Creating A Public/Private Multi-Monorepo For PHP Projects
Original Source: https://smashingmagazine.com/2021/08/public-private-multi-monorepo-php-projects/
To make the development experience faster, I moved all the PHP packages required by my projects to a monorepo. When each package is hosted on its own repo (the “multirepo” approach), it’d need be developed and tested on its own, and then published to Packagist before I could install it on other packages via Composer. With the monorepo, because all packages are hosted together, these can be developed, tested, versioned and released at the same time.
The monorepo hosting my PHP packages is public, accessible to anyone on GitHub. Git repos cannot grant different access to different assets, it’s all either public or private. As I plan to release a PRO WordPress plugin, I want its packages to be kept private, meaning they can’t be added to the public monorepo.
The solution I found is to use a “multi-monorepo” approach, comprising two monorepos: one public and one private, with the private monorepo embedding the public one as a Git submodule, allowing it to access its files. The public monorepo can be considered the “upstream”, and the private monorepo the “downstream”.

As my kept iterating on my code, the repo set-up I needed to use at each stage of my project also needed to be upgraded. Hence, I didn’t arrive at the multi-monorepo approach on day 1, but it was a process that spanned several years and took its fair amount of effort, going from a single repo, to multiple repos, to the monorepo, to finally the multi-monorepo.
In this article I will describe how I set-up my multi-monorepo using the Monorepo builder, which works for PHP projects based on Composer.
Reusing Code In The Multi-Monorepo
The public monorepo leoloso/PoP is where I keep all my PHP projects.
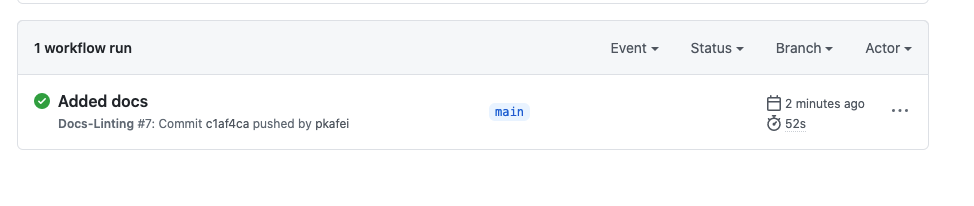
This monorepo contains workflow generate_plugins.yml, which generates multiple WordPress plugins for distribution when creating a new release on GitHub:
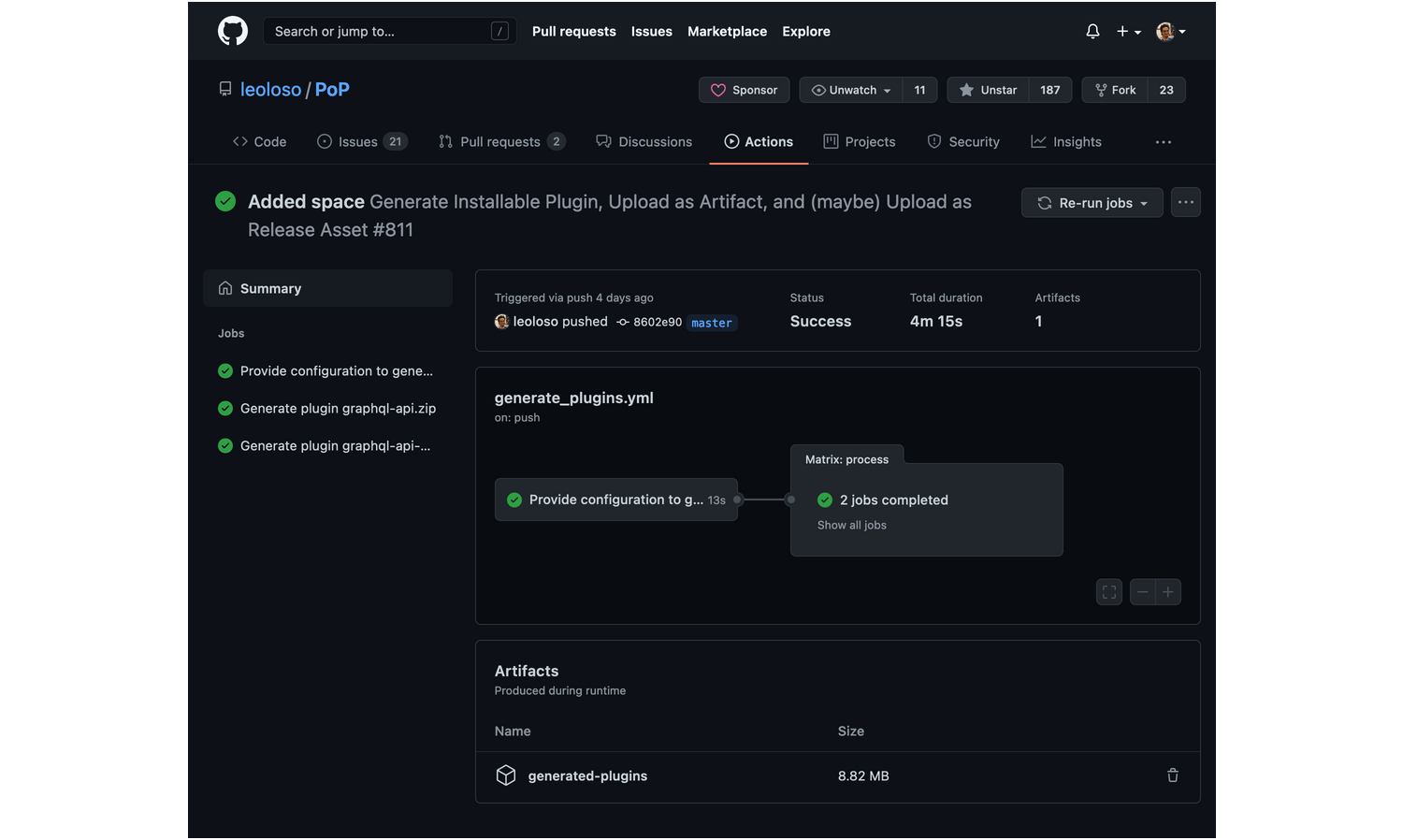
The workflow configuration is not hard-coded within the YAML but injected via PHP code:
– id: output_data
run: |
echo “::set-output name=plugin_config_entries::$(vendor/bin/monorepo-builder plugin-config-entries-json)”
And the configuration is provided via a custom PHP class:
class PluginDataSource
{
public function getPluginConfigEntries(): array
{
return [
// GraphQL API for WordPress
[
‘path’ => ‘layers/GraphQLAPIForWP/plugins/graphql-api-for-wp’,
‘zip_file’ => ‘graphql-api.zip’,
‘main_file’ => ‘graphql-api.php’,
‘dist_repo_organization’ => ‘GraphQLAPI’,
‘dist_repo_name’ => ‘graphql-api-for-wp-dist’,
],
// GraphQL API – Extension Demo
[
‘path’ => ‘layers/GraphQLAPIForWP/plugins/extension-demo’,
‘zip_file’ => ‘graphql-api-extension-demo.zip’,
‘main_file’ => ‘graphql-api-extension-demo.php’,
‘dist_repo_organization’ => ‘GraphQLAPI’,
‘dist_repo_name’ => ‘extension-demo-dist’,
],
];
}
}
Generating multiple WordPress plugins all together, and configuring the workflow via PHP, has reduced the amount of time needed managing the project. The workflow currently handles two plugins (the GraphQL API and its extension demo), but it could handle 200 without additional effort on my side.
It is this set-up that I want to reuse for my private monorepo leoloso/GraphQLAPI-PRO, so that the PRO plugins can also be generated without effort.
The code to reuse will comprise:
The GitHub Actions workflows to generate the WordPress plugins (including scoping, downgrading from PHP 8.0 to 7.1 and uploading to the releases page).
The custom PHP services to configure the workflows.
The private monorepo can then generate the PRO WordPress plugins, simply by triggering the workflows from the public monorepo, and overriding their configuration in PHP.
Linking Monorepos Via Git Submodules
To embed the public repo within the private one we use Git submodules:
git submodule add <public repo URL>
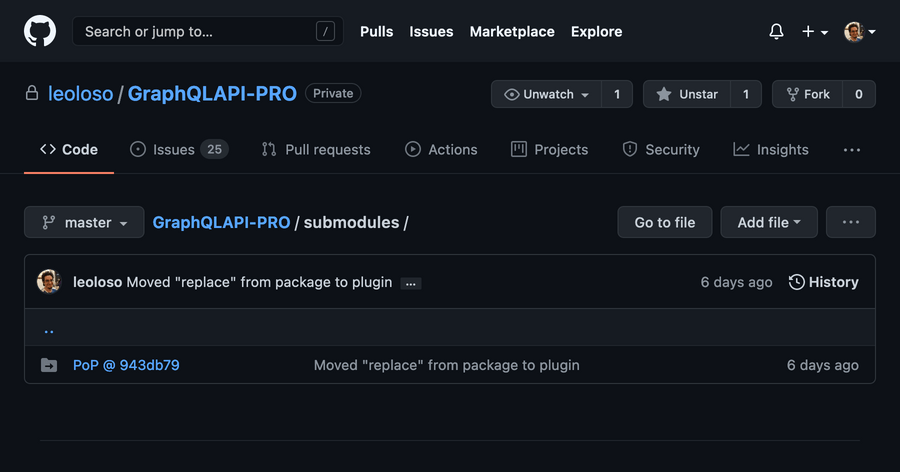
I embedded the public repo under subfolder submodules of the private monorepo, allowing me to add more upstream monorepos in the future if needed. In GitHub, the folder displays the submodule’s specific commit, and clicking on it will take me to that commit on leoloso/PoP:
Since it contains submodules, to clone the private repo we must provide the –recursive option:
git clone –recursive <private repo URL>
Reusing The GitHub Actions Workflows
GitHub Actions only loads workflows from under .github/workflows. Because the public workflows in the downstream monorepo are are under submodules/PoP/.github/workflows, these must be duplicated into the expected location.
In order to keep the upstream workflows as the single source of truth, we can limit ourselves to copying the files to downstream under .github/workflows, but never edit them there. If there is any change to be done, it must be done in the upstream monorepo, and then copied over.
As a side note, notice how this means that the multi-monorepo leaks: the upstream monorepo is not fully autonomous, and will need to be adapted to suit the downstream monorepo.
In my first iteration to copy the workflows, I created a simple Composer script:
{
“scripts”: {
“copy-workflows”: [
“php -r “copy(‘submodules/PoP/.github/workflows/generate_plugins.yml’, ‘.github/workflows/generate_plugins.yml’);””,
“php -r “copy(‘submodules/PoP/.github/workflows/split_monorepo.yaml’, ‘.github/workflows/split_monorepo.yaml’);””
]
}
}
Then, after editing the workflows in the upstream monorepo, I would copy them to downstream by executing:
composer copy-workflows
But then I realized that just copying the workflows is not enough: they must also be modified in the process. This is so because checking out the downstream monorepo requires option –recurse-submodules, as to also checkout the submodules.
In GitHub Actions, the checkout for downstream is done like this:
– uses: actions/checkout@v2
with:
submodules: recursive
So checking out the downstream repo needs input submodules: recursive, but the upstream one does not, and they both use the same source file.
The solution I found is to provide the value for input submodules via an environment variable CHECKOUT_SUBMODULES, which is by default empty for the upstream repo:
env:
CHECKOUT_SUBMODULES: “”
jobs:
provide_data:
steps:
– uses: actions/checkout@v2
with:
submodules: ${{ env.CHECKOUT_SUBMODULES }}
Then, when copying the workflows from upstream to downstream, the value of CHECKOUT_SUBMODULES is replaced with “recursive”:
env:
CHECKOUT_SUBMODULES: “recursive”
When modifying the workflow, it’s a good idea to use a regex, so that it works for different formats in the source file (such as CHECKOUT_SUBMODULES: “” or CHECKOUT_SUBMODULES:” or CHECKOUT_SUBMODULES:) as to not create bugs from this kind of assumed-to-be-harmless changes.
Then, the copy-workflows Composer script seen above is not good enough to handle this complexity.
In my next iteration, I created a PHP command CopyUpstreamMonorepoFilesCommand, to be executed via the Monorepo builder:
vendor/bin/monorepo-builder copy-upstream-monorepo-files
This command uses a custom service FileCopierSystem to copy all files from a source folder to the indicated destination, while optionally replacing their contents:
namespace PoPGraphQLAPIPROExtensionsSymplifyMonorepoBuilderSmartFile;
use NetteUtilsStrings;
use SymplifySmartFileSystemFinderSmartFinder;
use SymplifySmartFileSystemSmartFileSystem;
final class FileCopierSystem
{
public function __construct(
private SmartFileSystem $smartFileSystem,
private SmartFinder $smartFinder,
) {
}
/**
* @param array $patternReplacements a regex pattern to search, and its replacement
*/
public function copyFilesFromFolder(
string $fromFolder,
string $toFolder,
array $patternReplacements = []
): void {
$smartFileInfos = $this->smartFinder->find([$fromFolder], ‘*’);
foreach ($smartFileInfos as $smartFileInfo) {
$fromFile = $smartFileInfo->getRealPath();
$fileContent = $this->smartFileSystem->readFile($fromFile);
foreach ($patternReplacements as $pattern => $replacement) {
$fileContent = Strings::replace($fileContent, $pattern, $replacement);
}
$toFile = $toFolder . substr($fromFile, strlen($fromFolder));
$this->smartFileSystem->dumpFile($toFile, $fileContent);
}
}
}
When invoking this method to copy all workflows downstream, I also replace the value of CHECKOUT_SUBMODULES:
/**
* Copy all workflows to `.github/`, and convert:
* `CHECKOUT_SUBMODULES: “”`
* into:
* `CHECKOUT_SUBMODULES: “recursive”`
*/
$regexReplacements = [
‘#CHECKOUT_SUBMODULES:(s+”.*”)?#’ => ‘CHECKOUT_SUBMODULES: “recursive”‘,
];
(new FileCopierSystem())->copyFilesFromFolder(
‘submodules/PoP/.github/workflows’,
‘.github/workflows’,
$regexReplacements
);
Workflow generate_plugins.yml needs an additional replacement. When the WordPress plugin is generated, its code is downgraded from PHP 8.0 to 7.1 by invoking script ci/downgrade/downgrade_code.sh:
– name: Downgrade code for production (to PHP 7.1)
run: ci/downgrade/downgrade_code.sh “${{ matrix.pluginConfig.rector_downgrade_config }}” “” “${{ matrix.pluginConfig.path }}” “${{ matrix.pluginConfig.additional_rector_configs }}”
In the downstream monorepo, this file will be located under submodules/PoP/ci/downgrade/downgrade_code.sh. Then, we have the downstream workflow point to the right path with this replacement:
$regexReplacements = [
// …
‘#(ci/downgrade/downgrade_code.sh)#’ => ‘submodules/PoP/$1’,
];
Configuring Packages In Monorepo Builder
File monorepo-builder.php — placed at the root of the monorepo — holds the configuration for the Monorepo builder. In it we must indicate where the packages (and plugins, clients, or anything else) are located:
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
use SymplifyMonorepoBuilderValueObjectOption;
return static function (ContainerConfigurator $containerConfigurator): void {
$parameters = $containerConfigurator->parameters();
$parameters->set(Option::PACKAGE_DIRECTORIES, [
__DIR__ . ‘/packages’,
__DIR__ . ‘/plugins’,
]);
};
The private monorepo must have access to all code: its own packages, plus those from the public monorepo. Then, it must define all packages from both monorepos in the config file. The ones from the public monorepo are located under “/submodules/PoP”:
return static function (ContainerConfigurator $containerConfigurator): void {
$parameters = $containerConfigurator->parameters();
$parameters->set(Option::PACKAGE_DIRECTORIES, [
// public code
__DIR__ . ‘/submodules/PoP/packages’,
__DIR__ . ‘/submodules/PoP/plugins’,
// private code
__DIR__ . ‘/packages’,
__DIR__ . ‘/plugins’,
__DIR__ . ‘/clients’,
]);
};
As it can be seen, the configuration for upstream and downstream are pretty much the same, with the difference that the downstream one will:
Change the path to the public packages.
Add the private packages.
Then, it makes sense to rewrite the configuration using object-oriented programming, so that we make code DRY (don’t repeat yourself) by having a PHP class in the public repo be extended in the private repo.
Recreating The Configuration Via OOP
Let’s refactor the configuration. In the public repo, file monorepo-builder.php will simply reference a new class ContainerConfigurationService where all action will happen:
use PoPPoPConfigSymplifyMonorepoBuilderConfiguratorsContainerConfigurationService;
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
return static function (ContainerConfigurator $containerConfigurator): void {
$containerConfigurationService = new ContainerConfigurationService(
$containerConfigurator,
__DIR__
);
$containerConfigurationService->configureContainer();
};
The __DIR__ param points to the root of the monorepo. It will be needed to obtain the full path to the package directories.
Class ContainerConfigurationService is now in charge of producing the configuration:
namespace PoPPoPConfigSymplifyMonorepoBuilderConfigurators;
use PoPPoPConfigSymplifyMonorepoBuilderDataSourcesPackageOrganizationDataSource;
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
use SymplifyMonorepoBuilderValueObjectOption;
class ContainerConfigurationService
{
public function __construct(
protected ContainerConfigurator $containerConfigurator,
protected string $rootDirectory,
) {
}
public function configureContainer(): void
{
$parameters = $this->containerConfigurator->parameters();
if ($packageOrganizationConfig = $this->getPackageOrganizationDataSource($this->rootDirectory)) {
$parameters->set(
Option::PACKAGE_DIRECTORIES,
$packageOrganizationConfig->getPackageDirectories()
);
}
}
protected function getPackageOrganizationDataSource(): ?PackageOrganizationDataSource
{
return new PackageOrganizationDataSource($this->rootDirectory);
}
}
The configuration can be split across several classes. In this case, ContainerConfigurationService retrieves the package configuration through class PackageOrganizationDataSource, which has this implementation:
namespace PoPPoPConfigSymplifyMonorepoBuilderDataSources;
class PackageOrganizationDataSource
{
public function __construct(protected string $rootDir)
{
}
public function getPackageDirectories(): array
{
return array_map(
fn (string $packagePath) => $this->rootDir . ‘/’ . $packagePath,
$this->getRelativePackagePaths()
);
}
public function getRelativePackagePaths(): array
{
return [
‘packages’,
‘plugins’,
];
}
}
Overriding The Configuration In The Downstream Monorepo
Now that the configuration in the public monorepo is setup via OOP, we can extend it to suit the needs of the private monorepo.
In order to allow the private monorepo to autoload the PHP code from the public monorepo, we must first configure the downstream composer.json to reference the source code from the upstream, which is under path submodules/PoP/src:
{
“autoload”: {
“psr-4”: {
“PoP\GraphQLAPIPRO\”: “src”,
“PoP\PoP\”: “submodules/PoP/src”
}
}
}
Below is file monorepo-builder.php for the private monorepo. Notice that the referenced class ContainerConfigurationService in the upstream repo belongs to the PoPPoP namespace, but now it switched to the PoPGraphQLAPIPRO namespace. This class must receive the additional input $upstreamRelativeRootPath (with value “submodules/PoP”) as to recreate the full path to the public packages:
use PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderConfiguratorsContainerConfigurationService;
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
return static function (ContainerConfigurator $containerConfigurator): void {
$containerConfigurationService = new ContainerConfigurationService(
$containerConfigurator,
__DIR__,
‘submodules/PoP’
);
$containerConfigurationService->configureContainer();
};
The downstream class ContainerConfigurationService overrides which PackageOrganizationDataSource class is used in the configuration:
namespace PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderConfigurators;
use PoPPoPConfigSymplifyMonorepoBuilderConfiguratorsContainerConfigurationService as UpstreamContainerConfigurationService;
use PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderDataSourcesPackageOrganizationDataSource;
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
class ContainerConfigurationService extends UpstreamContainerConfigurationService
{
public function __construct(
ContainerConfigurator $containerConfigurator,
string $rootDirectory,
protected string $upstreamRelativeRootPath
) {
parent::__construct(
$containerConfigurator,
$rootDirectory
);
}
protected function getPackageOrganizationDataSource(): ?PackageOrganizationDataSource
{
return new PackageOrganizationDataSource(
$this->rootDirectory,
$this->upstreamRelativeRootPath
);
}
}
Finally, downstream class PackageOrganizationDataSource contains the full path to both public and private packages:
namespace PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderDataSources;
use PoPPoPConfigSymplifyMonorepoBuilderDataSourcesPackageOrganizationDataSource as UpstreamPackageOrganizationDataSource;
class PackageOrganizationDataSource extends UpstreamPackageOrganizationDataSource
{
public function __construct(
string $rootDir,
protected string $upstreamRelativeRootPath
) {
parent::__construct($rootDir);
}
public function getRelativePackagePaths(): array
{
return array_merge(
// Public packages – Prepend them with “submodules/PoP/”
array_map(
fn ($upstreamPackagePath) => $this->upstreamRelativeRootPath . ‘/’ . $upstreamPackagePath,
parent::getRelativePackagePaths()
),
// Private packages
[
‘packages’,
‘plugins’,
‘clients’,
]
);
}
}
Injecting The Configuration From PHP Into GitHub Actions
Monorepo builder offers command packages-json, which we can use to inject the package paths into the GitHub Actions workflow:
jobs:
provide_data:
steps:
– id: output_data
name: Calculate matrix for packages
run: |
echo “::set-output name=matrix::$(vendor/bin/monorepo-builder packages-json)”
outputs:
matrix: ${{ steps.output_data.outputs.matrix }}
This command produces a stringified JSON. In the workflow it must be converted to a JSON object via fromJson:
jobs:
split_monorepo:
needs: provide_data
strategy:
matrix:
package: ${{ fromJson(needs.provide_data.outputs.matrix) }}
Unfortunately, command packages-json outputs the package names but not their paths, which works when all packages are under the same folder (such as packages/). It doesn’t work in our case, since public and private packages are located in different folders.
Fortunately, the Monorepo builder can be extended with custom PHP services. So I created a custom command package-entries-json (via class PackageEntriesJsonCommand) which does output the path to the package.
The workflow was then updated with the new command:
run: |
echo “::set-output name=matrix::$(vendor/bin/monorepo-builder package-entries-json)”
Executed on the public monorepo, it produces the following packages (among many others):
[
{
“name”: “graphql-api-for-wp”,
“path”: “layers/GraphQLAPIForWP/plugins/graphql-api-for-wp”
},
{
“name”: “extension-demo”,
“path”: “layers/GraphQLAPIForWP/plugins/extension-demo”
},
{
“name”: “access-control”,
“path”: “layers/Engine/packages/access-control”
},
{
“name”: “api”,
“path”: “layers/API/packages/api”
},
{
“name”: “api-clients”,
“path”: “layers/API/packages/api-clients”
}
]
Executed on the private monorepo, it produces the following entries (among many others):
[
{
“name”: “graphql-api-for-wp”,
“path”: “submodules/PoP/layers/GraphQLAPIForWP/plugins/graphql-api-for-wp”
},
{
“name”: “extension-demo”,
“path”: “submodules/PoP/layers/GraphQLAPIForWP/plugins/extension-demo”
},
{
“name”: “access-control”,
“path”: “submodules/PoP/layers/Engine/packages/access-control”
},
{
“name”: “api”,
“path”: “submodules/PoP/layers/API/packages/api”
},
{
“name”: “api-clients”,
“path”: “submodules/PoP/layers/API/packages/api-clients”
},
{
“name”: “graphql-api-pro”,
“path”: “layers/GraphQLAPIForWP/plugins/graphql-api-pro”
},
{
“name”: “convert-case-directives”,
“path”: “layers/Schema/packages/convert-case-directives”
},
{
“name”: “export-directive”,
“path”: “layers/GraphQLByPoP/packages/export-directive”
}
]
As it can be appreciated, it works well: the configuration for the downstream monorepo contains both public and private packages, and the paths to the public ones were prepended with “submodules/PoP”.
Skipping Public Packages In The Downstream Monorepo
So far, the downstream monorepo has included both public and private packages in its configuration. However, not every command needs to be executed on the public packages.
Take static analysis, for instance. The public monorepo already executes PHPStan on all public packages via workflow phpstan.yml, as shown in this run. If the downstream monorepo runs once again PHPStan on the public packages, it is a waste of computing time. Then, the phpstan.yml workflow needs to run on the private packages only.
That means that depending on the command to execute in the downstream repo, we may want to either include both public and private packages, or only private ones.
To add public packages or not on the downstream configuration, we adapt downstream class PackageOrganizationDataSource to check this condition via input $includeUpstreamPackages:
namespace PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderDataSources;
use PoPPoPConfigSymplifyMonorepoBuilderDataSourcesPackageOrganizationDataSource as UpstreamPackageOrganizationDataSource;
class PackageOrganizationDataSource extends UpstreamPackageOrganizationDataSource
{
public function __construct(
string $rootDir,
protected string $upstreamRelativeRootPath,
protected bool $includeUpstreamPackages
) {
parent::__construct($rootDir);
}
public function getRelativePackagePaths(): array
{
return array_merge(
// Add the public packages?
$this->includeUpstreamPackages ?
// Public packages – Prepend them with “submodules/PoP/”
array_map(
fn ($upstreamPackagePath) => $this->upstreamRelativeRootPath . ‘/’ . $upstreamPackagePath,
parent::getRelativePackagePaths()
) : [],
// Private packages
[
‘packages’,
‘plugins’,
‘clients’,
]
);
}
}
Next, we need to provide value $includeUpstreamPackages as either true or false depending on the command to execute.
We can do this by replacing config file monorepo-builder.php with two other config files: monorepo-builder-with-upstream-packages.php (which passes $includeUpstreamPackages => true) and monorepo-builder-without-upstream-packages.php (which passes $includeUpstreamPackages => false):
// File monorepo-builder-without-upstream-packages.php
use PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderConfiguratorsContainerConfigurationService;
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
return static function (ContainerConfigurator $containerConfigurator): void {
$containerConfigurationService = new ContainerConfigurationService(
$containerConfigurator,
__DIR__,
‘submodules/PoP’,
false, // This is $includeUpstreamPackages
);
$containerConfigurationService->configureContainer();
};
We then update ContainerConfigurationService to receive parameter $includeUpstreamPackages and pass it along to PackageOrganizationDataSource:
namespace PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderConfigurators;
use PoPPoPConfigSymplifyMonorepoBuilderConfiguratorsContainerConfigurationService as UpstreamContainerConfigurationService;
use PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderDataSourcesPackageOrganizationDataSource;
use SymfonyComponentDependencyInjectionLoaderConfiguratorContainerConfigurator;
class ContainerConfigurationService extends UpstreamContainerConfigurationService
{
public function __construct(
ContainerConfigurator $containerConfigurator,
string $rootDirectory,
protected string $upstreamRelativeRootPath,
protected bool $includeUpstreamPackages,
) {
parent::__construct(
$containerConfigurator,
$rootDirectory,
);
}
protected function getPackageOrganizationDataSource(): ?PackageOrganizationDataSource
{
return new PackageOrganizationDataSource(
$this->rootDirectory,
$this->upstreamRelativeRootPath,
$this->includeUpstreamPackages,
);
}
}
Next, we should invoke the monorepo-builder with either config file, by providing the –config option:
jobs:
provide_data:
steps:
– id: output_data
name: Calculate matrix for packages
run: |
echo “::set-output name=matrix::$(vendor/bin/monorepo-builder package-entries-json –config=monorepo-builder-without-upstream-packages.php)”
However, as we saw earlier on, we want to keep the GitHub Actions workflows in the upstream monorepo as the single source of truth, and they clearly do not need these changes.
The solution I found to this issue is to provide a –config option in the upstream repo always, with each command getting its own config file, such as the validate command receiving the validate.php config file:
– name: Run validation
run: vendor/bin/monorepo-builder validate –config=config/monorepo-builder/validate.php
Now, there are no config files in the upstream monorepo, since it doesn’t need them. But it will not break, because the Monorepo builder checks if the config file exists and, if it does not, it loads the default config file instead. So we will either override the config, or nothing happens.
The downstream repo does provide the config files for each command, specifying if to add the upstream packages or not:
Btw, as a side note, this is another example of how the multi-monorepo leaks.
// File config/monorepo-builder/validate.php
return require_once __DIR__ . ‘/monorepo-builder-with-upstream-packages.php’;
Overriding The Configuration
We are almost done. By now the downstream monorepo can override the configuration from the upstream monorepo. So all that’s left to do is to provide the new configuration.
In class PluginDataSource I override the configuration of which WordPress plugins must be generated, providing the PRO ones instead:
namespace PoPGraphQLAPIPROConfigSymplifyMonorepoBuilderDataSources;
use PoPPoPConfigSymplifyMonorepoBuilderDataSourcesPluginDataSource as UpstreamPluginDataSource;
class PluginDataSource extends UpstreamPluginDataSource
{
public function getPluginConfigEntries(): array
{
return [
// GraphQL API PRO
[
‘path’ => ‘layers/GraphQLAPIForWP/plugins/graphql-api-pro’,
‘zip_file’ => ‘graphql-api-pro.zip’,
‘main_file’ => ‘graphql-api-pro.php’,
‘dist_repo_organization’ => ‘GraphQLAPI-PRO’,
‘dist_repo_name’ => ‘graphql-api-pro-dist’,
],
// GraphQL API Extensions
// Google Translate
[
‘path’ => ‘layers/GraphQLAPIForWP/plugins/google-translate’,
‘zip_file’ => ‘graphql-api-google-translate.zip’,
‘main_file’ => ‘graphql-api-google-translate.php’,
‘dist_repo_organization’ => ‘GraphQLAPI-PRO’,
‘dist_repo_name’ => ‘graphql-api-google-translate-dist’,
],
// Events Manager
[
‘path’ => ‘layers/GraphQLAPIForWP/plugins/events-manager’,
‘zip_file’ => ‘graphql-api-events-manager.zip’,
‘main_file’ => ‘graphql-api-events-manager.php’,
‘dist_repo_organization’ => ‘GraphQLAPI-PRO’,
‘dist_repo_name’ => ‘graphql-api-events-manager-dist’,
],
];
}
}
Creating a new release on GitHub will trigger the generate_plugins.yml workflow and generate the PRO plugins on my private monorepo:

Tadaaaaaaaa! ?
Conclusion
As always, there is no “best” solution, only solutions that may work better depending on the context. The multi-monorepo approach is not suitable to every kind of project or team. I believe the biggest beneficiaries are plugin creators who release public plugins to be upgraded to their PRO versions, and agencies customizing plugins for their clients.
In my case, I’m quite happy with this approach. It takes a bit of time and effort to get right, but it’s a one-off investment. Once the set-up is over, I can just focus on building my PRO plugins, and the time savings concerning project management can be huge.
 Often, when designing a website or branding, it is easy to get wrapped up in the details–typography, graphics, color, the grid–and lose the bigger picture. Of course, these things are vitally important, but they are building blocks that go together to form a greater whole.
Often, when designing a website or branding, it is easy to get wrapped up in the details–typography, graphics, color, the grid–and lose the bigger picture. Of course, these things are vitally important, but they are building blocks that go together to form a greater whole.