Original Source: https://www.smashingmagazine.com/2018/05/desktop-wallpaper-calendars-june-2018/
Cheerful Desktop Wallpapers To Kick Off June (2018 Edition)
Cheerful Desktop Wallpapers To Kick Off June (2018 Edition)
Cosima Mielke
2018-05-31T08:43:08+02:00
2018-05-31T11:49:45+00:00
We all need a little inspiration boost every once in a while. And, well, whatever your strategy to get your creative juices flowing might be, sometimes inspiration lies closer than you think. As close as your desktop even.
Since more than nine years, we’ve been asking the design community to create monthly desktop wallpaper calendars. Wallpapers that are a bit more distinctive as what you’ll usually find out there, bound to cater for a little in-between inspiration spark. Of course, it wasn’t any different this time around.
This post features wallpapers for June 2018. All of them come in versions with and without a calendar, so it’s up to you to decide if you want to have the month at a glance or keep things simple. As a bonus goodie, we also collected some timeless June favorites from past years for this edition (please note that they thus don’t come with a calendar). A big thank-you to all the artists who have submitted their wallpapers and are still diligently continuing to do so. It’s time to freshen up your desktop!
Please note that:
All images can be clicked on and lead to the preview of the wallpaper,
You can feature your work in our magazine by taking part in our Desktop Wallpaper Calendar series. We are regularly looking for creative designers and artists to be featured on Smashing Magazine. Are you one of them?
What if there was a web conference without… slides? Meet SmashingConf Toronto 2018 ?? with live sessions exploring how experts work behind the scenes. Dan Mall, Lea Verou, Sara Soueidan, Seb Lee-Delisle and many others. June 26–27. With everything from live designing to live performance audits.
Check the speakers →

Travel Time
“June is our favorite time of the year because the keenly anticipated sunny weather inspires us to travel. Stuck at the airport, waiting for our flight but still excited about wayfaring, we often start dreaming about the new places we are going to visit. Where will you travel to this summer? Wherever you go, we wish you a pleasant journey!” — Designed by PopArt Studio from Serbia.

preview
with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Tropical Vibes
“With summer just around the corner, I’m already feeling the tropical vibes.” — Designed by Melissa Bogemans from Belgium.

preview
with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
No Matter What, I’ll Be There
“June is the month when we celebrate our dads and to me the best ones are the ones that even if they don’t like what you are doing they’ll be by your side.” — Designed by Maria Keller from Mexico.

preview
with calendar: 320×480, 640×480, 640×1136, 750×1334, 800×480, 800×600, 1024×768, 1024×1024, 1125×2436, 1152×864, 1242×2208, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 2880×1800
without calendar: 320×480, 640×480, 640×1136, 750×1334, 800×480, 800×600, 1024×768, 1024×1024, 1125×2436, 1152×864, 1242×2208, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 2880×1800
We Sailed Across The Summer Sea
“Summer is the season of family trips, outings and holidays. What better way is there to celeberate Father’s Day, than to enjoy the summer sailing across with father beloved.” — Designed by The Whisky Corporation from Singapore.

preview
with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Sounds Of Rain
“When it rains the world softens and listens to the gentle pattering of the rain. It gets covered in a green vegetation and puddles reflect the colors of nature now looking fresh and cleansed. The lullaby of the rain is accustomed to creaky frogs and soft chirping birds taking you to ecstasy.” — Designed by Aviv Digital from India.

preview
with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
-SmashingConf Toronto
“What’s the best way to learn? By observing designers and developers working live. For our new conference in Toronto, all speakers aren’t allowed to use any slides at all. Welcome SmashingConf #noslides, a brand new conference in Toronto, full of interactive live sessions, showing how web designers design and how web developers build — including setup, workflow, design thinking, naming conventions and everything in-between.” — Designed by Ricardo Gimenes from Brazil.

preview
with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Are You Ready?
“The excitement is building, the slogans are ready, the roaring and the cheering make their way… Russia is all set for the football showdown. Are you ready?” — Designed by Sweans from London.

preview
with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Summer Surf
“Summer vibes…” — Designed by Antun Hirsman from Croatia.

preview
with calendar: 640×480, 1152×864, 1280×1024, 1440×900, 1680×1050, 1920×1080, 1920×1440, 2650×1440
without calendar: 640×480, 1152×864, 1280×1024, 1440×900, 1680×1050, 1920×1080, 1920×1440, 2650×1440
Stop Child Labor
“‘Child labor and poverty are inevitably bound together, and if you continue to use the labor of children as the treatment for the social disease of poverty, you will have both poverty and child labor to the end of time.’ (Grace Abbott)” — Designed by Dipanjan Karmakar from India.

preview
with calendar: 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1680×1050, 1920×1080
without calendar: 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1680×1050, 1920×1080
Is your pattern library up to date today? Alla Kholmatova has just finished a fully fledged book on Design Systems and how to get them right. With common traps, gotchas and the lessons she learned. Hardcover, eBook. Just sayin’.
Table of Contents →

June Best-Of
Some things are too good to be forgotten. That’s why we dug out some June favorites from our archives. Please note that these don’t come with a calendar because of this. Enjoy!
Oh, The Places You Will Go!
“In celebration of high school and college graduates ready to make their way in the world!” — Designed by Bri Loesch from the United States.

preview
without calendar: 320×480, 1024×768, 1280×1024, 1440×900, 1680×1050, 1680×1200, 1920×1440, 2560×1440
Join The Wave
“The month of warmth and nice weather is finally here. We found inspiration in the World Oceans Day which occurs on June 8th and celebrates the wave of change worldwide. Join the wave and dive in!” — Designed by PopArt Studio from Serbia.

preview
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Solstice Sunset
“June 21 marks the longest day of the year for the Northern Hemisphere – and sunsets like these will be getting earlier and earlier after that!” — Designed by James Mitchell from the United Kingdom.

preview
without calendar: 1280×720, 1280×800, 1366×768, 1440×900, 1680×1050, 1920×1080, 1920×1200, 2560×1440, 2880×1800
Midsummer Night’s Dream
“The summer solstice in the northern hemisphere is nigh. Every June 21 we celebrate the longest day of the year and, very often, end up dancing like pagans. Being landlocked, we here in Serbia can only dream about tidal waves and having fun at the beach. What will your Midsummer Night’s Dream be?” — Designed by PopArt Studio from Serbia.

preview
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1440×900, 1440×1050, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Flamingood Vibes Only
“I love flamingos! They give me a happy feeling that I want to share with the world.” — Designed by Melissa Bogemans from Belgium.

preview
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1200, 1920×1440, 2560×1440
Papa Merman
“Dream away for a little while to a land where June never ends. Imagine the ocean, feel the joy of a happy and carefree life with a scent of shrimps and a sound of waves all year round. Welcome to the world of Papa Merman!” — Designed by GraphicMama from Bulgaria.

preview
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Strawberry Fields
Designed by Nathalie Ouederni from France.

preview
without calendar: 320×480, 1024×768, 1280×1024, 1440×900, 1680×1200, 1920×1200, 2560×1440
Fishing Is My Passion!
“The month of June is a wonderful time to go fishing, the most soothing and peaceful activity.” — Designed by Igor Izhik from Canada.

preview
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Summer Time
“Summer is coming so I made this simple pattern with all my favorite summer things.” — Designed by Maria Keller from Mexico.

preview
without calendar: 320×480, 640×480, 640×1136, 750×1334, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1242×2208, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 2880×1800
The Amazing Water Park
“Summer is coming. And it’s going to be like an amazing water park, full of stunning encounters.” — Designed by Netzbewegung / Mario Metzger from Germany.

preview
without calendar: 320×480, 640×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Gravity
Designed by Elise Vanoorbeek (Doud Design) from Belgium.

preview
without calendar: 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Periodic Table Of HTML5 Elements
“We wanted an easy reference guide to help navigate through HTML5 and that could be updateable” — Designed by Castus from the UK.

preview
without calendar: 1024×768, 1280×800, 1280×1024, 1366×768, 1440×900, 1600×900, 1600×1200, 1920×1080, 1920×1200, 2560×1440
Ice Creams Away!
“Summer is taking off with some magical ice cream hot air balloons.” — Designed by Sasha Endoh from Canada

preview
without calendar: 320×480, 1024×768, 1152×864, 1280×800, 1280×960, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1920×1080, 1920×1200, 2560×1440
Lavender Is In The Air!
“June always reminds me of lavender — it just smells wonderful and fresh. For this wallpaper I wanted to create a simple, yet functional design that featured… you guessed it… lavender!” — Designed by Jon Phillips from Canada.

preview
without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Ice Cream June
“For me, June always marks the beginning of summer! The best way to celebrate summer is of course ice cream, what else?” — Designed by Tatiana Anagnostaki from Greece.
preview
without calendar: 1024×768, 1280×1024, 1440×900, 1680×1050, 1680×1200, 1920×1440, 2560×1440
Join In Next Month!
Please note that we respect and carefully consider the ideas and motivation behind each and every artist’s work. This is why we give all artists the full freedom to explore their creativity and express emotions and experience throughout their works. This is also why the themes of the wallpapers weren’t anyhow influenced by us, but rather designed from scratch by the artists themselves.
Thank you to all designers for their participation. Join in next month!




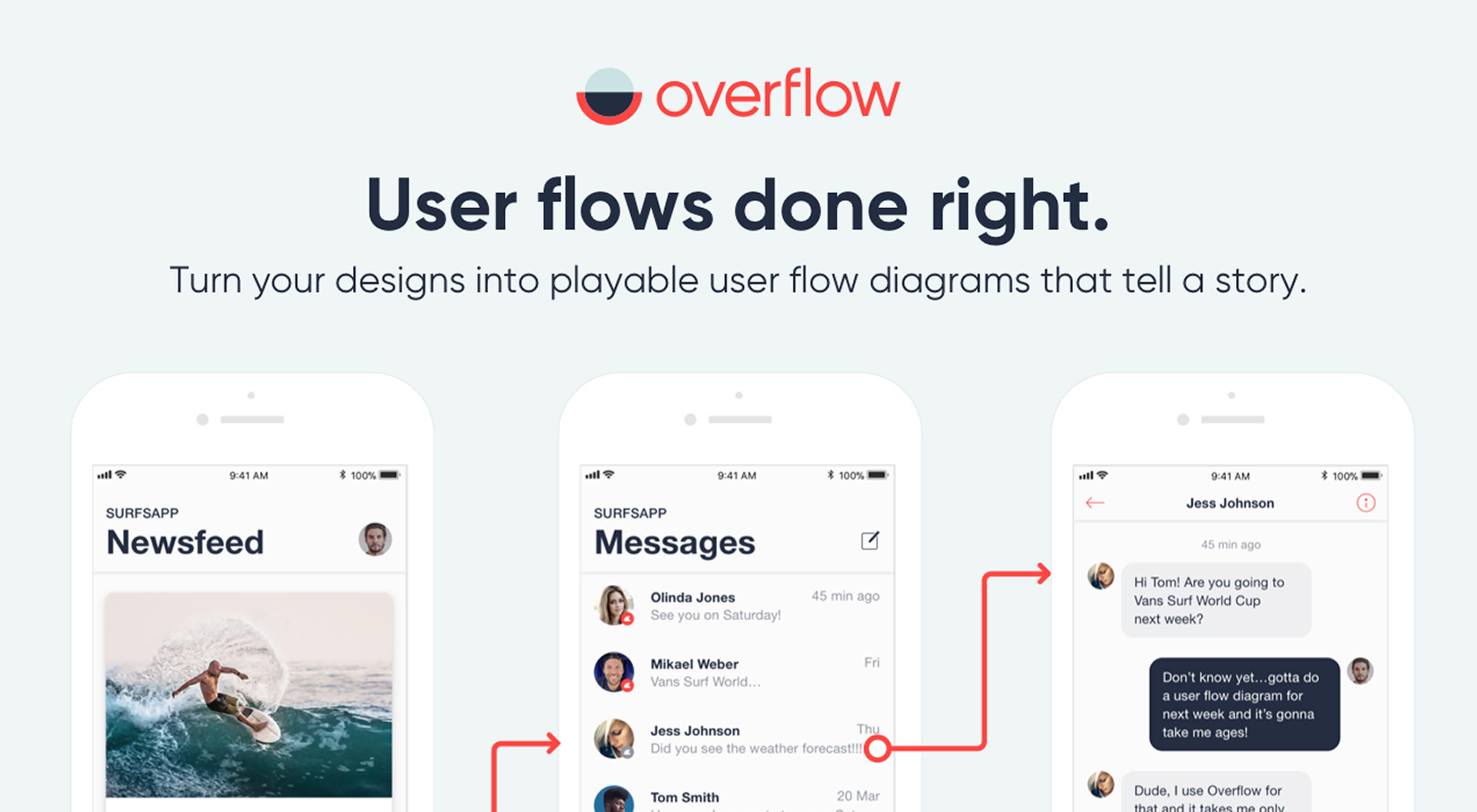 Designing the best user flow for your product is definitely not an easy task. It requires several iterations before getting it right. Creating and updating user flow diagrams has largely been considered a painful process for designers, with many of them skipping it entirely because of this. Presenting user flows to stakeholders and actually getting them to understand and follow the user’s journey might actually be the most challenging part.
Designing the best user flow for your product is definitely not an easy task. It requires several iterations before getting it right. Creating and updating user flow diagrams has largely been considered a painful process for designers, with many of them skipping it entirely because of this. Presenting user flows to stakeholders and actually getting them to understand and follow the user’s journey might actually be the most challenging part.
 So yeah, what the title said. Microsoft is buying GitHub for 7.5 BILLION with a “B” US dollars. This is officially this week’s Big DealTM, and everyone’s going to be talking about it. It would not be quite accurate to say that GitHub powers software development as a whole, but it powers a lot of it. GitHub’s friendliness to — and free repositories for — open source software have made it nigh on indispensable for many developers around the world.
So yeah, what the title said. Microsoft is buying GitHub for 7.5 BILLION with a “B” US dollars. This is officially this week’s Big DealTM, and everyone’s going to be talking about it. It would not be quite accurate to say that GitHub powers software development as a whole, but it powers a lot of it. GitHub’s friendliness to — and free repositories for — open source software have made it nigh on indispensable for many developers around the world.
