These wireless Bose headphones are now under $200
Original Source: https://www.creativebloq.com/news/bose-soundlink-2-deal
This $67 saving sounds unmissable.
Original Source: https://www.creativebloq.com/news/bose-soundlink-2-deal
This $67 saving sounds unmissable.
Original Source: https://www.creativebloq.com/buying-guides/best-monitor-with-webcam
These are the top monitors with webcams built in.
Original Source: https://www.sitepoint.com/wix-create-website/?utm_source=rss

Learn how to build a free website with Wix, a site builder that’s packed with features and designed for site owners of any experience level.
Continue reading
How to Create a Website with Wix
on SitePoint.
Original Source: https://www.webdesignerdepot.com/2022/07/20-best-new-websites-july-2022/
 Welcome to our guide to the best new websites this month. If subtle, minimal sites are your thing, either look away now or prepare to have your preconceptions challenged because this month, we are going maximalist.
Welcome to our guide to the best new websites this month. If subtle, minimal sites are your thing, either look away now or prepare to have your preconceptions challenged because this month, we are going maximalist.
Lots of elements fill up the screen, lots of color, lots of big fonts, lots of illustration, and plenty of in-your-face personality. This is a tricky style to get right: if elements are not chosen and placed well, the result is simply annoying clutter. If done well, the result can be impactful and memorable.
[And Happy Independence Day to all of our American readers!]
screenagers & the incredible machine
screenagers & the incredible machine’s site puts illustration front and center, creating a look that evokes various mystic ideas. It sounds strange, but it works.

Anna Jóna
This prelaunch teaser site for Anna Jóna café and cinema has an elegant yet modern feel.

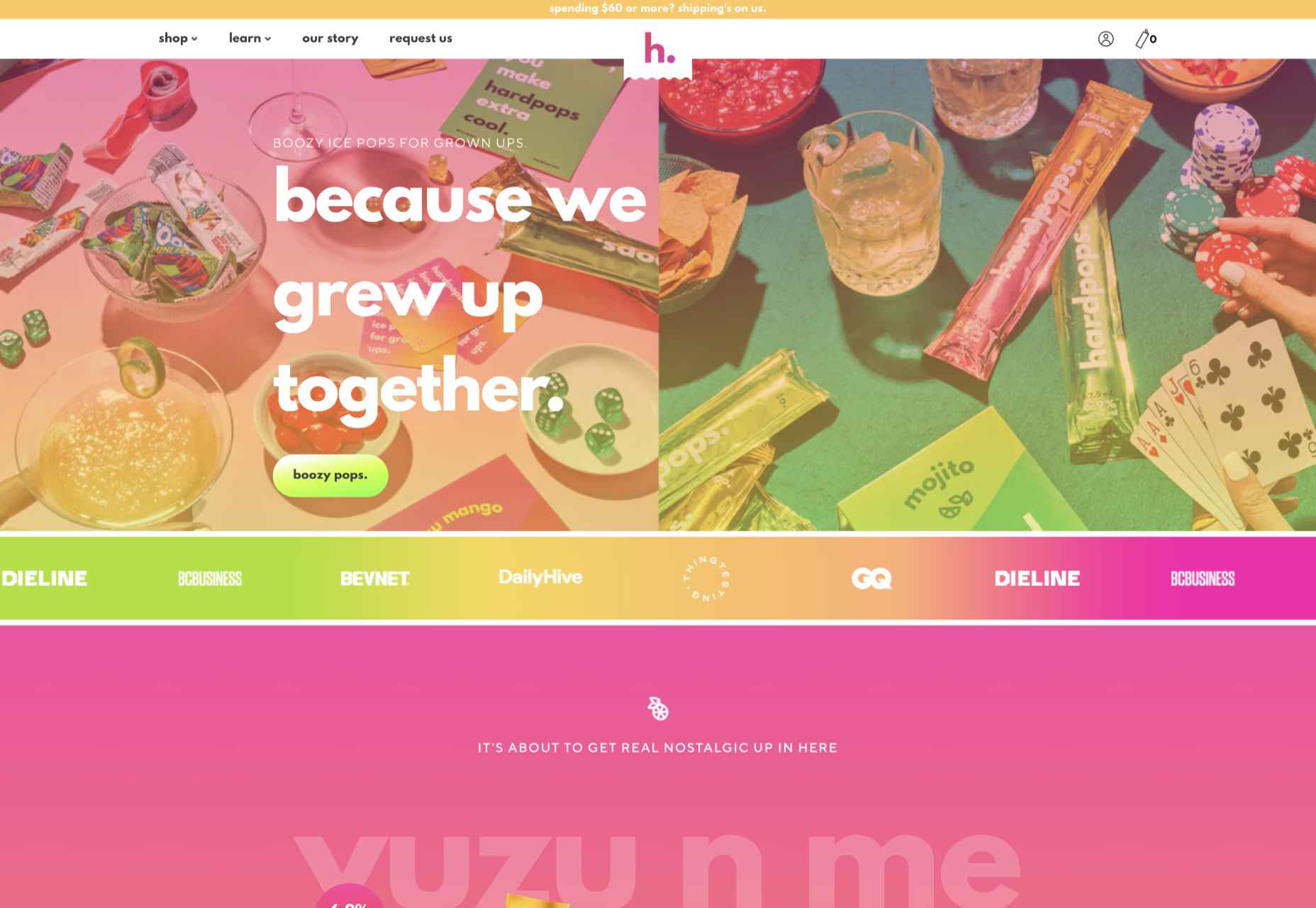
Hardpops
This site for Hardpops (alcoholic) ice pops takes its cue from the product flavors, and the bright, fruity colors give it a real zing.
Daniel Spatzek
Daniel Spatzek’s portfolio site takes the rules-are-made-to-be-broken approach. The result has attitude and a nice touch of humor.

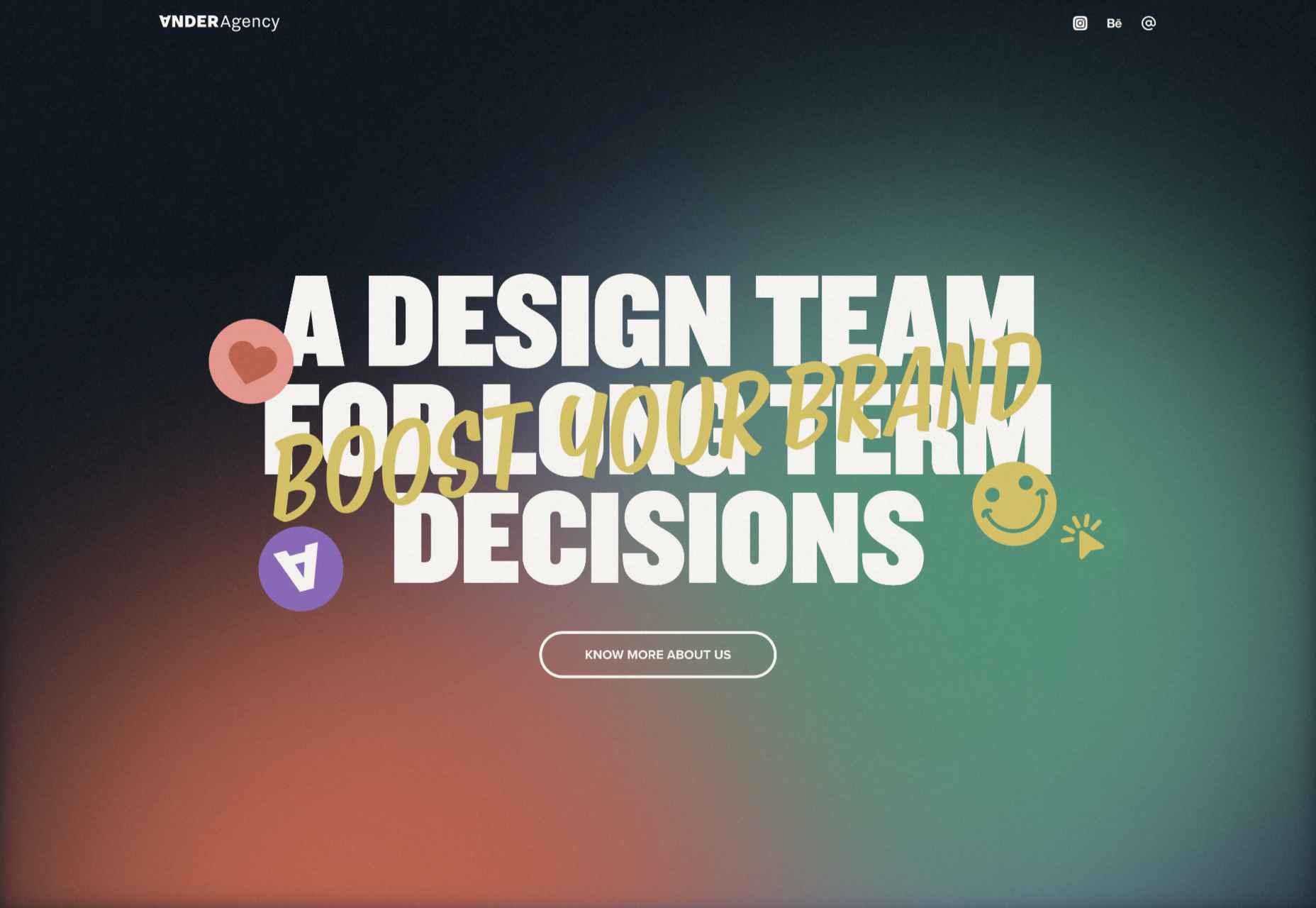
Ander Agency
Plenty of color, large type, and illustration make a bold statement for Ander Agency’s single-page site.
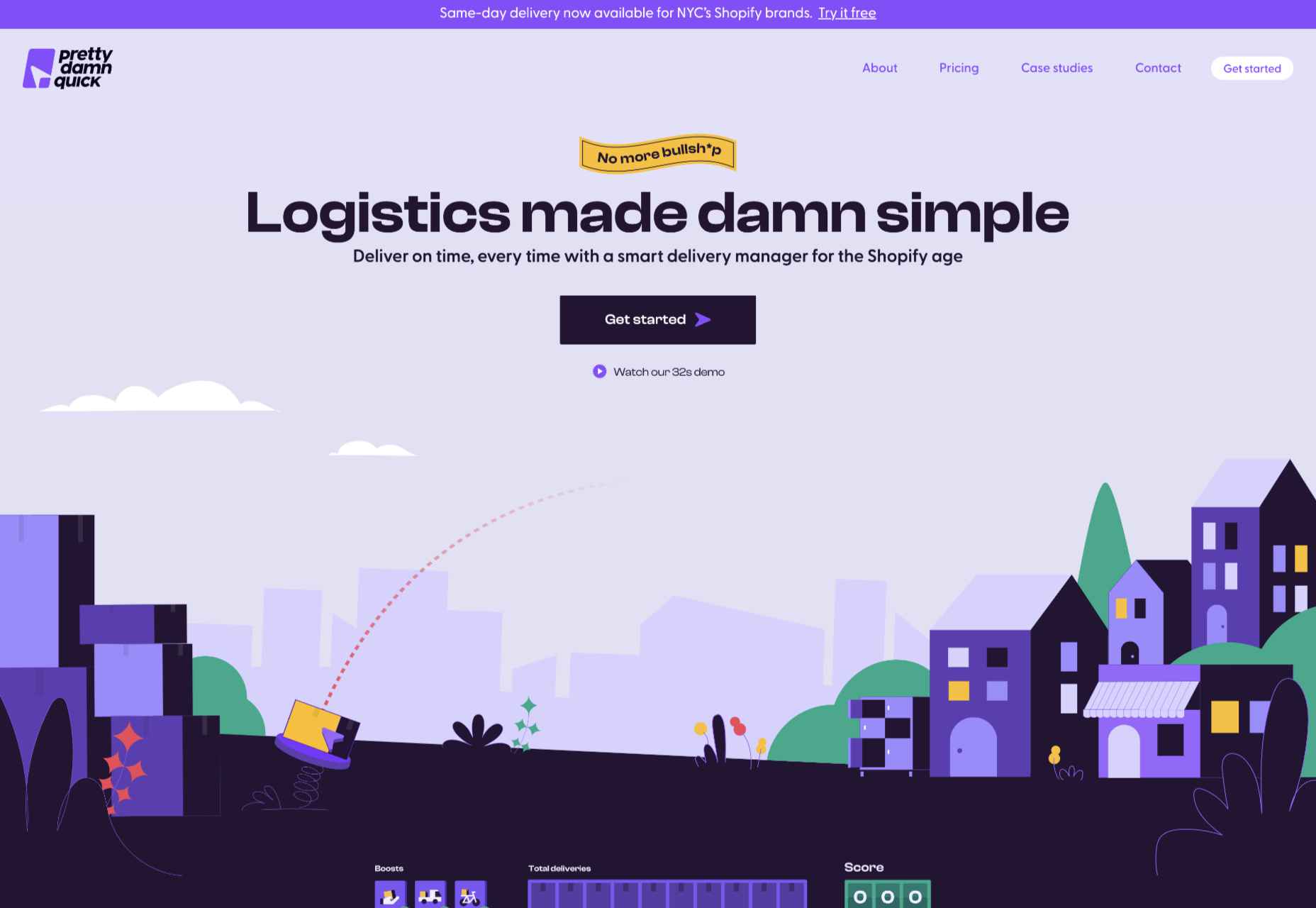
Pretty Damn Quick
Colorful illustration on this site for Pretty Damn Quick’s Shopify app creates an impression of friendliness about the company and ease of use of the product itself.
Know Your Beetle
Know Your Beetle is a showcase page for Kaploom creative studio. Color and type combinations make a big impact.

WTFFF
While many of the sites featured here have a sense of fun about them, WTFFF tackles a somber subject: online sexual abuse and harassment. Artwork and audio create an immersive experience in which five young people share their experiences with the aim of helping others.

BelArosa Chalet
Full-screen illustrations with a hint of vintage style create an ideal impression of what future guests can expect from the currently under construction BelArosa Chalet.

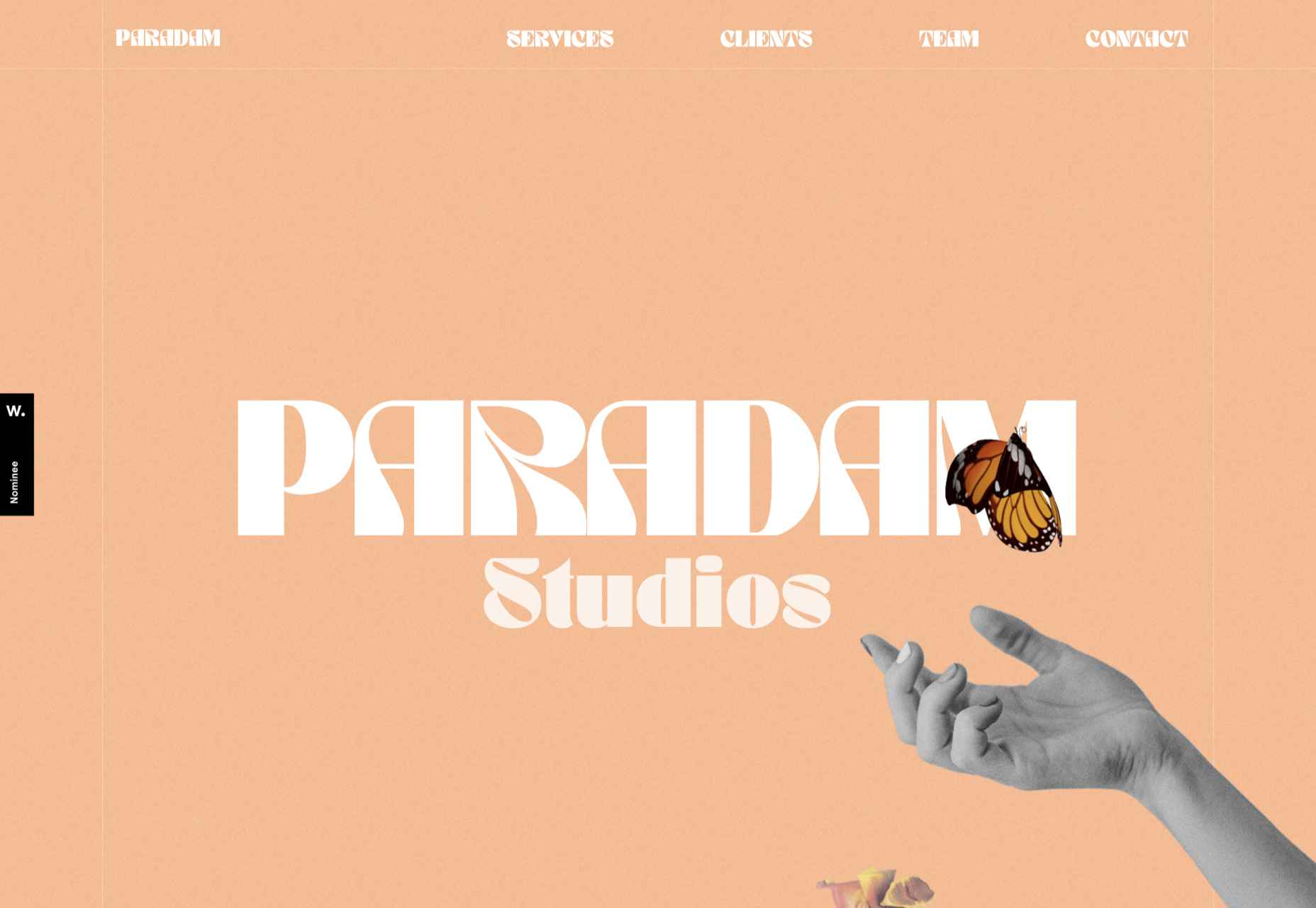
Paradam
The color scheme on the Paradam site is on the pastel end of the scale, but there is still lots going on to entrance the eye.
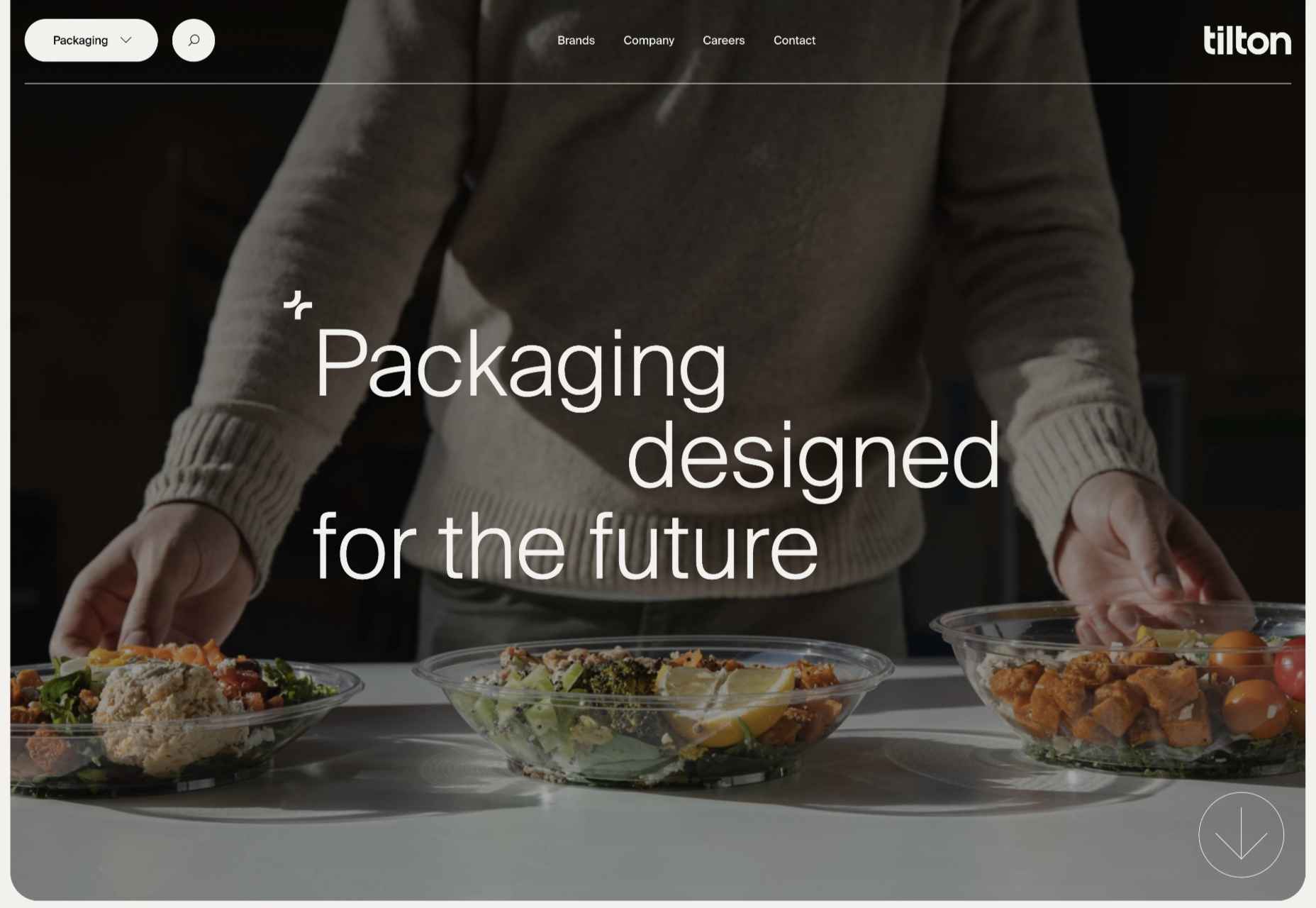
Tilton Group
The scrolling color panels on the Tilton Group site are a thing to behold.
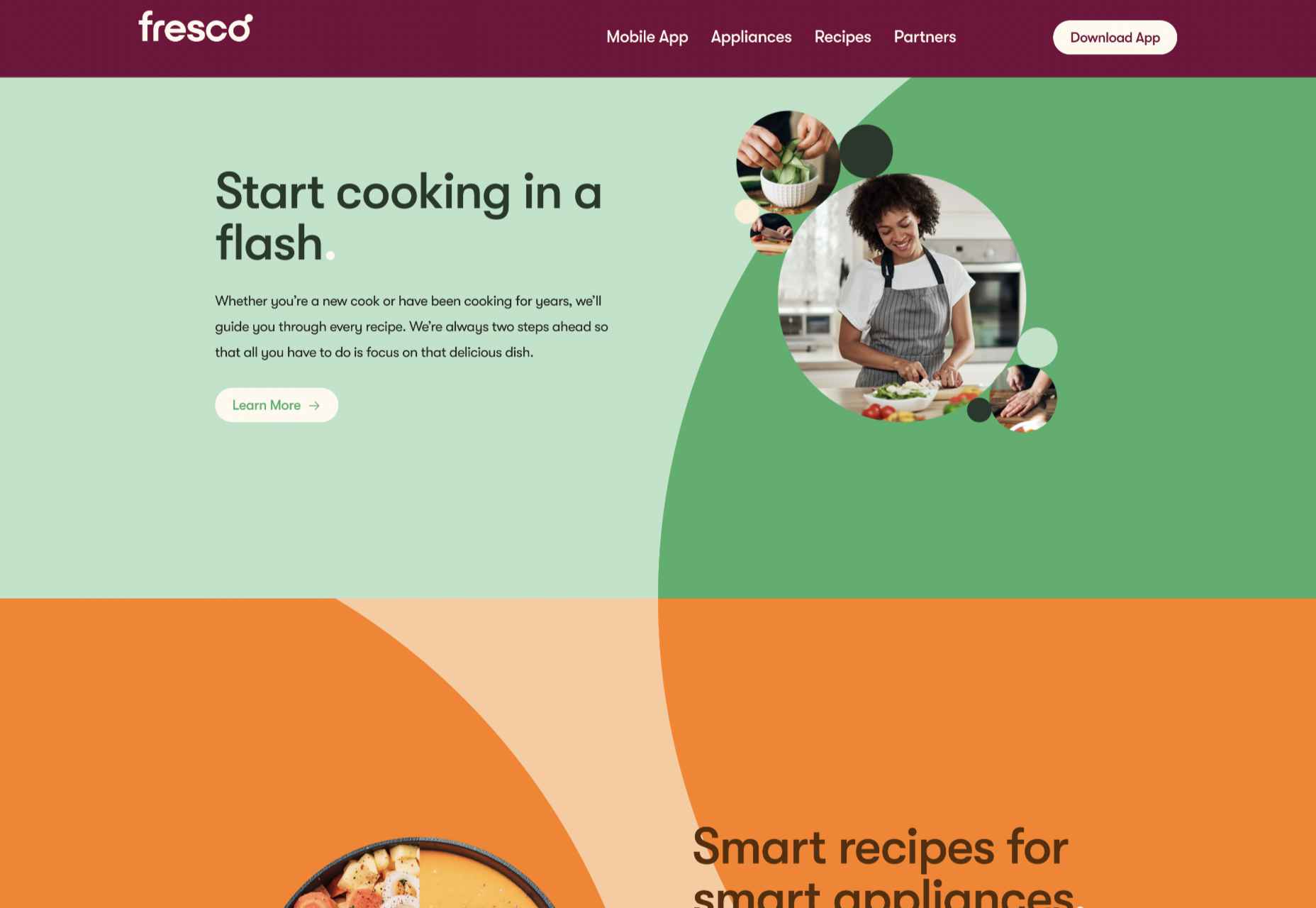
Fresco
Fresco uses a standard layout design, but the colors and quarter-circles instantly lift it.
Museum of Pink Art
Museum of Pink Art is an immersive experience celebrating the color pink. Undoubtedly worth a virtual wander around.

Icons by Menu
OK, this somewhat more minimalist site slipped through the net, but Icons by Menu is so pleasing to look at and use that we had to include it.

GlareDB
With an illustration that could be ideally at home on an Arthur C. Clarke book jacket and that rich, deep red background, this site for Glare DB is a world away from what might be expected.

Alex Beige
While the overall style and accent illustrations are pleasing on Alex Beige’s site, the Our Team section is guaranteed to raise a smile and stick in the user’s mind.

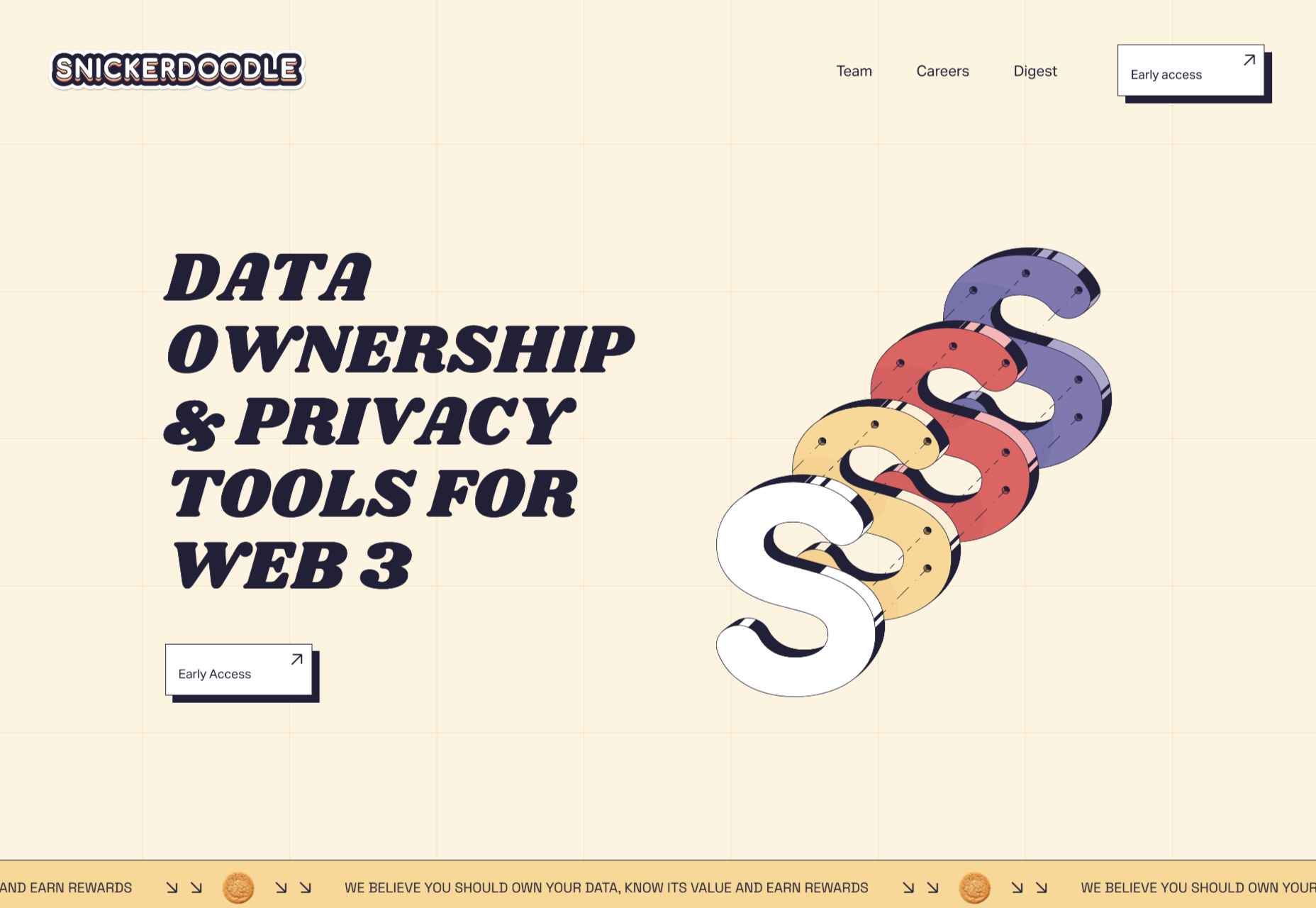
Snickerdoodle
Careful spacing means busy elements (like on scroll animated illustrations) don’t become overwhelming on the Snickerdoodle site.
Grisly’s Cosmic Black
The site for Grisly’s Cosmic Black is fun, bright, and joyful. Plus, it’s nice to see an alcohol site going a bit further than the usual ‘drink responsibly’ and actually providing helpful links.

The Perennial
Not just floorplans and (lots of) images, but virtual walkthroughs too. The Perennial doesn’t feel like a standard office building.

Source
p img {display:inline-block; margin-right:10px;}
.alignleft {float:left;}
p.showcase {clear:both;}
body#browserfriendly p, body#podcast p, div#emailbody p{margin:0;}
The post 20 Best New Websites, July 2022 first appeared on Webdesigner Depot.
Original Source: https://www.creativebloq.com/how-to/edit-videos
Learn how to spin raw footage into video gold.
Original Source: https://www.webdesignerdepot.com/2022/07/10-great-places-to-find-music-for-videos/
 Creating videos for social media or to embed on your site can be a fun and creative way to promote your brand or business. More importantly, time spent on a page is a significant SEO ranking factor, so providing a video to watch is of enormous benefit.
Creating videos for social media or to embed on your site can be a fun and creative way to promote your brand or business. More importantly, time spent on a page is a significant SEO ranking factor, so providing a video to watch is of enormous benefit.
However, coming up with the music for your videos can be challenging. You want something catchy that fits your video’s tone but don’t want to violate copyright laws.
Music licensing can be tricky, but if you’re smart about it and know what license your needs fall into, things will go swimmingly. Many different types of licenses cover differing budgets or use cases.
Public Domain: Public domain music is music that is not protected by copyright and can be used by anyone for any purpose. This includes traditional folk songs, classical music, and works released explicitly into the public domain.
Creative Commons: Creative Commons is a license that allows you to use someone else’s work for free, as long as you give credit to the creator. There are several Creative Commons licenses, so read the terms before using any music in your videos.
Royalty-Free: Royalty-free music is music you can use without paying royalties. This means you can use the music in your videos without getting permission from the artist or paying for a license. You can usually find royalty-free music on stock audio websites.
10 Places to Find Music for Videos
Below you’ll find the ten most common places to find music for your videos, including Youtube, Instagram, and TikTok videos.
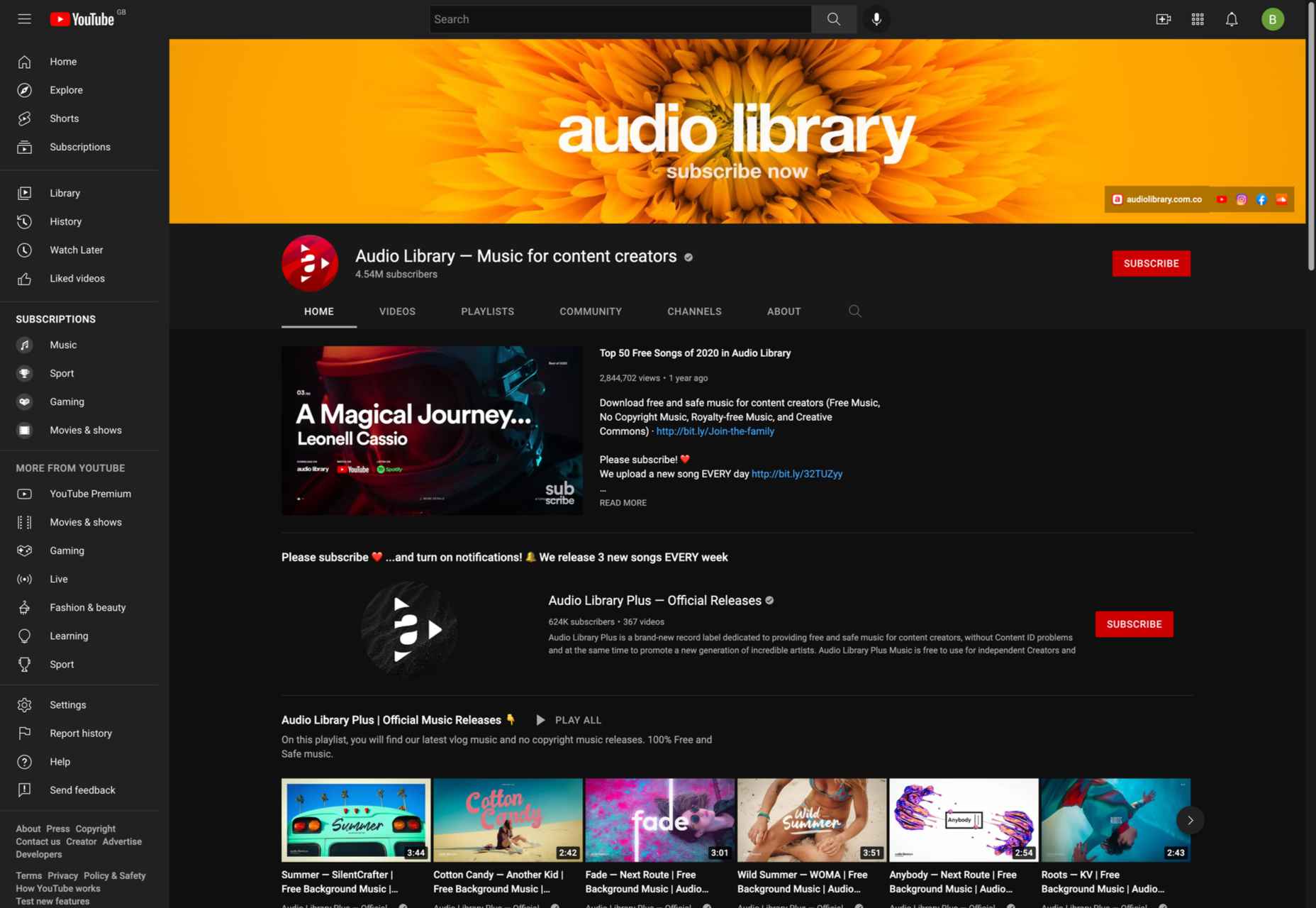
1. YouTube Audio Library
The first place to look for music is YouTube’s Audio Library. This is an excellent resource for finding free, high-quality music for your videos. You can search by genre, instrument, mood, or duration and preview the tracks before downloading them.
You can use music from the YouTube Audio Library in your Instagram and Youtube videos. Just make sure you follow the copyright guidelines specified on the YouTube website.
2. AudioJungle
AudioJungle from EnvatoMarket is an excellent resource for finding high-quality music for your videos. You can search by genre or mood and listen to previews of the songs before you download them.
AudioJungle offers a variety of paid plans that give you access to more features and higher-quality audio files. Prices start at $12 per month for the basic plan and go up to $48 per month for the premium plan.
3. Free Music Archive
The Free Music Archive is another resource to search for free music. It’s a little more eclectic than the YouTube Audio Library, so you’ll find a broader range of genres and styles here.
However, all of the music on the site is licensed under Creative Commons, so you’re free to use it in your videos. In addition, you can search by genre or artist and even listen to previews of the songs before you download them.
4. Incompetech
The next website to find royalty-free music for videos is Incompetech. You can search by genre, mood, or instrument, but also read about music licenses. Besides, the site has a handy “music for video” section that features tracks that are specifically designed for use in videos.
Incompetech is free for users, but the company still earns money on display ads and Patreon donations.
5. Bensound
Bensound is a website where you can find high-quality music for your social media videos. It has a library of music that you can choose from, and you can also create custom playlists. The site is easy to use, and you can search for music by genre, mood, or artist.
All of the music on the site is licensed under Creative Commons, so you’re free to use it in your videos. Prices start from approximately $12/mo subscription, or you can pay $34 per track.
6. ccMixter
ccMixter was created as a Creative Commons Project. It is a collaboration platform for musicians who want to promote their work. The site also has a handy “music for video” section that features tracks that are specifically designed for use in videos.
ccMixter offers a variety of paid plans that give you access to more features and higher-quality audio files. Prices start at $12 per month for the basic plan and go up to $48 per month for the premium plan.
7. Epidemic Sound
Epidemic Sound is a music company with a rich history dating back to 2009. They provide high-quality music for social media videos, and their library is constantly expanding. Epidemic Sound was founded by three friends working in the music industry. They were frustrated with the quality of stock music available, so they decided to create their own.
Epidemic Sound has since become a go-to source for high-quality music. In recent years, the company has been working hard to expand its library and make it easier for people to find the perfect song for their videos. As a result, they now have over 30,000 tracks available.
Epidemic Sound’s monthly subscription service starts at $15/month. This gives you access to all of the site’s music, and you can download as many tracks as you want.
8. Musopen
Musopen is a perfect website for finding classical music for your videos. The site has various tracks to choose from; you can filter them by composer, orchestra, period, mood, length, and more. In addition, all of the music on the site is licensed under Creative Commons, so you’re free to use it in your videos.
Musopen offers a subscription plan that gives you access to high-quality music for your social media videos. You can choose from three different pricing plans, and each plan comes with a different number of downloads per month.
9. Jamendo Music
Jamendo is a website where you can find royalty-free music for your social media videos. The music on the website ranges from rock to electronica, and there is something for everyone.
You can either browse the music by genre or use the search function to find the perfect song for your video.
10. StoryBlocks
StoryBlocks is a website created by two brothers, Aaron and Evan Sharp. It has a royalty-free music library with various music genres to choose from. You can find everything from pop to classical on this website.
There is also a section of the website devoted to social media-friendly tracks. This means you can find music perfect for your videos without worrying about copyright issues.
Featured image via Unsplash.
Source
p img {display:inline-block; margin-right:10px;}
.alignleft {float:left;}
p.showcase {clear:both;}
body#browserfriendly p, body#podcast p, div#emailbody p{margin:0;}
The post 10 Great Places to Find Music for Videos first appeared on Webdesigner Depot.
Original Source: https://designrfix.com/reviews/zymol-car-waxes
Finding the best zymol car waxes for your unique needs is a time-consuming task. That's why we have reviewed the best-selling products from various brands, so you don't have to waste your time! To pick the right Keyword, you should consider various factors. Our goal is to provide you with the top ten best zymol … Read more
Original Source: https://www.creativebloq.com/reviews/singer-heavy-duty4223
The Singer Heavy Duty 4423 benefits from a powerful motor and a range of built-in stitches, making it ideal for all sewing enthusiasts.
Original Source: https://1stwebdesigner.com/tailwind-wordpress-starter-themes-resources/
If you’re a frequent visitor to 1WD, you know we’ve been following the progress of Tailwind CSS, and you also know we love us some WordPress! In this article, we’re going to give you a list of starter themes and resources that will help you dive into combining the two. Tailwind can make it easier to build modern websites in less time with its utility-first framework, so why not integrate it with our favorite CMS, WordPress? What follows will help you get started.
UNLIMITED DOWNLOADS: 500,000+ WordPress & Design Assets
Sign up for Envato Elements and get unlimited downloads starting at only $16.50 per month!

DOWNLOAD NOW
Starter Themes
_tw
_tw provides a theme generator that creates a WordPress starter theme “optimized for modern development with Tailwind, Tailwind Typography, and the WordPress editor.” You can input advanced options such as the theme slug, function prefix, author, description, and more. Then download and unzip the zip file and get everything up and running in just a few simple steps. Created by Greg Sullivan, and based on the popular _s theme and generator, the theme includes Greg’s preferred directory structure, which may provide a small learning curve for those of us used to the traditional theme structure. Styles are visible for preview within your editor of choice, whether that may be the block editor, the classic editor, or Advanced Custom Fields’ WYSIWYG fields. It is also updated with Tailwind 3’s just-in-time (JIT) compiler.

TailPress
TailPress claims to be “your go-to starting point for developing WordPress themes with Tailwind CSS”. In just a few steps, using Composer, you can set up the theme name along with a new Git repository. TailPress supports the block editor and Tailwind’s JIT engine. You can watch the video below to learn more.
Gust
Gust is extremely flexible and can be configured to suit any design system. Every component and every piece of HTML is editable either through the page builder or a WP filter. And weighing in at only 3.8kb of CSS in an out of the box build, Gust focuses on speed and high performance. Gust comes with a bunch of essential components and templates you can use to get started building a website, and they’re adding to it all the time! Watch Gust in action in the video below.
Sage
Sage is a WordPress starter theme that is far more complex than the previous examples, but it does come with out of the box support for Tailwind. It uses Laravel, so if you’re not familiar, the learning curve may be a bit much. But Sage is a very robust starter theme solution.
Additional Articles and Resources for Tailwind + WordPress
Adding Tailwind CSS to New and Existing WordPress Themes
Setup Tailwind CSS in a WordPress plugin or theme — for Gutenberg
How to use Tailwind CSS v2.1 JIT compiler with WordPress theme (2021)
Installing TailwindCSS in a WordPress Theme
Build WordPress Websites Fast with Tailwind CSS
WordPress theme development with Tailwind CSS and Laravel Mix
How to set up Tailwind CSS (JIT) for WordPress
Tailwind CSS with Timber for WordPress Theme Development
Using Tailwind CSS In Your WordPress Theme
Supercharge your WordPress themes with Tailwind and Gulp
A Step by Step Guide to Headless WordPress, Gatsby, and Tailwind CSS Setup and Deployment
Setup Tailwind CSS in a WordPress plugin or theme
Tailwind CSS in WordPress Theme Development
Setting up Tailwind CSS in a WordPress Theme using gulp.js
Get Started With Tailwind and WordPress – Together At Last!
As you can see, there are a significant number of ways you can start using Tailwind CSS with WordPress in your projects. Bookmark this page so that when you do you have all the references you need!
Original Source: https://www.creativebloq.com/buying-guides/best-office-chair-for-back-pain
The best ergonomic office chairs for long hours at work.

