Collective #884
Original Source: https://tympanus.net/codrops/collective/collective-884/
Have a dialog * tududi * Agree * Tailwind CSS easing classes
Original Source: https://tympanus.net/codrops/collective/collective-884/
Have a dialog * tududi * Agree * Tailwind CSS easing classes
Original Source: https://www.hongkiat.com/blog/black-friday-2024-deals-designers-agencies/
Stick a post-it on the refrigerator, mark your calendar, or tie a string around your finger to remind yourself that Black Friday is just around the corner. You don’t want to miss it. Black Friday is known for its blockbuster discounts across a wide range of products, including tools and resources for designers and developers.
These are not clearance sale discounts where businesses try to offload unpopular or outdated products. The 10 deals listed here feature top-of-the-line tools and resources that are bargains even at their regular prices.
BeTheme & BeBuilder
35% OFF
wpDataTables
Up to 70% OFF
Trafft
50% OFF Agency Licenses
Kalium
50% OFF
Mobirise AI Website Builder
98% OFF
XStore
30% OFF
GetIllustrations
40% OFF All Collections
Vectopus
30% OFF
Total WordPress Theme
50% OFF
1. BeTheme & BeBuilder – 35% OFF

BeBuilder, 700+ prebuilt websites, and a host of other features make BeTheme the fastest and most powerful WordPress and WooCommerce theme.
With a large and comprehensive selection of prebuilt websites supported by an impressive array of design and build features, BeTheme could claim to be the most extensive WordPress theme available.
With the addition of BeBuilder, it has also become the fastest. BeBuilder has been rewritten to make BeTheme faster and super stable.
You can start a page from scratch or upload a customizable prebuilt website, such as Be Store. With a little help from BeBuilder and BeTheme’s other tools, you’ll be done in no time.
Client Input: BeTheme is the best out there. Top-quality design. Support is fast and the best team ever. Flexibility and code are top-notch. I highly recommend it to everyone looking for a high-quality product!
Check out BeTheme
2. wpDataTables – Up to 70% Off

wpDataTables is the best choice for anyone creating informative tables and charts from large amounts of complex data.
wpDataTables offers an immense set of data management tools and chart-building features, while providing straightforward approaches to completing tasks.
The standout feature, Multiple Database Connections (MDC), allows users to query and join tables from different databases directly within WordPress. This is especially useful for managing and displaying large, diverse datasets.
Users have access to a library of customizable templates to speed up their work. The Responsive Statistics table template is a popular choice.
Client Input: This amazing plugin helped me a lot on my website. The developers regularly release very useful updates. The support team is highly responsive and helpful (especially Milos). They provide detailed responses and even ask for admin credentials to better investigate and fix problems.
Check out wpDataTables
3. Amelia – Up to 70% Off

The Amelia WordPress plugin is the ideal choice for any business in need of an automated appointments booking operation.
Amelia automates the entire booking process, reducing the administrative burden on staff, minimizing errors, and ensuring appointments are managed efficiently.
It’s perfect for service-oriented businesses like salons, spas, fitness centers, and healthcare providers. Amelia can even handle multiple business locations from a single platform.
Its top feature, “Packages,” allows businesses to bundle multiple services into cohesive offers. Examples include a “Bridal Package” or a “Wellness Package,” enabling businesses to tailor their offerings to meet clients’ specific needs.
Automates appointment bookings for increased efficiency.
Offers customizable templates like the Relationship Coach template to fit client needs.
Supports multiple business locations from a single platform.
The employee and customer panels streamline management and user experience.
Client Input: Really easy to set up and use. Fits in perfectly with the style of my website with the extensive customizable options. The employee and customer panels are a brilliant feature, and the support has been excellent when I needed it.
Check out Amelia
4. Trafft – 50% on All Agency Licenses

The Trafft appointment booking app simplifies your booking processes. Its White Label package offers additional growth opportunities for your business.
Trafft automates the entire appointment booking process, saving time, reducing administrative tasks, and offering clients a seamless booking experience.
The White Label offering is designed for businesses, agencies, and resellers to present Trafft’s software under their own branding. It allows users to customize the platform with their logo, brand colors, and domain name.
This option is especially valuable for agencies and resellers managing multiple clients.
One example is the Career Mastery Coaching prebuilt website, among the 10 most downloaded in 2024.
Client Input: After using Trafft for about 10 months, I can confidently say it has been a great asset for our agency and clients. The platform’s updates have made it one of the most robust tools for managing online appointments across different business types. While there are a few customization limitations, Trafft remains indispensable for effective online appointment management.
Check out Trafft
5. Kalium – 50% Off Every Plan!

The Kalium WordPress theme is recognized for its flexibility, ease of use, and features that make it ideal for building visually stunning websites.
Kalium’s standout feature is its collection of starter sites that inspire users and help them quickly create beautiful websites.
Creating a website is a simple three-step process: select a starter site, install it, and customize it using the Live Page Builder. The Photography starter site is among Kalium’s most popular options.
Kalium is a clean-coded theme that delivers fast page loading times and produces responsive, SEO-friendly sites.
It offers a White Label plan for agencies as part of its features.
Client Input: Kalium is an excellent theme for my design and strategy portfolio site. The subtle animations create a simple yet rich user experience. Their customer service is exceptional, especially the short screen videos they provide in response to my questions. They’re a great help!
Check out Kalium
6. Mobirise AI Website Builder – 98% Off

The Mobirise AI Website Builder enables you to generate a fully customizable website with just one prompt.
Mobirise AI can generate a complete website, including content and unique designs, from a single prompt. While the initial result may not be the final product, the platform provides tools like an online builder to customize the website to perfection. Once ready, you can publish the site online with one click.
Generates both website content and unique designs based on your prompt.
Accepts prompts in any language and delivers results in the same language.
Provides four different website layouts simultaneously, allowing you to choose the one that best aligns with your vision.
Client Input: “Your team has done VERY well here! From my input of one short paragraph, the entire concept of the site was understood. What was generated-including images and text-perfectly aligned with our branding and messaging. Exceptional work!”
Check out Mobirise AI Website Builder
7. XStore | Multipurpose WooCommerce Theme – 30% OFF

XStore is one of the most feature-rich and customizable WordPress and WooCommerce themes available today.
XStore stands out for its robust Full Site Builder, which many users highlight as its top feature.
Its Full Site Builder allows full customization of headers, footers, and pages such as checkout, cart, and product pages.
Features include AMP support for fast mobile performance and a selection of customizable demos, like the popular Grocery Mega Market one-page website.
Its dedicated support team is available 24/7 to provide quick and expert assistance.
XStore is designed for various user segments, including eCommerce store owners, developers, designers, and non-technical users.
Client Input: I recently had an issue with my shopping cart and contacted the support team. They resolved it within two days. It turned out to be a small conflict between the plugin and theme, which they fixed promptly and professionally.
Check out XStore
8. GetIllustrations – 40% Off on All Illustration Collections and Yearly Subscription

GetIllustrations boasts one of the largest bundles of icons and illustrations, making it a go-to resource for designers and developers.
The sheer size of its collection is a standout feature, offering over 27,000 unique hand-drawn illustrations.
All illustrations are made specifically for the web and are of high quality.
The collection spans 190 categories and 28 unique styles.
Every illustration is fully editable and can be recolored to suit your needs.
Illustrations are available in SVG, PNG, and Vector AI formats.
An example is the Halftone Doodle Character package, which features 235 illustrations and is a customer favorite.
Use coupon code BLACK2024 to enjoy a 40% discount during Black Friday.
Client Input: Ramy and the GetIllustrations team are fantastic. Their customer service is top-notch, just like their designs. I’ve worked with them to create custom additions to existing kits, and they’ve been excellent. Looking forward to continuing our partnership!
Check out GetIllustrations
9. Vectopus – 30% Off on All Plans

Vectopus offers an extensive UI library of assets for designers, developers, marketers, creators, and influencers.
Its top feature is a library of over 400,000 premium icons and illustrations, known for their variety and quality.
Customers appreciate the detail and quality of Vectopus’ assets.
Creators receive 70% of sales revenue for their designs, incentivizing them to produce high-quality work.
The consistent quality of assets means you won’t waste time searching for better alternatives.
Icons and illustrations can be edited directly on the Vectopus website.
Client Input: Great product, would definitely recommend!
Check out Vectopus
10. Total WordPress Theme – 50% Off

The Total WordPress theme is a comprehensive tool featuring ready-made demos and an enhanced WPBakery builder.
Users consistently praise its flexibility and the high degree of customizability it offers.
Intuitive front-end page building capabilities and unlimited styling options using the live customizer.
Pre-made patterns and sample demos help users of all skill levels get started quickly. The Bolt demo is among the most popular, easily customized for various purposes.
Developers appreciate the unique page-building speedup mode, focus on performance, and developer-friendly hooks, filters, and snippets.
Client Input: Lightweight, powerful, easy to use, and capable of anything! Post Cards are the best. Love it!
Check out Total WordPress Theme
Black Friday Reminder
Black Friday is just around the corner. If you’re a designer or developer and this is your first Black Friday experience, you’re in for some exciting deals. At least one of the listed offers will likely save you money, enhance your workflow, or give you access to valuable tools and resources.
Don’t put this list aside where it might be forgotten. The next opportunity for savings like these won’t come around until next year. If one or more of these top 10 Black Friday deals catches your attention, treat yourself to an early holiday gift!
Just to recap:
Product Name
Summary
Black Friday Deal
Be Theme
BeTheme with BeBuilder is the fastest WordPress and WooCommerce theme on the market.
35% Off
wpDataTables
The best WordPress plugin for creating tables and charts from complex data.
Up to 70% Off
Amelia
Perfect for businesses needing an automated appointment booking system.
Up to 70% Off
Trafft
White Label package for agencies to rebrand Trafft as their own.
50% Off on Agency Licenses
Kalium
A flexible and user-friendly theme for all levels of users.
50% Off Every Plan
Mobirise AI
Generates a customizable website with a single prompt.
98% Off
XStore
A feature-rich and customizable WooCommerce theme.
30% Off
GetIllustrations
Offers a massive collection of hand-drawn icons and illustrations.
40% Off
Vectopus
Provides over 400,000 premium icons and illustrations.
30% Off on All Plans
Total Theme
Comprehensive WordPress theme with intuitive features and excellent support.
50% Off
The post 10 Top Black Friday 2024 Deals for Designers and Agencies appeared first on Hongkiat.
Short and sweet with a full stop.
Original Source: https://www.creativebloq.com/3d/womps-cool-new-feature-will-3d-print-your-creations-and-get-them-delivered-to-your-door
This opens up plenty of new avenues for artists and creatives, but I don’t understand the pricing.
Original Source: https://www.creativebloq.com/design/3-things-the-design-industry-needs-to-improve-according-to-experts
We need to strike a balance between innovation and empathy.
Original Source: https://www.creativebloq.com/tech/tvs/frame-tv-black-friday-deal
And you can save $1,500 on the 85-inch model too.
Original Source: https://tympanus.net/codrops/2024/11/21/from-product-to-cart-adding-guiding-animations-to-the-shopping-experience/
An in-depth tutorial on how to create an engaging animation where items move from the product gallery to the shopping cart.
Original Source: https://www.sitepoint.com/developers-guide-to-ai-chatbot-authorization/?utm_source=rss

Read The Developer’s Guide to AI Chatbot Authorization and learn AI with SitePoint. Our web development and design tutorials, courses, and books will teach you HTML, CSS, JavaScript, PHP, Python, and more.
Continue reading
The Developer’s Guide to AI Chatbot Authorization
on SitePoint.
Original Source: https://webdesignerdepot.com/a-closer-look-at-wordpress-6-7-rollins/
The WordPress 6.7 release, named “Rollins” honors jazz legend Sonny Rollins, renowned for his improvisational mastery and innovative contributions to jazz.
His iconic compositions, like “St. Thomas” and “Oleo,” reflect his bold, exploratory style, paralleling WordPress’ mission to empower creativity and innovation. This update embodies Rollins’ spirit of pushing boundaries, offering new features and enhancements to inspire digital expression.
Twenty Twenty-Five Theme
The new default theme, Twenty Twenty-Five, is built to offer unparalleled flexibility for various website types. Whether you are creating a personal blog, a portfolio, or a professional business site, this theme provides robust design tools that leverage the full power of the block editor.
It includes multiple pre-designed block patterns, diverse style variations, and rich color palettes, allowing users to create visually stunning and functional websites quickly and easily.

Zoom Out Mode
Zoom Out Mode is a revolutionary addition to the site editing experience. It allows users to view and edit their website from a broader perspective, making it easier to arrange and modify entire sections and patterns. This feature is especially useful for managing complex layouts, giving users a clear overview of their site’s structure and design while streamlining the process of making adjustments.
Dynamic Content Integration
WordPress 6.7 introduces the ability to connect blocks directly to dynamic content sources, such as custom fields, from within the editor.
This new functionality simplifies the creation of dynamic websites, such as portfolios, blogs, and ecommerce stores, without requiring extensive coding knowledge. It also enhances compatibility with popular tools like Advanced Custom Fields (ACF), making it easier to create and manage dynamic content.
Advanced Typography Control
The advanced typography settings in WordPress 6.7 give users greater control over text design. With the ability to create and manage custom font size presets, as well as utilize fluid typography for responsive text scaling, users can ensure that their websites look polished and consistent across all devices. This update also enhances the overall design flexibility and user experience.

Performance Enhancements
Performance improvements are a highlight of WordPress 6.7, focusing on speed and stability. Block patterns and templates now load faster, and previews in data views have been optimized for efficiency. Compatibility with PHP 8 and higher versions has been improved, and the HTML processing engine has been refined for faster rendering and better performance overall.
Accessibility Improvements
Accessibility has been a major focus in this release, with over 65 fixes and enhancements aimed at making WordPress more inclusive. These updates include improved keyboard navigation in the editor, better labeling and instructions for various interface components, and fixes to ensure that assistive technologies can interact with WordPress more effectively.
HEIC Image Support
WordPress 6.7 adds native support for HEIC image files, a format widely used by iPhone cameras. This update makes it easier to upload and use high-quality, space-efficient images across all blocks, expanding the platform’s media capabilities and providing more options for visual content creation.

Query Loop Block Refinements
The Query Loop block, a powerful tool for displaying dynamic content, has been refined for ease of use. Automated default settings simplify the setup process, while key customization options have been consolidated for greater clarity. These improvements make the Query Loop block more accessible to beginners while retaining its flexibility for advanced users.
Preview Dropdown Extensions
Developers now have the ability to extend the preview dropdown menu with custom preview options. This feature enables users to test and view content in new contexts, such as specific device sizes or custom configurations, providing greater flexibility and control over the content preview process.
Background Customization
Enhanced background customization tools allow for the application of consistent styles across a site. These global settings ensure a unified design aesthetic while offering greater creative control over the appearance of pages and individual blocks. This feature simplifies the process of maintaining cohesive site-wide designs.
Site Editor Page View Enhancements
The Site Editor’s page view has been enhanced to include advanced filtering options, enabling users to display specific categories such as Published, Draft, or Scheduled pages. This update improves navigation and organization within the editor, making it easier to manage content effectively.

Template Registration API
The new Template Registration API simplifies the process of creating and managing custom templates. It allows plugins to introduce custom templates independent of themes, supports theme overrides, and enables the creation of templates tailored to specific categories or content types.
Expanded Design Tools
WordPress 6.7 expands the range of design tools available for individual blocks. New options, such as shadows and borders, give users more creative control over block appearance. These tools enable the creation of visually distinct and professional-looking websites without the need for external design software.
Interactivity API Improvements
The Interactivity API has been updated with new capabilities for robust state management and improved integration with JavaScript. These enhancements make it easier for developers to build dynamic, interactive web experiences while addressing previous bugs to ensure smoother operation.
WordPress 6.7 is a testament to the platform’s commitment to continuous improvement and innovation. It provides tools and features that cater to a diverse range of users, enabling them to build more functional, visually appealing, and high-performing websites.
Download WordPress 6.7 “Rollins” here
Original Source: https://www.hongkiat.com/blog/use-chatgpt-in-chrome-arc-browser/
OpenAI’s ChatGPT Search now provides live internet results, bringing the latest information to your ChatGPT responses. This update makes ChatGPT even more useful for up-to-date queries, perfect for news, trends, and other time-sensitive topics.
In this article, we’ll see how to set up a search shortcut in Arc or Chrome for easy ChatGPT access.
In Chrome
Chrome is one of the most popular browsers, and it’s easy to set up a search shortcut for ChatGPT.
First, you can simply install the ChatGPT Search extension from the Chrome Web Store. Once installed, you can use the extension to search ChatGPT directly from your browser’s search bar.
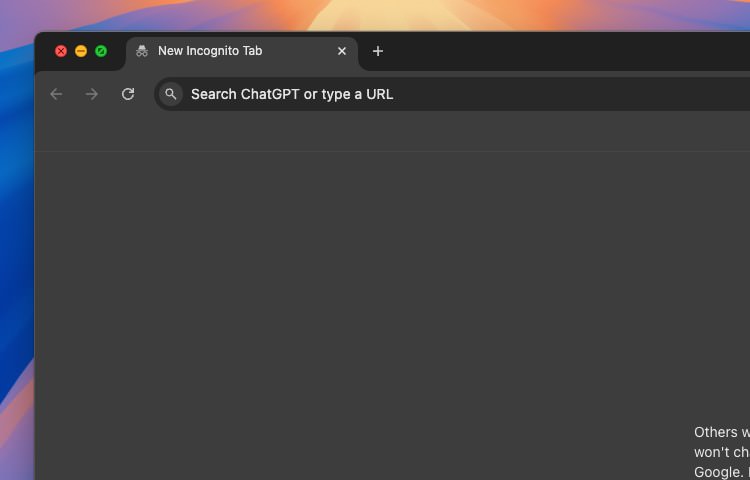
However, this will override the Chrome address and search bar to use only ChatGPT. So, whatever you type there will be sent to ChatGPT. If you want to keep the default search engine and use ChatGPT only when you need it, you can set up a custom search engine in Chrome.
Go to the Settings menu in Chrome
Navigate to Search Engine > Manage search engines and site search
Under the Site search section, add a new search engine, and fill in the details as follows:
Name: ChatGPT
Shortcut: @chatgpt
URL: https://chatgpt.com/?hints=search&q=%s

Once the ChatGPT search is added, you can type in the shortcut and hit Tab. This will change the search bar to the ChatGPT input field. You can now type your ChatGPT query, which will direct the tab with the response from ChatGPT.
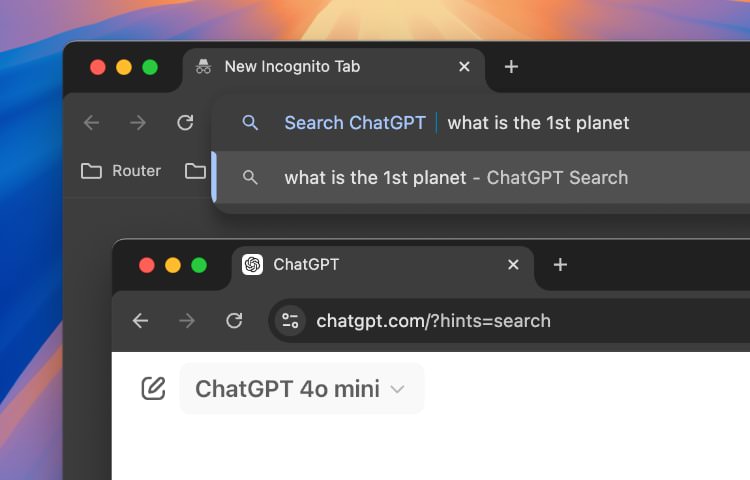
In Arc
Arc has been my favorite browser for a while now. It is based on Chrome with some added great features that allow you to better organize your browsing experience in Arc.
One of my favorite features is the Command Bar with the Command / Control + T shortcut. It is similar to the Command Palette in VS Code, but for the browser. You can use it to search, navigate, and perform actions in the browser.
By default, the Command Bar is set to use Google search. But you can change it to use ChatGPT for your searches. Here’s how:
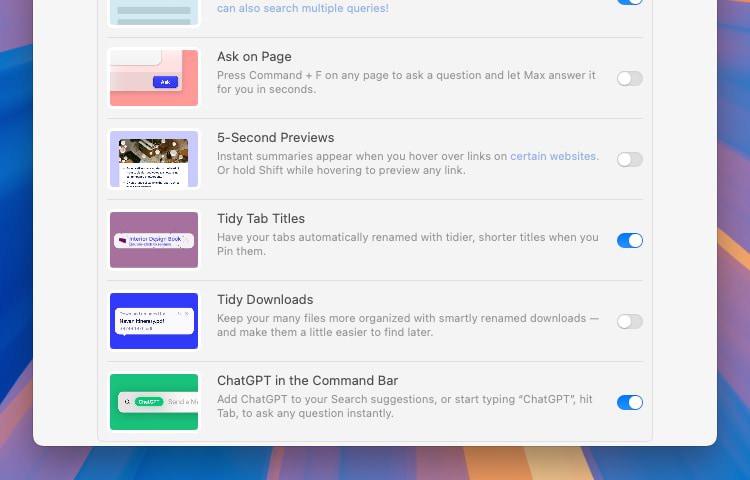
Go to the Settings menu in Arc
Navigate to Max tab section
Toggle on the ChatGPT in the Command Bar option
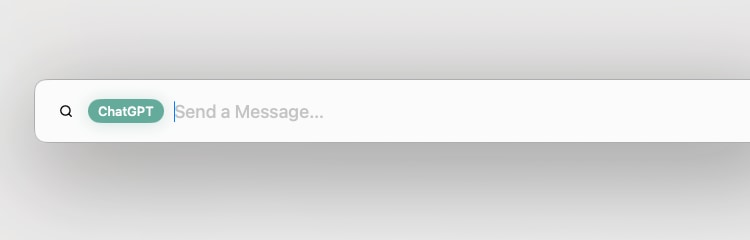
Once you have it enabled, launch the Command Bar, type “ChatGPT” and hit Tab. This will change the Command Bar to the ChatGPT prompt. You can now type your query, which will open a new Arc Browser tab with the response and result from ChatGPT.
Wrapping up
With these simple steps, you can easily set up ChatGPT search in Chrome and Arc Browser. This makes it convenient to access ChatGPT for quick queries and responses without leaving your browser. Enjoy the seamless integration of ChatGPT with your browsing experience!
The post How to Use ChatGPT Directly in Chrome and Arc Browser appeared first on Hongkiat.

