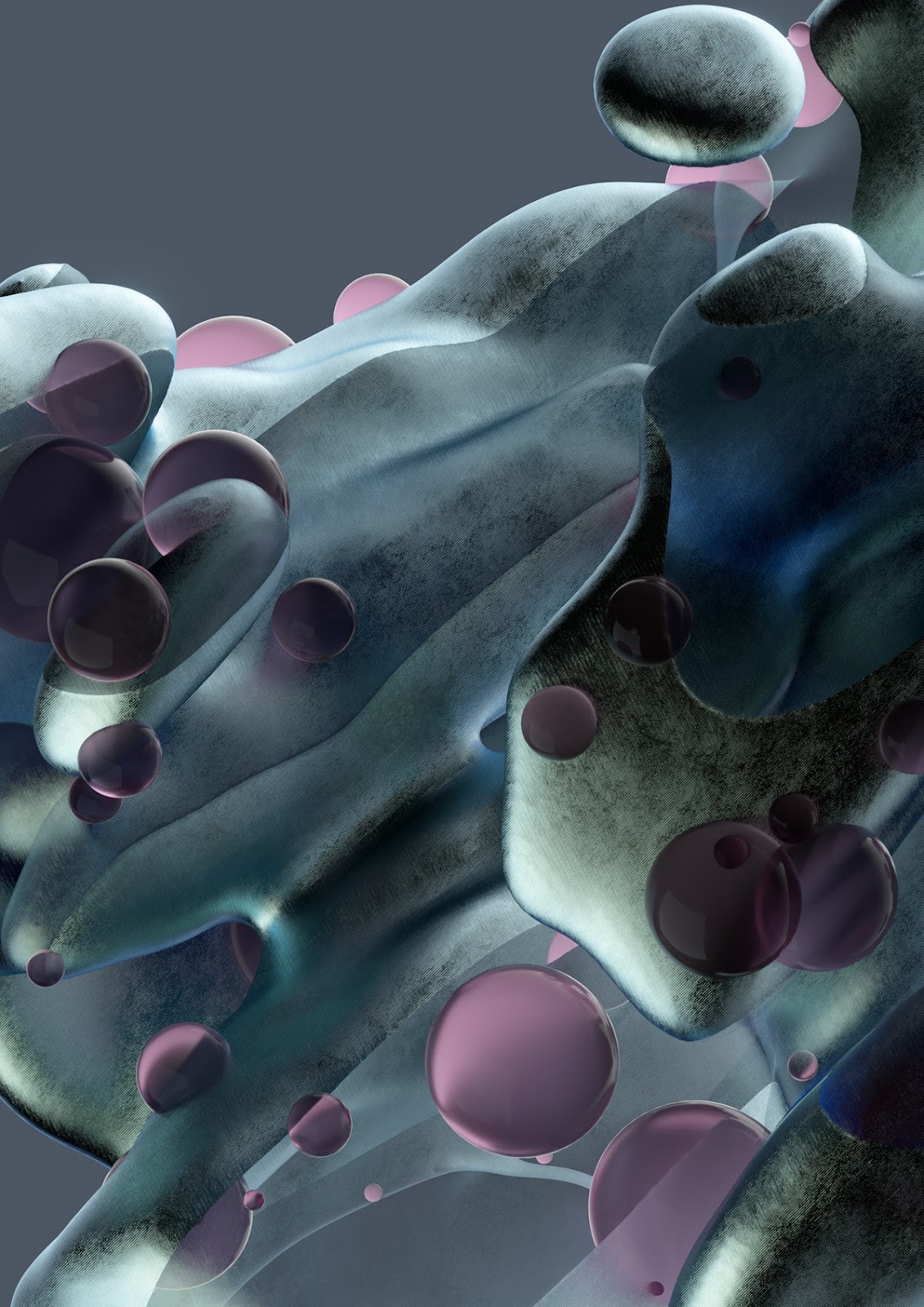
Original Source: http://feedproxy.google.com/~r/tympanus/~3/Z_OBz7OKRNA/
I love blobs and I enjoy looking for interesting ways to change basic geometries with Three.js: bending a plane, twisting a box, or exploring a torus (like in this 10-min video tutorial). So this time, my love for shaping things will be the excuse to see what we can do with a sphere, transforming it using shaders.
This tutorial will be brief, so we’ll skip the basic render/scene setup and focus on manipulating the sphere’s shape and colors, but if you want to know more about the setup check out these steps.
We’ll go with a more rounded than irregular shape, so the premise is to deform a sphere and use that same distortion to color it.
Vertex displacement
As you’ve probably been thinking, we’ll be using noise to deform the geometry by moving each vertex along the direction of its normal. Think of it as if we were pushing each vertex from the inside out with different strengths. I could elaborate more on this, but I rather point you to this article by The Spite aka Jaume Sanchez Elias, he explains this so well! I bet some of you have stumbled upon this article already.
So in code, it looks like this:
varying vec3 vNormal;
uniform float uTime;
uniform float uSpeed;
uniform float uNoiseDensity;
uniform float uNoiseStrength;
#pragma glslify: pnoise = require(glsl-noise/periodic/3d)
void main() {
float t = uTime * uSpeed;
// You can also use classic perlin noise or simplex noise,
// I’m using its periodic variant out of curiosity
float distortion = pnoise((normal + t), vec3(10.0) * uNoiseDensity) * uNoiseStrength;
// Disturb each vertex along the direction of its normal
vec3 pos = position + (normal * distortion);
vNormal = normal;
gl_Position = projectionMatrix * modelViewMatrix * vec4(pos, 1.0);
}
And now we should see a blobby sphere:
See the Pen
Vertex displacement by Mario (@marioecg)
on CodePen.
You can experiment and change its values to see how the blob changes. I know we’re going with a more subtle and rounded distortion, but feel free to go crazy with it; there are audio visualizers out there that deform a sphere to the point that you don’t even think it’s based on a sphere.
Now, this already looks interesting, but let’s add one more touch to it next.
Noitation
…is just a word I came up with to combine noise with rotation (ba dum tss), but yes! Adding some twirl to the mix makes things more compelling.
If you’ve ever played with Play-Doh as a child, you have surely molded a big chunk of clay into a ball, grab it with each hand, and twisted in opposite directions until the clay tore apart. This is kind of what we want to do (except for the breaking part).
To twist the sphere, we are going to generate a sine wave from top to bottom of the sphere. Then, we are going to use this top-bottom wave as a rotation for the current position. Since the values increase/decrease from top to bottom, the rotation is going to oscillate as well, creating a twist:
varying vec3 vNormal;
uniform float uTime;
uniform float uSpeed;
uniform float uNoiseDensity;
uniform float uNoiseStrength;
uniform float uFrequency;
uniform float uAmplitude;
#pragma glslify: pnoise = require(glsl-noise/periodic/3d)
#pragma glslify: rotateY = require(glsl-rotate/rotateY)
void main() {
float t = uTime * uSpeed;
// You can also use classic perlin noise or simplex noise,
// I’m using its periodic variant out of curiosity
float distortion = pnoise((normal + t), vec3(10.0) * uNoiseDensity) * uNoiseStrength;
// Disturb each vertex along the direction of its normal
vec3 pos = position + (normal * distortion);
// Create a sine wave from top to bottom of the sphere
// To increase the amount of waves, we’ll use uFrequency
// To make the waves bigger we’ll use uAmplitude
float angle = sin(uv.y * uFrequency + t) * uAmplitude;
pos = rotateY(pos, angle);
vNormal = normal;
gl_Position = projectionMatrix * modelViewMatrix * vec4(pos, 1.0);
}
Notice how the waves emerge from the top, it’s soothing. Some of you might find this movement therapeutic, so take some time to appreciate it and think about what we’ve learned so far…
See the Pen
Noitation by Mario (@marioecg)
on CodePen.
Alright! Now that you’re back let’s get on to the fragment shader.
Colorific
If you take a close look at the shaders before, you see, almost at the end, that we’ve been passing the normals to the fragment shader. Remember that we want to use the distortion to color the shape, so first let’s create a varying where we pass that distortion to:
varying float vDistort;
uniform float uTime;
uniform float uSpeed;
uniform float uNoiseDensity;
uniform float uNoiseStrength;
uniform float uFrequency;
uniform float uAmplitude;
#pragma glslify: pnoise = require(glsl-noise/periodic/3d)
#pragma glslify: rotateY = require(glsl-rotate/rotateY)
void main() {
float t = uTime * uSpeed;
// You can also use classic perlin noise or simplex noise,
// I’m using its periodic variant out of curiosity
float distortion = pnoise((normal + t), vec3(10.0) * uNoiseDensity) * uNoiseStrength;
// Disturb each vertex along the direction of its normal
vec3 pos = position + (normal * distortion);
// Create a sine wave from top to bottom of the sphere
// To increase the amount of waves, we’ll use uFrequency
// To make the waves bigger we’ll use uAmplitude
float angle = sin(uv.y * uFrequency + t) * uAmplitude;
pos = rotateY(pos, angle);
vDistort = distortion; // Train goes to the fragment shader! Tchu tchuuu
gl_Position = projectionMatrix * modelViewMatrix * vec4(pos, 1.0);
}
And use vDistort to color the pixels instead:
varying float vDistort;
uniform float uIntensity;
void main() {
float distort = vDistort * uIntensity;
vec3 color = vec3(distort);
gl_FragColor = vec4(color, 1.0);
}
We should get a kind of twisted, smokey black and white color like so:
See the Pen
Colorific by Mario (@marioecg)
on CodePen.
With this basis, we’ll take it a step further and use it in conjunction with one of my favorite color functions out there.
Cospalette
Cosine palette is a very useful function to create and control color with code based on the brightness, contrast, oscillation of cosine, and phase of cosine. I encourage you to watch Char Stiles explain this further, which is soooo good. Final s/o to Inigo Quilez who wrote an article about this function some years ago; for those of you who haven’t stumbled upon his genius work, please do. I would love to write more about him, but I’ll save that for a poem.
Let’s use cospalette to input the distortion and see how it looks:
varying vec2 vUv;
varying float vDistort;
uniform float uIntensity;
vec3 cosPalette(float t, vec3 a, vec3 b, vec3 c, vec3 d) {
return a + b * cos(6.28318 * (c * t + d));
}
void main() {
float distort = vDistort * uIntensity;
// These values are my fav combination,
// they remind me of Zach Lieberman’s work.
// You can find more combos in the examples from IQ:
// https://iquilezles.org/www/articles/palettes/palettes.htm
// Experiment with these!
vec3 brightness = vec3(0.5, 0.5, 0.5);
vec3 contrast = vec3(0.5, 0.5, 0.5);
vec3 oscilation = vec3(1.0, 1.0, 1.0);
vec3 phase = vec3(0.0, 0.1, 0.2);
// Pass the distortion as input of cospalette
vec3 color = cosPalette(distort, brightness, contrast, oscilation, phase);
gl_FragColor = vec4(color, 1.0);
}
¡Liiistoooooo! See how the color palette behaves similar to the distortion because we’re using it as input. Swap it for vUv.x or vUv.y to see different results of the palette, or even better, come up with your own input!
See the Pen
Cospalette by Mario (@marioecg)
on CodePen.
And that’s it! I hope this short tutorial gave you some ideas to apply to anything you’re creating or inspired you to make something. Next time you use noise, stop and think if you can do something extra to make it more interesting and make sure to save Cospalette in your shader toolbelt.
Explore and have fun with this! And don’t forget to share it with me on Twitter. If you got any questions or suggestions, let me know.
I hope you learned something new. Till next time!
References and Credits
Thanks to all the amazing people that put knowledge out in the world!
Simple color palettes by Inigo QuilezVertex displacement by The SpiteGLSL Shader Workshop by Char StilesGLSL Noise and GLSL RotateCreate a scene with Three.js
The post Twisted Colorful Spheres with Three.js appeared first on Codrops.

 The CMO at Twitter, Leslie Berland, has announced a substantial rebrand intended to reflect the experience of using the site. The move was announced on the platform first and later confirmed on its blog.
The CMO at Twitter, Leslie Berland, has announced a substantial rebrand intended to reflect the experience of using the site. The move was announced on the platform first and later confirmed on its blog.



















 Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.









 Here we are into a brand new year, and although we’re far from out of the woods yet, there is a feeling of renewed hope on many fronts.
Here we are into a brand new year, and although we’re far from out of the woods yet, there is a feeling of renewed hope on many fronts.















 It’s never been easier to set up an ecommerce store and start selling. There are a dizzying array of ecommerce solutions available in 2021, and most are feature-rich and competitively priced.
It’s never been easier to set up an ecommerce store and start selling. There are a dizzying array of ecommerce solutions available in 2021, and most are feature-rich and competitively priced.