Original Source: https://smashingmagazine.com/2020/12/vuex-library/
Vuex is the solution for state management in Vue applications. The next version — Vuex 4 — is making its way through the final steps before officially releasing. This release will bring full compatibility with Vue 3, but doesn’t add new features. While Vuex has always been a powerful solution, and the first choice for many developers for state management in Vue, some developers had hoped to see more workflow issues addressed. However, even as Vuex 4 is just getting out the door, Kia King Ishii (a Vue core team member) is talking about his plans for Vuex 5, and I’m so excited by what I saw that I had to share it with you all. Note that Vuex 5 plans are not finalized, so some things may change before Vuex 5 is released, but if it ends up mostly similar to what you see in this article, it should be a big improvement to the developer experience.
With the advent of Vue 3 and it’s composition API, people have been looking into hand-built simple alternatives. For example, You Might Not Need Vuex demonstrates a relatively simple, yet flexible and robust pattern for using the composition API along with provide/inject to create shared state stores. As Gábor states in his article, though, this (and other alternatives) should only be used in smaller applications because they lack all those things that aren’t directly about the code: community support, documentation, conventions, good Nuxt integrations, and developer tools.
That last one has always been one of the biggest issues for me. The Vue devtools browser extension has always been an amazing tool for debugging and developing Vue apps, and losing the Vuex inspector with “time travel” would be a pretty big loss for debugging any non-trivial applications.
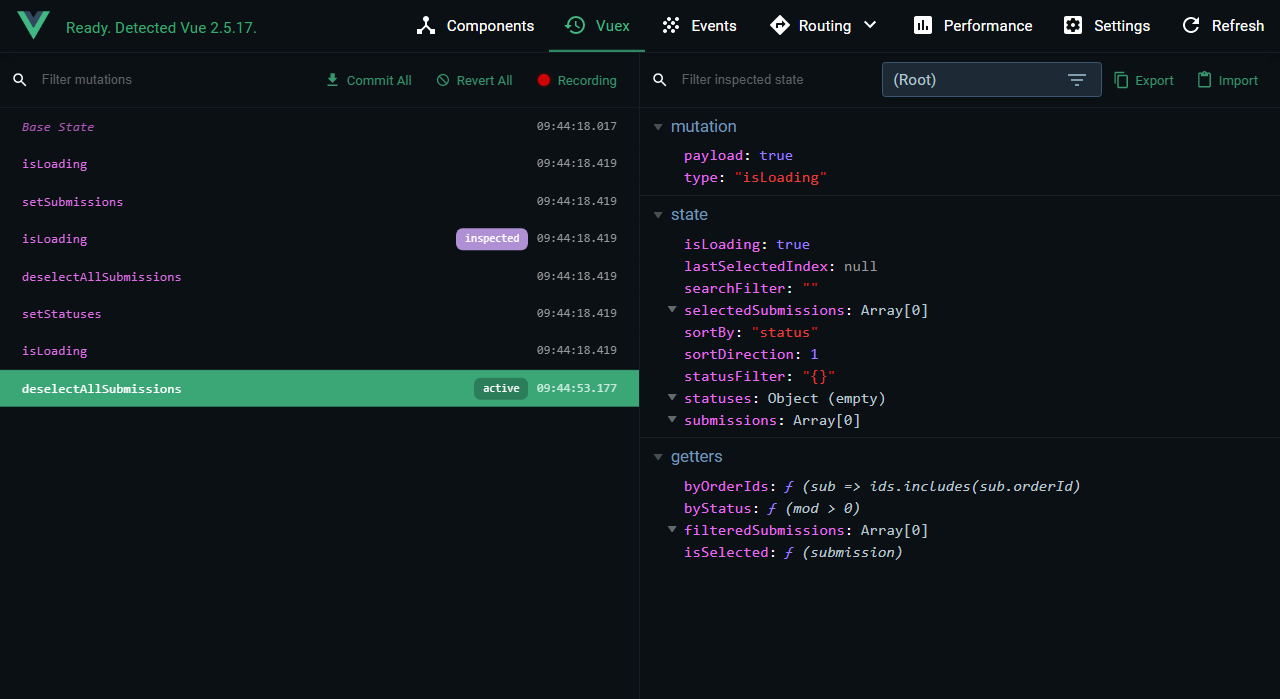
Thankfully, with Vuex 5 we’ll be able to have our cake and eat it too. It will work more like these composition API alternatives but keep all the benefits of using an official state management library. Now let’s take a look at what will be changing.
Defining A Store
Before we can do anything with a Vuex store, we need to define one. In Vuex 4, a store definition will look like this:
import { createStore } from ‘vuex’
export const counterStore = createStore({
state: {
count: 0
},
getters: {
double (state) {
return state.count * 2
}
},
mutations: {
increment (state) {
state.count++
}
},
actions: {
increment (context) {
context.commit(‘increment’)
}
}
})
Each store has four parts: state stores the data, getters give you computed state, mutations are used to mutate the state, and actions are the methods that are called from outside the store to accomplish anything related to the store. Usually, actions don’t just commit a mutation as this example shows. Instead, they are used to do asynchronous tasks because mutations must be synchronous or they just implement more complicated or multi-step functionality. Actions also cannot mutate the state on their own; they must use a mutator. So what does Vuex 5 look like?
import { defineStore } from ‘vuex’
export const counterStore = defineStore({
name: ‘counter’,
state() {
return { count: 0 }
},
getters: {
double () {
return this.count * 2
}
},
actions: {
increment () {
this.count++
}
}
})
There are a few changes to note here. First, instead of createStore, we use defineStore. This difference is negligible, but it’s there for semantic reasons, which we’ll go over later. Next, we need to provide a name for the store, which we didn’t need before. In the past, modules got their own name, but they weren’t provided by the module itself; they were just the property name they were assigned to by the parent store that added them. Now, there are no modules. Instead, each module will be a separate store and have a name. This name is used by the Vuex registry, which we’ll talk about later.
After that, we need to make state a function that returns the initial state instead of just setting it to the initial state. This is similar to the data option on components. We write getters very similar to the way we did in Vuex 4, but instead of using the state as a parameter for each getter, you can just use this to get to the state. In the same way, actions don’t need to worry about a context object being passed in: they can just use this to access everything. Finally, there are no mutations. Instead, mutations are combined with actions. Kia noted that too often, mutations just became simple setters, making them pointlessly verbose, so they removed them. He didn’t mention whether it was “ok” to mutate the state directly from outside the store, but we are definitely allowed and encouraged to mutate state directly from an action and the Flux pattern frowns on the direct mutation of state.
Note: For those who prefer the composition API over the options API for creating components, you’ll be happy to learn there is also a way to create stores in a similar fashion to using the composition API.
import { ref, computed } from ‘vue’
import { defineStore } from ‘vuex’
export const counterStore = defineStore(‘counter’, {
const count = ref(0)
const double = computed(() => count.value * 2)
function increment () {
count.value++
}
return { count, double, increment }
})
As shown above, the name gets passed in as the first argument for defineStore. The rest looks just like a composition function for components. This will yield exactly the same result as the previous example that used the options API.
Getting The Store Instantiated
In Vuex 4, things have changed from Vuex 3, but I’ll just look at v4 to keep things from getting out of hand. In v4, when you called createStore, you already instantiated it. You can then just use it in your app, either via app.use or directly:
import { createApp } from ‘vue’
import App from ‘./App.vue’ // Your root component
import store from ‘./store’ // The store definition from earlier
const app = createApp(App)
app.use(store)
app.mount(‘#app’)
// Now all your components can access it via `this.$store`
// Or you can use in composition components with `useStore()`
// ———————————————–
// Or use directly… this is generally discouraged
import store from ‘./store’
store.state.count // -> 0
store.commit(‘increment’)
store.dispatch(‘increment’)
store.getters.double // -> 4
This is one thing that Vuex 5 makes a bit more complicated than in v4. Each app now can get a separate instance of Vuex, which makes sure that each app can have separate instances of the same stores without sharing data between them. You can share an instance of Vuex if you want to share instances of stores between apps.
import { createApp } from ‘vue’
import { createVuex } from ‘vuex’
import App from ‘./App.vue’ // Your root component
const app = createApp(App)
const vuex = createVuex() // create instance of Vuex
app.use(vuex) // use the instance
app.mount(‘#app’)
Now all of your components have access to the Vuex instance. Instead of giving your store(s) definition directly, you then import them into the components you want to use them in and use the Vuex instance to instantiate and register them:
import { defineComponent } from ‘vue’
import store from ‘./store’
export default defineComponent({
name: ‘App’,
computed: {
counter () {
return this.$vuex.store(store)
}
}
})
Calling $vuex.store, instantiates and registers the store in the Vuex instance. From that point on, any time you use $vuex.store on that store, it’ll give you back the already instantiated store instead of instantiating it again. You can call the store method straight on an instance of Vuex created by createVuex().
Now your store is accessible on that component via this.counter. If you’re using the composition API for your component, you can use useStore instead of this.$vuex.store:
import { defineComponent } from ‘vue’
import { useStore } from ‘vuex’ // import useStore
import store from ‘./store’
export default defineComponent({
setup () {
const counter = useStore(store)
return { counter }
}
})
There are pros and cons to importing the store directly into the component and instantiating it there. It allows you to code split and lazily loads the store only where it’s needed, but now it’s a direct dependency instead of being injected by a parent (not to mention you need to import it every time you want to use it). If you want to use dependency injection to provide it throughout the app, especially if you know it’ll be used at the root of the app where code splitting won’t help, then you can just use provide:
import { createApp } from ‘vue’
import { createVuex } from ‘vuex’
import App from ‘./App.vue’
import store from ‘./store’
const app = createApp(App)
const vuex = createVuex()
app.use(vuex)
app.provide(‘store’, store) // provide the store to all components
app.mount(‘#app’)
And you can just inject it in any component where you’re going to use it:
import { defineComponent } from ‘vue’
export default defineComponent({
name: ‘App’,
inject: [‘store’]
})
// Or with Composition API
import { defineComponent, inject } from ‘vue’
export default defineComponent({
setup () {
const store = inject(‘store’)
return { store }
}
})
I’m not excited about this extra verbosity, but it is more explicit and more flexible, which I am a fan of. This type of code is generally written once right away at the beginning of the project and then it doesn’t bother you again, though now you’ll either need to provide each new store or import it every time you wish to use it, but importing or injecting code modules is how we generally have to work with anything else, so it’s just making Vuex work more along the lines of how people already tend to work.
Using A Store
Apart from being a fan of the flexibility and the new way of defining stores the same way as a component using the composition API, there’s one more thing that makes me more excited than everything else: how stores are used. Here’s what it looks like to use a store in Vuex 4.
store.state.count // Access State
store.getters.double // Access Getters
store.commit(‘increment’) // Mutate State
store.dispatch(‘increment’) // Run Actions
State, getters, mutations, and actions are all handled in different ways via different properties or methods. This has the advantage of explicitness, which I praised earlier, but this explicitness doesn’t really gain us anything. And this API only gets more difficult to use when you are using namespaced modules. By comparison, Vuex 5 looks to work exactly how you would normally hope:
store.count // Access State
store.double // Access Getters (transparent)
store.increment() // Run actions
// No Mutators
Everything — the state, getters and actions — is available directly at the root of the store, making it simple to use with a lot less verbosity and practically removes all need for using mapState, mapGetters, mapActions and mapMutations for the options API or for writing extra computed statements or simple functions for composition API. This simply makes a Vuex store look and act just like a normal store that you would build yourself, but it gets all the benefits of plugins, debugging tools, official documentation, etc.
Composing Stores
The final aspect of Vuex 5 we’ll look at today is composability. Vuex 5 doesn’t have namespaced modules that are all accessible from the single store. Each of those modules would be split into a completely separate store. That’s simple enough to deal with for components: they just import whichever stores they need and fire them up and use them. But what if one store wants to interact with another store? In v4, the namespacing convolutes the whole thing, so you need to use the namespace in your commit and dispatch calls, use rootGetters and rootState and then work your way up into the namespaces you want to access getters and state from. Here’s how it works in Vuex 5:
// store/greeter.js
import { defineStore } from ‘vuex’
export default defineStore({
name: ‘greeter’,
state () {
return { greeting: ‘Hello’ }
}
})
// store/counter.js
import { defineStore } from ‘vuex’
import greeterStore from ‘./greeter’ // Import the store you want to interact with
export default defineStore({
name: ‘counter’,
// Then use the store
use () {
return { greeter: greeterStore }
},
state () {
return { count: 0 }
},
getters: {
greetingCount () {
return `${this.greeter.greeting} ${this.count}’ // access it from this.greeter
}
}
})
With v5, we import the store we wish to use, then register it with use and now it’s accessible all over the store at whatever property name you gave it. Things are even simpler if you’re using the composition API variation of the store definition:
// store/counter.js
import { ref, computed } from ‘vue’
import { defineStore } from ‘vuex’
import greeterStore from ‘./greeter’ // Import the store you want to interact with
export default defineStore(‘counter’, ({use}) => { // use is passed in to function
const greeter = use(greeterStore) // use use and now you have full access
const count = 0
const greetingCount = computed(() => {
return ${greeter.greeting} ${this.count} // access it like any other variable
})
return { count, greetingCount }
})
No more namespaced modules. Each store is separate and is used separately. You can use use to make a store available inside another store to compose them. In both examples, use is basically just the same mechanism as vuex.store from earlier and they ensure that we instantiating the stores with the correct instance of Vuex.
TypeScript Support
For TypeScript users, one of the greatest aspects of Vuex 5 is that the simplification made it simpler to add types to everything. The layers of abstraction that older versions of Vuex had made it nearly impossible and right now, with Vuex 4, they increased our ability to use types, but there is still too much manual work to get a decent amount of type support, whereas in v5, you can put your types inline, just as you would hope and expect.
Conclusion
Vuex 5 looks to be almost exactly what I — and likely many others — hoped it would be, and I feel it can’t come soon enough. It simplifies most of Vuex, removing some of the mental overhead involved, and only gets more complicated or verbose where it adds flexibility. Leave comments below about what you think of these changes and what changes you might make instead or in addition. Or go straight to the source and add an RFC (Request for Comments) to the list to see what the core team thinks.
 · Manifesto and Footer Homepage
· Manifesto and Footer Homepage























 Animation is a fun and interesting way to bring life to a website. Used correctly, it can capture audience attention, make your website more engaging, and even improve your chances of delivering conversions for your clients.
Animation is a fun and interesting way to bring life to a website. Used correctly, it can capture audience attention, make your website more engaging, and even improve your chances of delivering conversions for your clients.