Conclusion
All in all, we’ve only covered some of the most notable trends. We’re bound to see more exciting stuff coming up as time goes by, and we can’t wait for 2019 to set the ball rolling.
That said, what exactly do you think might turn out to be the most impactful UI design trend? And what other notable trends would you add to this list?
header image courtesy of Walid Beno
The post UI Trends That Will Shape 2019 appeared first on Inspired Magazine.








 According to a recent QuickBooks survey, the #1 reason freelancers go into business for themselves is because it lends them the freedom to shape their own career path.
According to a recent QuickBooks survey, the #1 reason freelancers go into business for themselves is because it lends them the freedom to shape their own career path.