Using Friction As A Feature In Machine Learning Algorithms
Original Source: https://smashingmagazine.com/2023/08/friction-feature-machine-learning-algorithms/
A common assumption in user experience design is less friction makes apps more delightful. But in practice, the happy path isn’t always the smoothest. The term “friction” in the digital sense usually refers to anything that makes experiences cumbersome. It’s an analogy to the physical resistance that occurs when objects interact. Digital friction comes in many forms, from frustrating flows to confusing copy. But plenty of scenarios actually benefit with a bit of resistance. Its killer feature is mitigating unintended consequences, such as an accidental Alexa shopping spree.
You’ve likely already encountered intentional friction many times. Most apps leverage it for destructive actions, account security, and error handling, as recommended by experts from Norman Nielsen Group to the magazine you’re currently reading.
Yet friction has found a new calling in the age of artificial intelligence. When implemented correctly, it can improve the efficiency of AI systems such as machine learning algorithms. These algorithms are often used to personalize experiences through predictive recommendations. Some applications incorporating these algorithms realize that adding a bit of friction to their interface can turn each user interaction into an opportunity to improve algorithmic quality.
While less friction makes an app smoother, a bit more may make it even smarter.

Friction As A Feature
Before venturing down the AI rabbit hole, let’s explore some simple examples showcasing the basic benefits of friction in UX. These are a helpful foundation to build off as we ascend into more complex applications for machine learning algorithms. Regardless of your familiarity, this will ground the following lessons in first principles.
Preventing Unintended Consequences
A common use for friction is error prevention, the fifth entry in Jakob Nielsen’s list of usability heuristics. In scenarios with the potential for high-cost errors, such as irreversible deletion, apps often request confirmation before executing requests. Confirmations often display in a modal, locking the rest of the screen to increase focus on copy explaining an action’s implications. This extra step provides some extra time to consider these ramifications.
“By forcing us to slow down and think at this exact moment, we’re kept from making potentially disastrous decisions by accident.”
— Archana Madhavan in Amplitude’s “Onboarding With The IKEA Effect: How To Use UX Friction To Build Retention”
Sometimes more resistance is present when the consequences can be catastrophic. For instance, a confirmation may involve cognitive work such as typing “DELETE” to submit a deletion request. This level of resistance makes sense when considering the humbling fact of life from Steve Krug’s classic UX book Don’t Make Me Think, which states, “We don’t read pages. We scan them.” This makes it easy to imagine how a streamlined design can make it too easy to overlook the consequences of a click.

While these tactics may look comically cumbersome, they mitigate devastating downsides. This use of friction is like a train’s brakes screeching to a halt right in time to avoid a collision — everyone breathes a sigh of relief, crisis averted. This also outlines the basic framework for understanding when to add friction. It boils down to a cost-benefit analysis: do the rewards of streamlining outweigh the risk? If not, slow it down. Now let’s move on from a black & white example to venture into a grayer area.
Nudging Toward Healthy Behavior
Some problems aren’t classifiable as errors but still aren’t in anyone’s best interest. Trying to solve them becomes wicked because there is no right or wrong solution. Yet that doesn’t make failing to address them any less of an existential risk. Consider social media’s medley of knee-jerk, tribalistic behavior. It has led many to question the value of these apps altogether, which isn’t good for business, or society at large. In an attempt to encourage more thoughtful discourse, these platforms turn to friction.

Twitter explored adding an extra step that asks people to read articles before retweeting them. This nudge aims to craft a more trustworthy experience for everyone by slowing the spread of misinformation. According to their reporting, people shown the prompt opened articles 40% more often, and some decided not to retweet it after all. They built on this success by showing a warning before users post messages which include harmful language.
Instagram also implemented a similar feature in its fight against online bullying. Adam Mosseri, the Head of Instagram, published a blog post stating that this “intervention gives people a chance to reflect.” Although specific data isn’t provided, they suggest it had promising results in cultivating a more humane experience for their communities.
These examples show how faster is not always better. Sometimes we need restraint from saying things we don’t mean or sharing things that we don’t understand. Friction helps algorithms in a similar manner. Sometimes they also need more information about us so they don’t recommend things we won’t appreciate.
Understanding Preferences & Objectives
Let’s shift focus to AI with a simple example of how friction plays a role in machine learning algorithms. You’ve probably signed up for an app that begins by asking you a bunch of questions about your interests. Behind the scenes, an algorithm uses these answers to personalize your experience. These onboarding flows have become so common over the past decade that you may have forgotten a time before apps were smart enough to get to know you.

You may have never even questioned why you must go through a preference capture flow before getting to explore content. The value is obvious because no one wants the quickest path to something irrelevant. Many apps are simply in the business of making relevant connections, and these personalization tactics have been one of the best ways to do so. A McKinsey report illuminates this further by reporting that “35 percent of what consumers purchase on Amazon and 75 percent of what they watch on Netflix come from product recommendations based on such algorithms.”
“The top two reasons that customers churn are 1) they don’t understand your product, and 2) they don’t obtain any value from it. Customer onboarding can solve both of these issues.”
— Christina Perricone in HubSpot’s “The Ultimate Guide to Customer Onboarding”
Perhaps these onboarding flows are so familiar that they don’t feel like friction. They may seem like necessary steps to unlock an app’s value. However, that perspective quickly changes for anyone designing one of these flows. The inherent tension lies in attempting to balance the diametrically opposite needs of two parties. On the one hand, an algorithm provides better output relative to its input (although asymptotes exist). Success is a function of maximizing data collection touchpoints, but this tends to result in more steps with more complex questions.
In short, the quicker an app makes a recommendation, the more likely it will be wrong. On the other hand, an extremely long onboarding flow is unlikely to make an amazing first impression on new users. I had the pleasure of walking this tightrope when designing the onboarding flow at Headliner. Each new step we added always felt like it would be the straw that broke the camel’s back. We nervously monitored our activation reports for signs we went too far but surprisingly saw no meaningful dropoff. Yet, even a slight decrease would easily be worth the improved retention that personalization yielded.

This is thanks to some clever interface innovations. TikTok’s design turns user engagement into clear signals they use to tweak their algorithms. Content recommendation quality is a direct function of this, which some refer to as an algorithm’s vision.
Optimizing an app’s key interactions to understand implicit signals makes an explicit means of capturing preferences unnecessary.
Engagement Signals
Every interaction is an opportunity to improve understanding through bidirectional feedback. An interface should provide system feedback to the user engaging with it while also reporting to the system how performance meets user expectations. Everything from button taps to the absence of action can become a signal. Interfaces that successfully incorporate this are referred to as algorithm-friendly.

A study by Apple’s Machine Learning Research Department details their success in leveraging engagement signals, which they believe “provide strong indications of a user’s true intent,” to efficiently train a machine learning model through a process called Reinforcement Learning from Human Feedback. Their results documented “significant accuracy gains in a production deep learning system,” meaning that an interface designed well enough to analyze naturally occurring user behavior is all that is needed to create personalization that feels like mind reading.
Instagram actually employs this strategy as well, although its approach is a bit less cohesive since they seem to be in a perpetual state of transition.
TikTokification
But what exactly makes an interface algorithm-friendly? In TikTok’s case, it was the design decision to only show one video at a time. That’s right, friction! By decreasing the information density in the viewport at any given time, they increased their understanding of a user’s focus. This localizes interactions (or lack thereof) to specific content as quality measures.
Gustav Söderström, the Co-President, CPO & CTO at Spotify has referred to this approach as “giving the algorithm glasses.” Compare this to the medley of distractions in other feeds, and it’s easy to imagine which one is better at collecting data.
Using friction as a tool allows designers to craft an interface that separates engagement signals from noise.
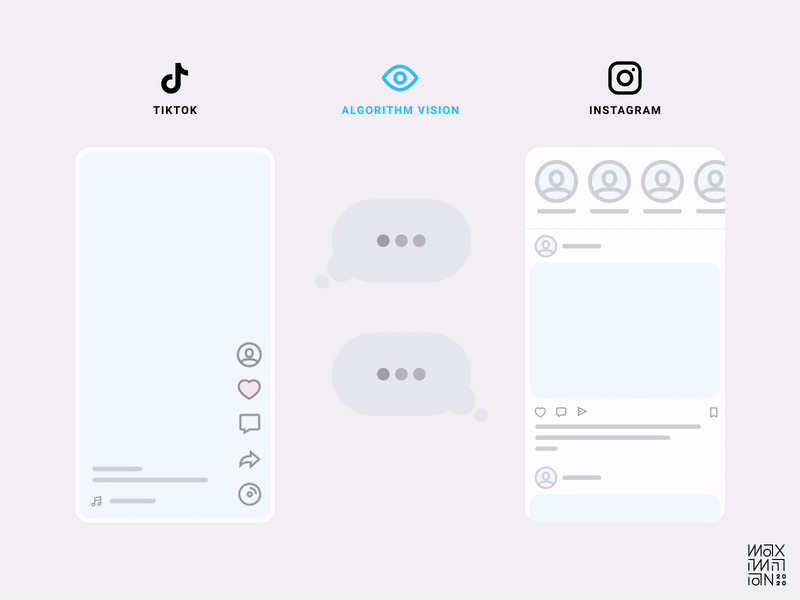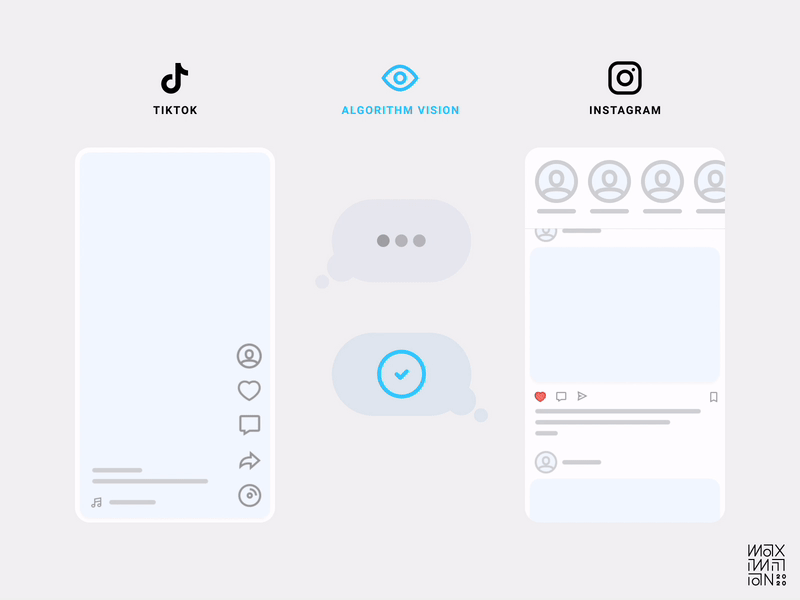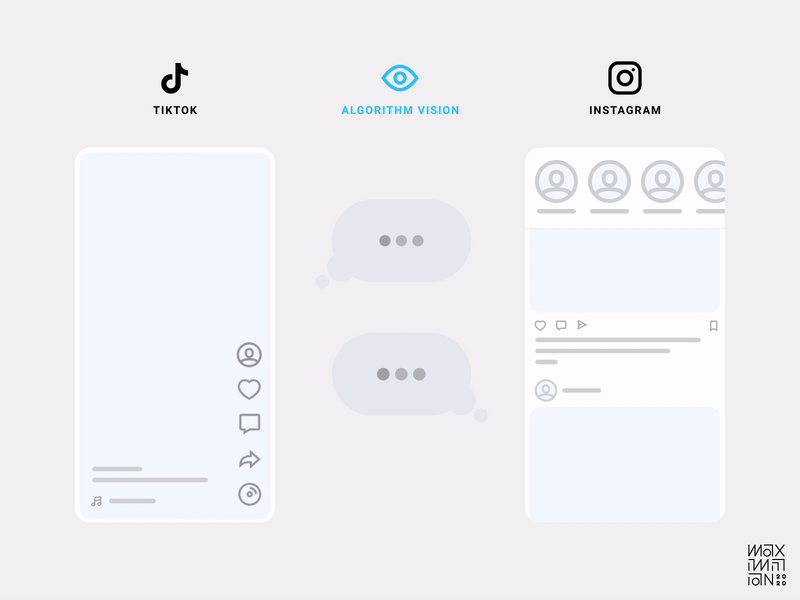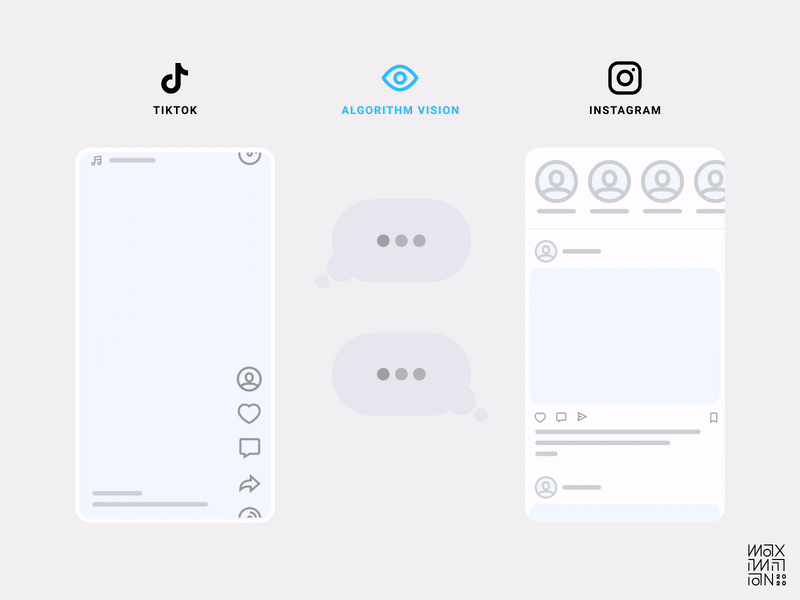 Algorithmic visibility comparison of TikTok & Instagram’s home feeds. (Source: Maximillian Piras) (Large preview)
Algorithmic visibility comparison of TikTok & Instagram’s home feeds. (Source: Maximillian Piras) (Large preview)
As we return to my aforementioned framework for evaluating when to add friction, we can understand how it makes sense in this scenario. While each interaction may take slightly longer, relevant content can be found quicker. The trade-off makes sense since relevance sits atop a user’s hierarchy of needs.
Additionally, if you were to measure friction over a longer time horizon, you likely would find an experience with better personalization feels more frictionless. This is because the efficiency in helping users find what they’re looking for would consistently compound (although, again, asymptotes exist). So each subsequent visit theoretically requires less work on the user’s part, which makes the alternate approach look like the cumbersome one.
“The secret of why some of these products are so good at recommendations is not actually that they have better algorithms. It’s the same algorithms with a more efficient user interface.”
— Gustav Söderström in The Verge’s “Why Spotify wants to look like TikTok”
While TikTok popularized this interface, anybody who was single in the last decade may notice a similarity to dating apps. Using directional gestures as engagement signals dates back to the swipeable card paradigm Tinder introduced in 2012. They, too, limited the viewport to one result at a time and used actions to inform subsequent recommendations. But TikTok took it mainstream since not everyone needs a dating app, and those who do will churn once they’ve met someone.
The results of using this paradigm in everyday entertainment led many platforms to copy it in hopes of the same algorithmic gains. The latest to embark on this journey is Spotify, much to the chagrin of their users. In fact, this decision even landed it on Mashable’s list of worst app updates in 2023. But Söderström says they don’t have a choice, and he believes in the long run, the signal clarity will make up for any interim backlash because of how much quicker it can learn user preferences. Critics fail to realize how important these changes are for Spotify’s future.
In the machine learning age, apps with inefficient interfaces for signal analysis risk becoming uncompetitive.
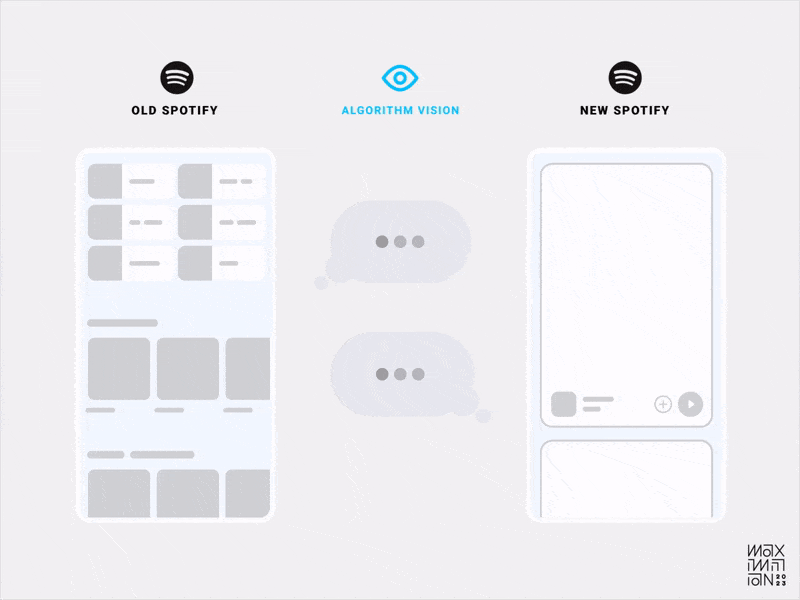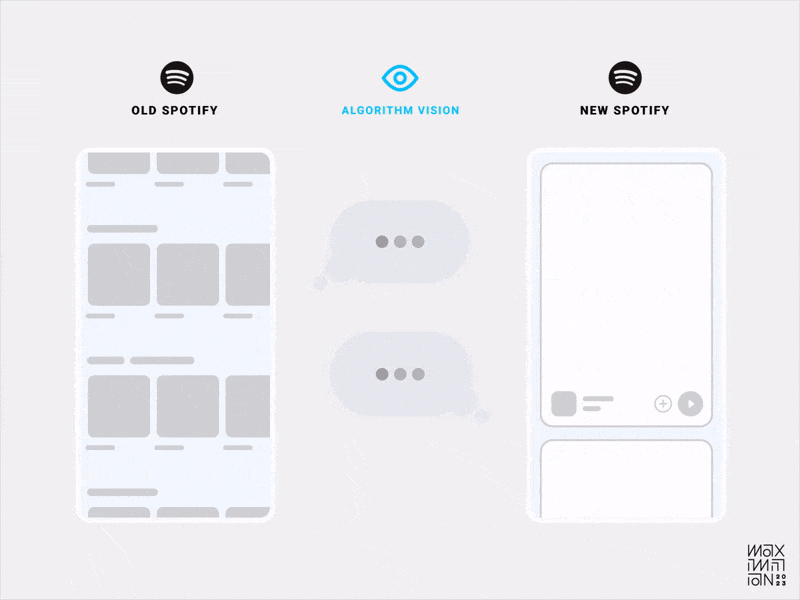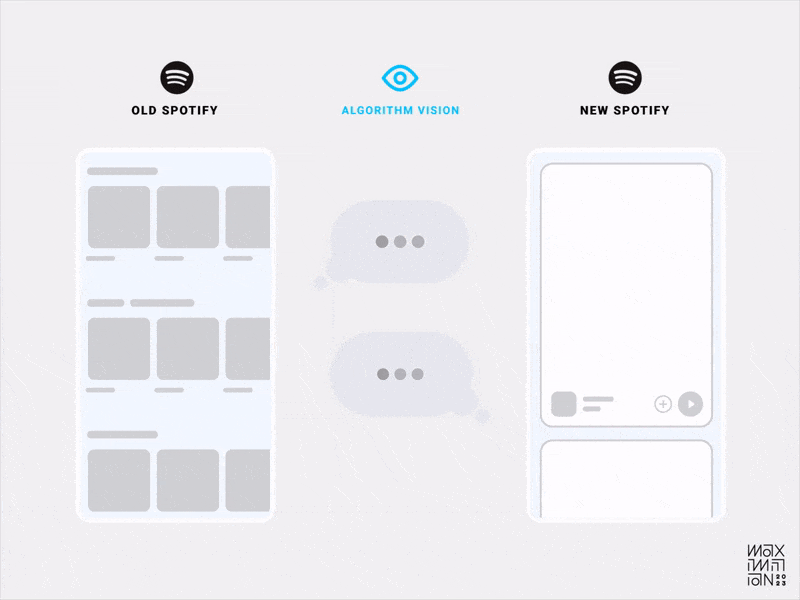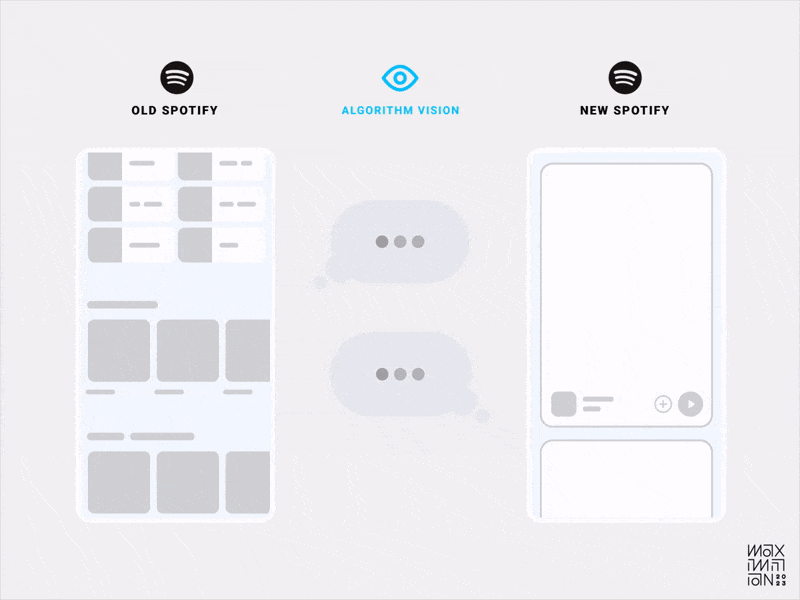 Algorithmic visibility comparison of Spotify’s old & new home feeds. (Source: Maximillian Piras) (Large preview)
Algorithmic visibility comparison of Spotify’s old & new home feeds. (Source: Maximillian Piras) (Large preview)
Making Lemonade
The reason this approach is so powerful is due to the compounding nature of good data. Optimizing signals for any individual user creates a data network effect that benefits everyone else. It even turns negatives into positives! An individual bad experience can mitigate others from encountering the same, making the system antifragile.
This approach dates back to 2003 with the introduction of Amazon’s item-to-item collaborative filtering. You may know it as “customers who viewed this also viewed this.”

This type of filtering produces high-quality recommendations with limited user data. It does so by building relationships between items to proxy user preferences. With only two to three data points, an algorithm can draw connections across the entire dataset. It effectively piggybacks off previous patterns that are similar enough.
This means an app like TikTok only needs a few swipes before it can make high-probability assumptions about your preferences. That’s why friction is so useful in algorithm-friendly interfaces. If the initial interactions send clean signals, then an algorithm can graph a user’s interests almost immediately.
Friction In The Future
We began in the past by reviewing how friction found its way into UX toolkits through error prevention and healthy nudges. Then we moved on to its ability to help algorithms learn user preferences and objectives. While explicit onboarding flows are still in vogue, TikTok is popularizing an interface that makes them unnecessary by using implicit engagement signals leading to significant algorithmic gains. Yet the machine learning age is just beginning, and friction is only accelerating its evolution.
Inverting The Pareto Principle
We’ve focused on algorithms that recommend content, but more diverse uses of personalization may emerge due to the newfound capabilities of Large Language Models. These models unlock the ability to manipulate unstructured data at scale. This allows engagement patterns of greater complexity to be analyzed and productized. The result is algorithms can recommend much more than media and metadata.
Perhaps they can craft completely personalized feature sets based on our preferences and objectives. Imagine selecting effects in Photoshop and seeing suggestions such as “Creators who used this effect also used this one.” These capabilities could increase the usage of buried features that only power users tend to find.
Microsoft is exploring this by adding Copilot to its products. They claim the “average person uses less than 10% of what PowerPoint can do,” but AI will unlock all that latent value.
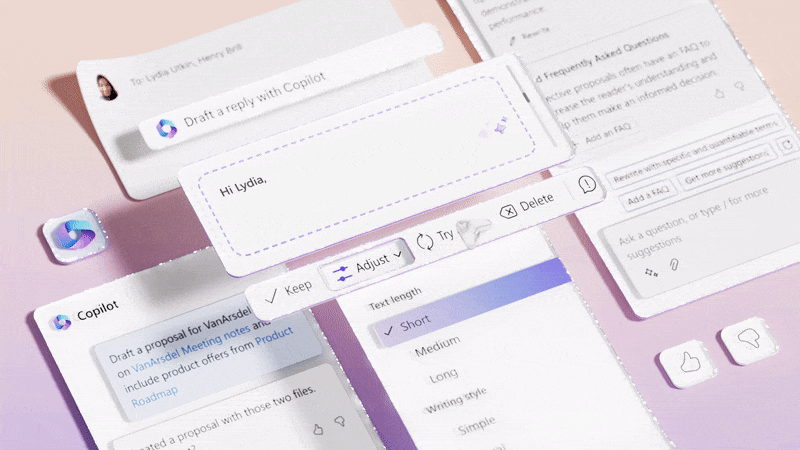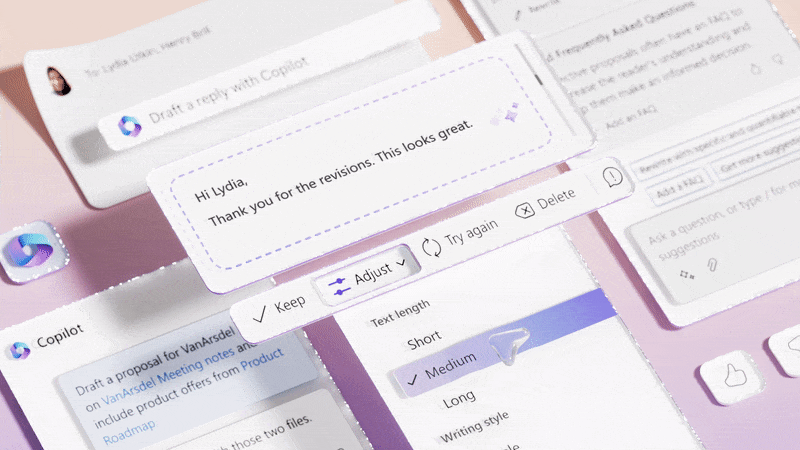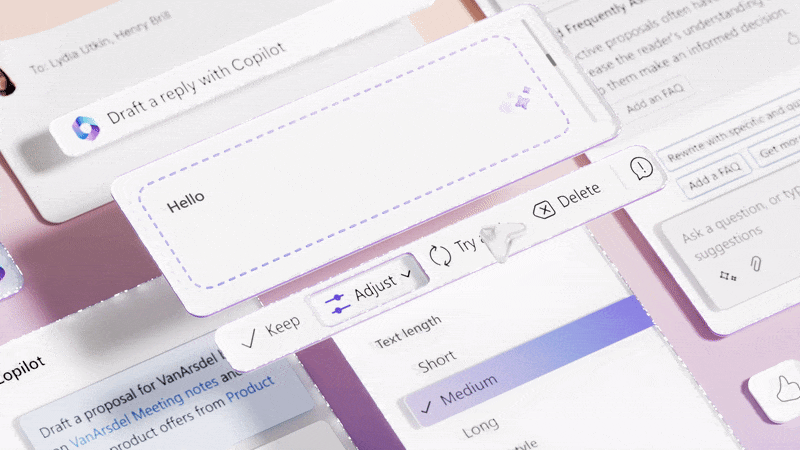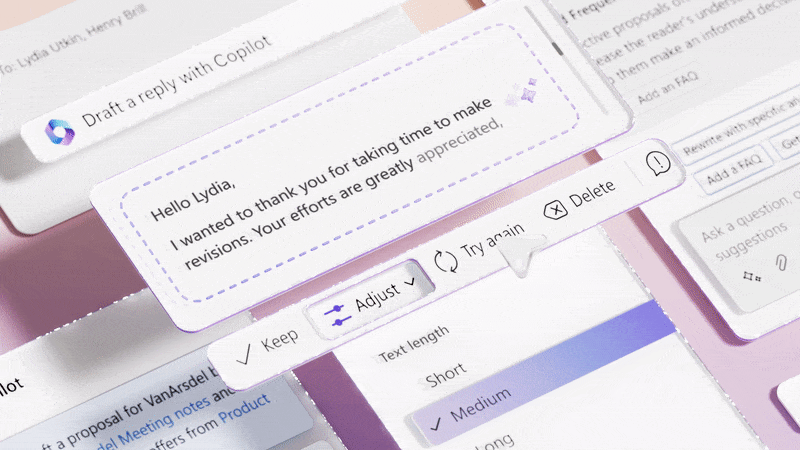 Microsoft Copilot uses LLMs in an attempt to unlock the 90% of features that most users don’t know exist. (Source: Microsoft Design) (Large preview)
Microsoft Copilot uses LLMs in an attempt to unlock the 90% of features that most users don’t know exist. (Source: Microsoft Design) (Large preview)
Using LLMs to create feature recommendation engines is a fascinating idea. It would allow developers to stop relying on the Pareto Principle for prioritization. Especially because Joel Spolsky claims the 80/20 rule is actually a myth.
“A lot of software developers are seduced by the old “80/20” rule. It seems to make a lot of sense: 80% of the people use 20% of the features… Unfortunately, it’s never the same 20%. Everybody uses a different set of features.”
— Joel Spolsky in “Strategy Letter IV: Bloatware and the 80/20 Myth”
It would be nice if irreducible simplicity in interface design were only a power law away, but feature creep is hard to combat when different people find value in different options. It’s unrealistic to believe that there is some golden 20% of features driving 80% of value. If there was, then why isn’t the Pareto Principle ever applied to content?
I can’t imagine a team at YouTube suggesting that removing 80% of videos would improve the service. Instead, it’s viewed as a routing problem: find the right piece of content for the right person. If machine learning algorithms can recommend features, I hope the value of friction goes without saying at this point. The efficiency gains unlocked by algorithm-friendly interfaces absolutely apply.
Hallucinations Or Creations
The recent inflection point in the capability of LLMs unlocks an entirely new computing paradigm. The legendary UX researcher Jakob Nielsen believes it introduces the first new UI paradigm in 60 years, which he calls Intent-Based Outcome Specification. Instead of telling computers what to do, we now explain an outcome so they can determine how to achieve it.
Using machine learning algorithms to recommend features is one example. Another fairly new example that you’re likely familiar with is chatbots like ChatGPT. Hundreds of millions of people already use it, which is a testament to how out of this world the experience is. Yet therein lies a problem: sometimes its responses literally aren’t grounded in reality because it has a tendency to make them up! This isn’t obvious to those unfamiliar with the technology’s inner workings since there aren’t many safeguards. As a result, some people become dangerously overreliant on its unverified output.
In one case, a lawyer based legal arguments on research from ChatGPT only to find out in court that multiple cited sources turned out to be completely nonexistent. The lawyer’s defense was that he was “unaware of the possibility that its content could be false.” Examples like this reinforce the importance of friction in preventing unintended consequences. While ChatGPT’s empty state mentions its limitations, they obviously aren’t stated explicitly enough for everyone.

Extra steps and prompts, such as those mentioned earlier, could better educate users about what is referred to as a “hallucination.” It’s a phenomenon of chatbots confidently outputting responses that don’t align with their training data. Similar to telling a lie when you don’t have a correct answer, although that characterization overly anthropomorphizes the software.
Yet some see hallucinations as more of a feature than a bug. Marc Andreessen, the co-founder of Netscape, states during an interview that “another term for hallucination is just simply creativity.” He views it as a significant evolution from the hyperliteral systems of the past because they can now brainstorm and improvise.
The problem is that chatbot interfaces tend to be simplistic by attempting to be one size fits all. More controls or modes would educate users about available output types so they can specify which they expect. Sometimes we may want an imaginative response from a creative partner. Other times we want the hyper-accuracy of a deterministic calculator, such as ChatGPT’s Wolfram plugin.
Perhaps a creativity slider or persona selector similar to Maggie Appleton’s exploration will better align the system to user needs. However it’s implemented, a bit of friction can maximize benefits while minimizing risks.
Finding Your Friction
We’ve covered using friction for simple error prevention to complex algorithm optimizations. Let’s end with a few tips that make implementing it as smooth as possible.
Peak-End Rule
When adding resistance to an experience, the Peak-End Rule is a useful psychological heuristic to leverage. It’s rooted in studies by Daniel Kahneman & Amos Tversky, where they found that perception of painful experiences doesn’t tend to correlate with duration. It’s the peak & end of the experience that subjects recall.
In practice, experts suggest that delight is a function of positive emotional peaks and rewarding emotional payoffs. Optimizing for the peak & end provides room to shift focus from time spent and steps taken as performance indicators; long and complex experiences can still be delightful if designed correctly.

Maps Aren’t Territories
People experience friction emotionally, but developers see it as a value on a chart. In the same way that a map is not a territory, this ratio is only an approximation of the actual experience. It’s something to consider when evaluating any strategies for adding or removing friction. Since applications are complex ecosystems, any measurements should consider a holistic view. Every step has second-order effects, which makes one-dimensional measurements prone to blind spots.
For example, when a wrong file is deleted, the data can’t report people cursing at their computer screen. Nor is it likely to include the context of them opening a new file just to recreate their old file from scratch. The same subjectivity applies to all instances of friction. For instance, are your reports equipped to measure the trade-off of an action that takes longer but results in better data collection? It might increase algorithmic efficiency, which compounds across a neural network.
As we’ve discussed, better recommendations tend to yield better retention, which tends to yield more revenue if a business model aligns with usage. Myopic measurements will miss these types of gains, so make sure to analyze friction in a way that really matters.
Keep Pushing
As software is eating the world, AI is eating software. If it’s a paradigm shift as big as social, mobile, or even the web, then applications must adapt or die. If you want to remain competitive in the machine learning age, then don’t fear friction.
Further Reading on Smashing Magazine
“Using AI To Detect Sentiment In Audio Files,” Joas Pambou
“Modern Technology And The Future Of Language Translation,” Adriano Raiano
“Beyond Algorithms: Skills Of Designers That AI Can’t Replicate,” Lyndon Cerejo
“How To Use AI Tools To Skyrocket Your Programming Productivity,” Shane Duggan
Leave a Reply
Want to join the discussion?Feel free to contribute!