Human-Centered Design Through AI-Assisted Usability Testing: Reality Or Fiction?
Original Source: https://smashingmagazine.com/2025/02/human-centered-design-ai-assisted-usability-testing/
Unmoderated usability testing has been steadily growing more popular with the assistance of online UX research tools. Allowing participants to complete usability testing without a moderator, at their own pace and convenience, can have a number of advantages.
The first is the liberation from a strict schedule and the availability of moderators, meaning that a lot more participants can be recruited on a more cost-effective and quick basis. It also lets your team see how users interact with your solution in their natural environment, with the setup of their own devices. Overcoming the challenges of distance and differences in time zones in order to obtain data from all around the globe also becomes much easier.
However, forgoing the use of moderators also has its drawbacks. The moderator brings flexibility, as well as a human touch into usability testing. Since they are in the same (virtual) space as the participants, the moderator usually has a good idea of what’s going on. They can react in real-time depending on what they witness the participant do and say. A moderator can carefully remind the participants to vocalize their thoughts. To the participant, thinking aloud in front of a moderator can also feel more natural than just talking to themselves. When the participant does something interesting, the moderator can prompt them for further comment.
Meanwhile, a traditional unmoderated study lacks such flexibility. In order to complete tasks, participants receive a fixed set of instructions. Once they are done, they can be asked to complete a static questionnaire, and that’s it.
The feedback that the research & design team receives will be completely dependent on what information the participants provide on their own. Because of this, the phrasing of instructions and questions in unmoderated testing is extremely crucial. Although, even if everything is planned out perfectly, the lack of adaptive questioning means that a lot of the information will still remain unsaid, especially with regular people who are not trained in providing user feedback.
If the usability test participant misunderstands a question or doesn’t answer completely, the moderator can always ask for a follow-up to get more information. A question then arises: Could something like that be handled by AI to upgrade unmoderated testing?
Generative AI could present a new, potentially powerful tool for addressing this dilemma once we consider their current capabilities. Large language models (LLMs), in particular, can lead conversations that can appear almost humanlike. If LLMs could be incorporated into usability testing to interactively enhance the collection of data by conversing with the participant, they might significantly augment the ability of researchers to obtain detailed personal feedback from great numbers of people. With human participants as the source of the actual feedback, this is an excellent example of human-centered AI as it keeps humans in the loop.

There are quite a number of gaps in the research of AI in UX. To help with fixing this, we at UXtweak research have conducted a case study aimed at investigating whether AI could generate follow-up questions that are meaningful and result in valuable answers from the participants.
Asking participants follow-up questions to extract more in-depth information is just one portion of the moderator’s responsibilities. However, it is a reasonably-scoped subproblem for our evaluation since it encapsulates the ability of the moderator to react to the context of the conversation in real time and to encourage participants to share salient information.
Experiment Spotlight: Testing GPT-4 In Real-Time Feedback
The focus of our study was on the underlying principles rather than any specific commercial AI solution for unmoderated usability testing. After all, AI models and prompts are being tuned constantly, so findings that are too narrow may become irrelevant in a week or two after a new version gets updated. However, since AI models are also a black box based on artificial neural networks, the method by which they generate their specific output is not transparent.
Our results can show what you should be wary of to verify that an AI solution that you use can actually deliver value rather than harm. For our study, we used GPT-4, which at the time of the experiment was the most up-to-date model by OpenAI, also capable of fulfilling complex prompts (and, in our experience, dealing with some prompts better than the more recent GPT-4o).
In our experiment, we conducted a usability test with a prototype of an e-commerce website. The tasks involved the common user flow of purchasing a product.
Note: See our article published in the International Journal of Human-Computer Interaction for more detailed information about the prototype, tasks, questions, and so on).
In this setting, we compared the results with three conditions:
A regular static questionnaire made up of three pre-defined questions (Q1, Q2, Q3), serving as an AI-free baseline. Q1 was open-ended, asking the participants to narrate their experiences during the task. Q2 and Q3 can be considered non-adaptive follow-ups to Q1 since they asked participants more directly about usability issues and to identify things that they did not like.
The question Q1, serving as a seed for up to three GPT-4-generated follow-up questions as the alternative to Q2 and Q3.
All three pre-defined questions, Q1, Q2, and Q3, each used as a seed for its own GPT-4 follow-up.
The following prompt was used to generate the follow-up questions:

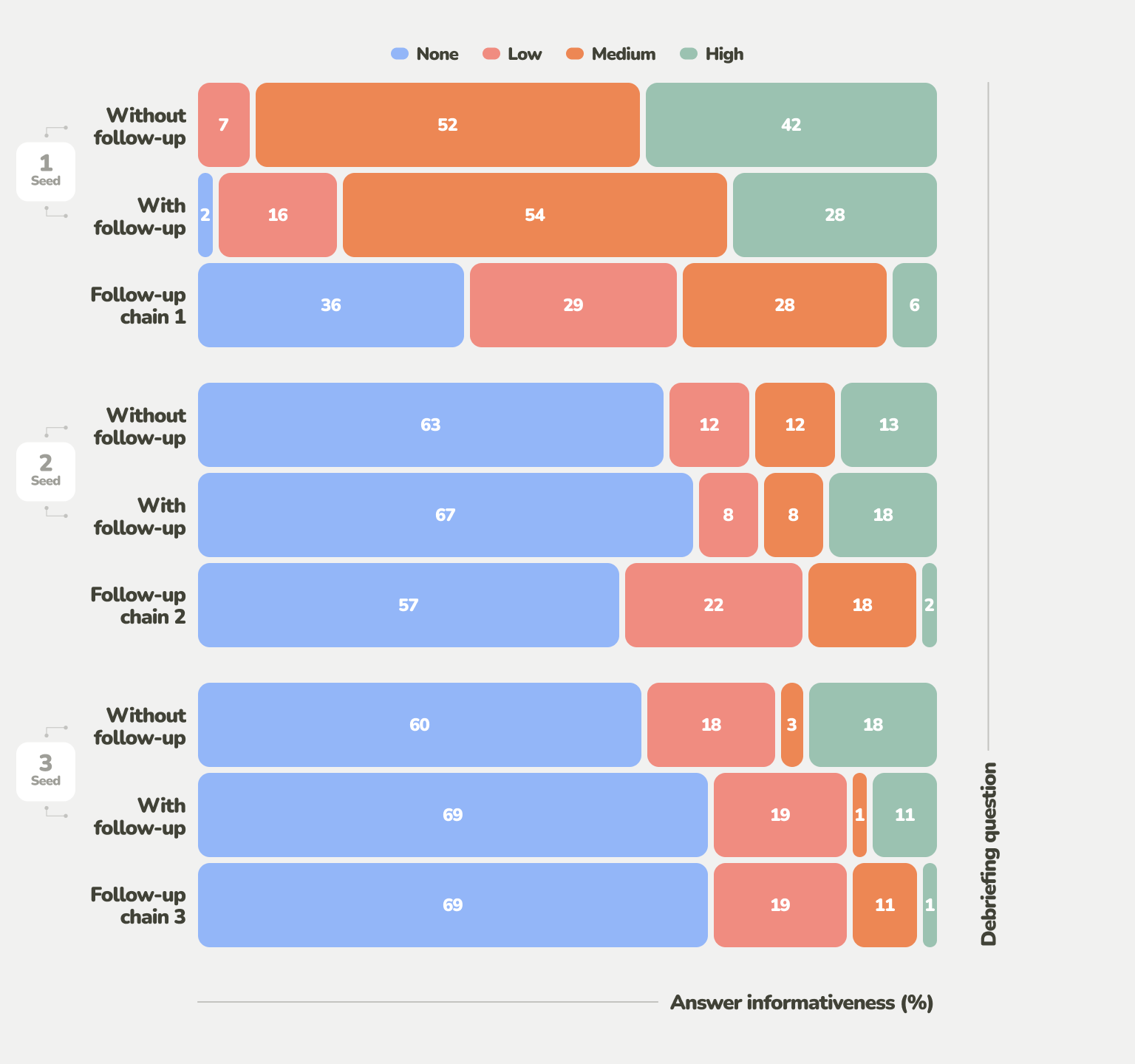
To assess the impact of the AI follow-up questions, we then compared the results on both a quantitative and a qualitative basis. One of the measures that we analyzed is informativeness — ratings of the responses based on how useful they are at elucidating new usability issues encountered by the user.
As seen in the figure below, the informativeness dropped significantly between the seed questions and their AI follow-up. The follow-ups rarely helped identify a new issue, although they did help elaborate further details.
The emotional reactions of the participants offer another perspective on AI-generated follow-up questions. Our analysis of the prevailing emotional valence based on the phrasing of answers revealed that, at first, the answers started with a neutral sentiment. Afterward, the sentiment shifted toward the negative.
In the case of the pre-defined questions Q2 and Q3, this could be seen as natural. While question Seed 1 was open-ended, asking the participants to explain what they did during the task, Q2 and Q3 focused more on the negative — usability issues and other disliked aspects. Curiously, the follow-up chains generally received even more negative receptions than their seed questions, and not for the same reason.
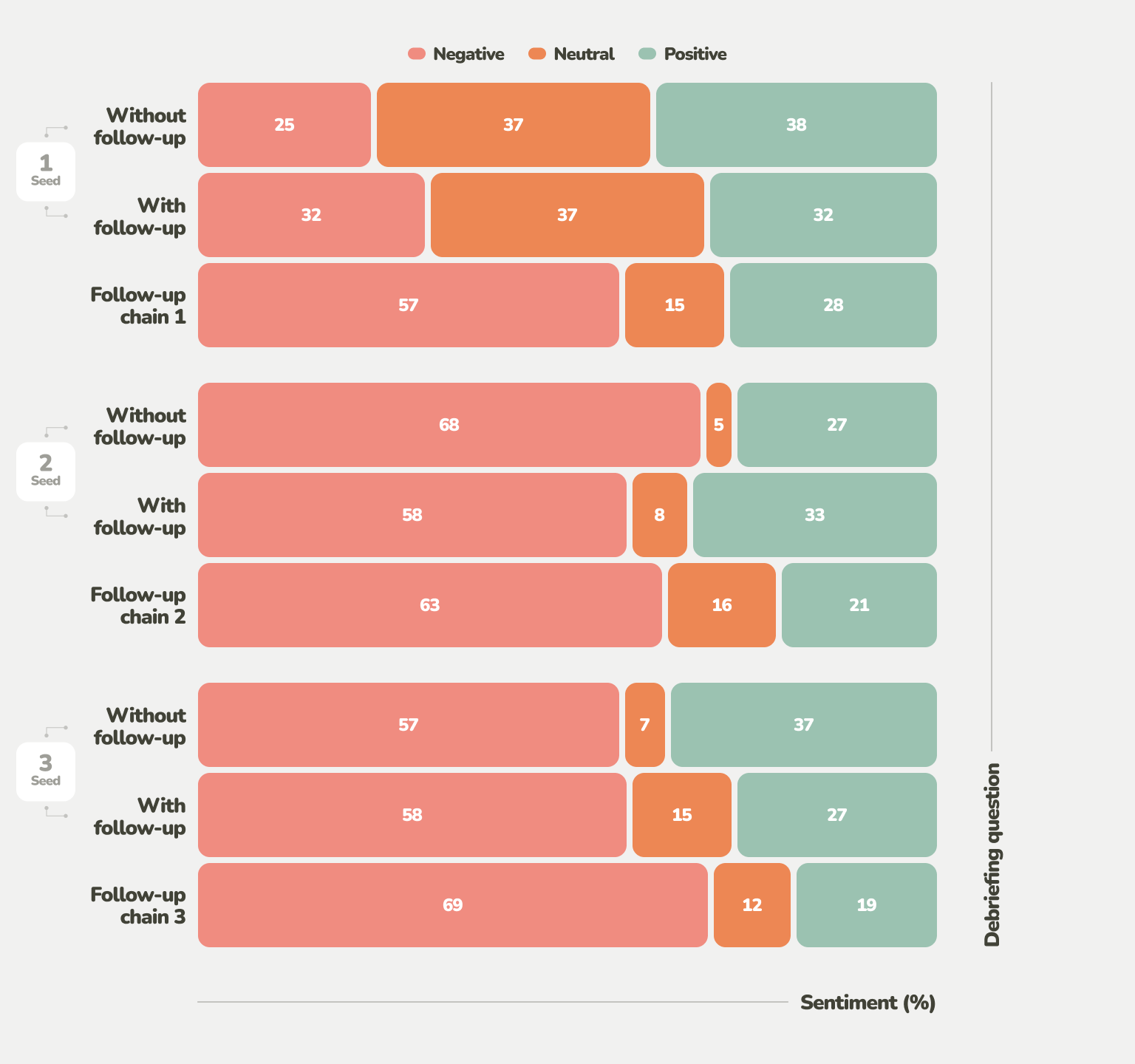
Frustration was common as participants interacted with the GPT-4-driven follow-up questions. This is rather critical, considering that frustration with the testing process can sidetrack participants from taking usability testing seriously, hinder meaningful feedback, and introduce a negative bias.
A major aspect that participants were frustrated with was redundancy. Repetitiveness, such as re-explaining the same usability issue, was quite common. While pre-defined follow-up questions yielded 27-28% of repeated answers (it’s likely that participants already mentioned aspects they disliked during the open-ended Q1), AI-generated questions yielded 21%.
That’s not that much of an improvement, given that the comparison is made to questions that literally could not adapt to prevent repetition at all. Furthermore, when AI follow-up questions were added to obtain more elaborate answers for every pre-defined question, the repetition ratio rose further to 35%. In the variant with AI, participants also rated the questions as significantly less reasonable.
Answers to AI-generated questions contained a lot of statements like “I already said that” and “The obvious AI questions ignored my previous responses.”
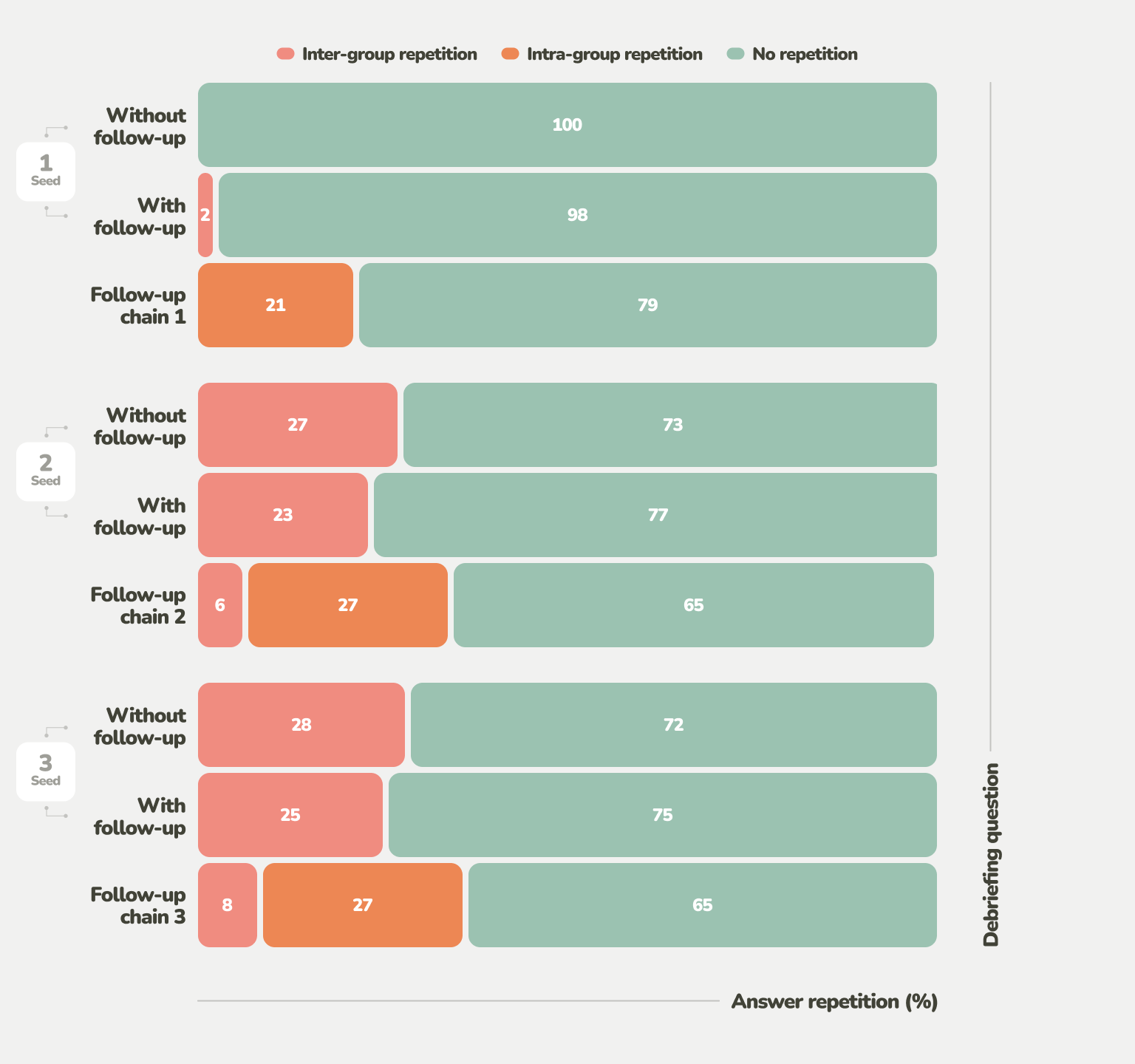
The prevalence of repetition within the same group of questions (the seed question, its follow-up questions, and all of their answers) can be seen as particularly problematic since the GPT-4 prompt had been provided with all the information available in this context. This demonstrates that a number of the follow-up questions were not sufficiently distinct and lacked the direction that would warrant them being asked.
Insights From The Study: Successes And Pitfalls
To summarize the usefulness of AI-generated follow-up questions in usability testing, there are both good and bad points.
Successes:
Generative AI (GPT-4) excels at refining participant answers with contextual follow-ups.
Depth of qualitative insights can be enhanced.
Challenges:
Limited capacity to uncover new issues beyond pre-defined questions.
Participants can easily grow frustrated with repetitive or generic follow-ups.
While extracting answers that are a bit more elaborate is a benefit, it can be easily overshadowed if the lack of question quality and relevance is too distracting. This can potentially inhibit participants’ natural behavior and the relevance of feedback if they’re focusing on the AI.
Therefore, in the following section, we discuss what to be careful of, whether you are picking an existing AI tool to assist you with unmoderated usability testing or implementing your own AI prompts or even models for a similar purpose.
Recommendations For Practitioners
Context is the end-all and be-all when it comes to the usefulness of follow-up questions. Most of the issues that we identified with the AI follow-up questions in our study can be tied to the ignorance of proper context in one shape or another.
Based on real blunders that GPT-4 made while generating questions in our study, we have meticulously collected and organized a list of the types of context that these questions were missing. Whether you’re looking to use an existing AI tool or are implementing your own system to interact with participants in unmoderated studies, you are strongly encouraged to use this list as a high-level checklist. With it as the guideline, you can assess whether the AI models and prompts at your disposal can ask reasonable, context-sensitive follow-up questions before you entrust them with interacting with real participants.
Without further ado, these are the relevant types of context:
General Usability Testing Context.
The AI should incorporate standard principles of usability testing in its questions. This may appear obvious, and it actually is. But it needs to be said, given that we have encountered issues related to this context in our study. For example, the questions should not be leading, ask participants for design suggestions, or ask them to predict their future behavior in completely hypothetical scenarios (behavioral research is much more accurate for that).
Usability Testing Goal Context.
Different usability tests have different goals depending on the stage of the design, business goals, or features being tested. Each follow-up question and the participant’s time used in answering it are valuable resources. They should not be wasted on going off-topic. For example, in our study, we were evaluating a prototype of a website with placeholder photos of a product. When the AI starts asking participants about their opinion of the displayed fake products, such information is useless to us.
User Task Context.
Whether the tasks in your usability testing are goal-driven or open and exploratory, their nature should be properly reflected in follow-up questions. When the participants have freedom, follow-up questions could be useful for understanding their motivations. By contrast, if your AI tool foolishly asks the participants why they did something closely related to the task (e.g., placing the specific item they were supposed to buy into the cart), you will seem just as foolish by association for using it.
Design Context.
Detailed information about the tested design (e.g., prototype, mockup, website, app) can be indispensable for making sure that follow-up questions are reasonable. Follow-up questions should require input from the participant. They should not be answerable just by looking at the design. Interesting aspects of the design could also be reflected in the topics to focus on. For example, in our study, the AI would occasionally ask participants why they believed a piece of information that was very prominently displayed in the user interface, making the question irrelevant in context.
Interaction Context.
If Design Context tells you what the participant could potentially see and do during the usability test, Interaction Context comprises all their actual actions, including their consequences. This could incorporate the video recording of the usability test, as well as the audio recording of the participant thinking aloud. The inclusion of interaction context would allow follow-up questions to build on the information that the participant already provided and to further clarify their decisions. For example, if a participant does not successfully complete a task, follow-up questions could be directed at investigating the cause, even as the participant continues to believe they have fulfilled their goal.
Previous Question Context.
Even when the questions you ask them are mutually distinct, participants can find logical associations between various aspects of their experience, especially since they don’t know what you will ask them next. A skilled moderator may decide to skip a question that a participant already answered as part of another question, instead focusing on further clarifying the details. AI follow-up questions should be capable of doing the same to avoid the testing from becoming a repetitive slog.
Question Intent Context.
Participants routinely answer questions in a way that misses their original intent, especially if the question is more open-ended. A follow-up can spin the question from another angle to retrieve the intended information. However, if the participant’s answer is technically a valid reply but only to the word rather than the spirit of the question, the AI can miss this fact. Clarifying the intent could help address this.
When assessing a third-party AI tool, a question to ask is whether the tool allows you to provide all of the contextual information explicitly.
If AI does not have an implicit or explicit source of context, the best it can do is make biased and untransparent guesses that can result in irrelevant, repetitive, and frustrating questions.
Even if you can provide the AI tool with the context (or if you are crafting the AI prompt yourself), that does not necessarily mean that the AI will do as you expect, apply the context in practice, and approach its implications correctly. For example, as demonstrated in our study, when a history of the conversation was provided within the scope of a question group, there was still a considerable amount of repetition.
The most straightforward way to test the contextual responsiveness of a specific AI model is simply by conversing with it in a way that relies on context. Fortunately, most natural human conversation already depends on context heavily (saying everything would take too long otherwise), so that should not be too difficult. What is key is focusing on the varied types of context to identify what the AI model can and cannot do.
The seemingly overwhelming number of potential combinations of varied types of context could pose the greatest challenge for AI follow-up questions.
For example, human moderators may decide to go against the general rules by asking less open-ended questions to obtain information that is essential for the goals of their research while also understanding the tradeoffs.
In our study, we have observed that if the AI asked questions that were too generically open-ended as a follow-up to seed questions that were open-ended themselves, without a significant enough shift in perspective, this resulted in repetition, irrelevancy, and — therefore — frustration.
The fine-tuning of the AI models to achieve an ability to resolve various types of contextual conflict appropriately could be seen as a reliable metric by which the quality of the AI generator of follow-up questions could be measured.
Researcher control is also key since tougher decisions that are reliant on the researcher’s vision and understanding should remain firmly in the researcher’s hands. Because of this, a combination of static and AI-driven questions with complementary strengths and weaknesses could be the way to unlock richer insights.

A focus on contextual sensitivity validation can be seen as even more important while considering the broader social aspects. Among certain people, the trend-chasing and the general overhype of AI by the industry have led to a backlash against AI. AI skeptics have a number of valid concerns, including usefulness, ethics, data privacy, and the environment. Some usability testing participants may be unaccepting or even outwardly hostile toward encounters with AI.
Therefore, for the successful incorporation of AI into research, it will be essential to demonstrate it to the users as something that is both reasonable and helpful. Principles of ethical research remain as relevant as ever. Data needs to be collected and processed with the participant’s consent and not breach the participant’s privacy (e.g. so that sensitive data is not used for training AI models without permission).
Conclusion: What’s Next For AI In UX?
So, is AI a game-changer that could break down the barrier between moderated and unmoderated usability research? Maybe one day. The potential is certainly there. When AI follow-up questions work as intended, the results are exciting. Participants can become more talkative and clarify potentially essential details.
To any UX researcher who’s familiar with the feeling of analyzing vaguely phrased feedback and wishing that they could have been there to ask one more question to drive the point home, an automated solution that could do this for them may seem like a dream. However, we should also exercise caution since the blind addition of AI without testing and oversight can introduce a slew of biases. This is because the relevance of follow-up questions is dependent on all sorts of contexts.
Humans need to keep holding the reins in order to ensure that the research is based on actual solid conclusions and intents. The opportunity lies in the synergy that can arise from usability researchers and designers whose ability to conduct unmoderated usability testing could be significantly augmented.
Humans + AI = Better Insights

The best approach to advocate for is likely a balanced one. As UX researchers and designers, humans should continue to learn how to use AI as a partner in uncovering insights. This article can serve as a jumping-off point, providing a list of the AI-driven technique’s potential weak points to be aware of, to monitor, and to improve on.
Leave a Reply
Want to join the discussion?Feel free to contribute!