Silence, brand: Why McDonald's meme marketing is a flop
Original Source: https://www.creativebloq.com/creative-inspiration/advertising/mcdonald-s-meme-ad
It’s coming across as disingenuous and desperate.
Original Source: https://www.creativebloq.com/creative-inspiration/advertising/mcdonald-s-meme-ad
It’s coming across as disingenuous and desperate.
Original Source: https://www.creativebloq.com/design/branding/why-coca-cola-and-the-paris-olympics-have-decided-to-hug-it-out
The campaign could be a sign of things to come this summer.
Original Source: https://tympanus.net/codrops/2024/07/15/how-to-create-a-liquid-raymarching-scene-using-three-js-shading-language/
An introduction to Raymarching using the power of Signed Distance Fields (SDFs) and simple lighting to create a liquid shape effect.
Original Source: https://www.hongkiat.com/blog/raising-your-rates/
As a freelancer, raising your rates is crucial not just for your growth as a creative business owner but also for improving the quality of clients you attract. If you work for lower rates, you’ll find it harder to attract high-profile clients. Why? Because top-tier clients usually associate lower prices with lower quality. They may assume you’re not very good at what you do.
Our brains tend to devalue products or services that are priced too low, even if they’re actually valuable. This is why it’s important not to be perceived as the cheap option if you’re a designer.
Once you’re seen as the budget choice, it can be tough to change that perception. But don’t worry, we’ll guide you on how to overcome this challenge so you can attract the quality clients you deserve.
How to Become A High-Demand Designer
.no-js #ref-block-post-15021 .ref-block__thumbnail { background-image: url(“https://assets.hongkiat.com/uploads/thumbs/250×160/high-demand-designers.jpg”); }
How to Become A High-Demand Designer
Discover the high demand for designers in today’s job market. Learn which skills are most sought after and… Read more
Ask Not What Your Client Can Do For You…
Here’s how most freelance designers attempt to raise their rates. They start with a nice, slightly timid email that goes something like this:
Hi so-and-so, just wanted to let you know I’ll be raising my rates.
Sorry to have to do this, but well, you know how it is.
Okay, maybe it’s not exactly in those words, but that’s a general idea.
There’s a reason why this doesn’t work well with many clients, and it’s not because they’re all cheapskates who don’t understand the value of your work. The reason this approach rarely succeeds is that your client has mentally locked you in as being “worth” a certain amount of money.
Why Are People Reluctant to Invest in Quality Design?
.no-js #ref-block-post-15166 .ref-block__thumbnail { background-image: url(“https://assets.hongkiat.com/uploads/thumbs/250×160/paying-for-good-design.jpg”); }
Why Are People Reluctant to Invest in Quality Design?
Learn the benefits of paying for good design and how it can improve your brand’s image and customer… Read more
What’s Your Value?
They probably haven’t done this maliciously, but regardless, that’s how they see you. Your value is tied to X amount of dollars. To overcome this, you need to approach your clients from a value-based perspective rather than a money-based one.
Instead of just announcing that you’re raising your rates, think about the kind of value you can provide your clients that would make them willing to pay you more.
Client Surveys
If you don’t know the answer, ask them to fill out a client survey. If you’ve done client surveys before, make this one a bit different. In this survey, you’re trying to figure out what your client’s major concerns are in their business.
Focus on what they need and ask what you could do to make their business more successful.
A Little Bit More
After you’ve learned what, specifically, your client is looking for in terms of value, it’s time to send them an email detailing your rate change.
Gentle Reminder
First, remind your client exactly what you’ve already done to provide value. This is crucial to establishing yourself as a freelancer who has been an important asset to your client’s success. (This is your time to brag, so be specific). You didn’t just design a website, a logo, or a branded image. You revitalized their business: helped them improve their traffic flow, increased their visibility, and helped them make more money.
Based on your survey results, which hopefully you’ve done with all of your current and recent clients, you will have gotten a sense of the general things the majority of your clients are looking for. The next thing to include in your email is some sort of acknowledgment of this need.
Trial Run
This will be your ‘bait’, so to speak – you’re going to reel the client in on the strength of this next offer. If your clients are really looking for a specific way to get more Twitter followers, for example, try offering them that one service, free of charge. That’s right, this is one time where working for free will actually be a benefit.
The purpose of this offer is not to give away valuable services for free. You’ll want to restrict it to just one service offer, for a limited number of hours. Just a taste of the value they’ll be getting at your newly adjusted rate.
If this is a good client whom you’ve had a good run with, be sure to let them know that. You’ve helped them with some very important parts of their business – their online presence, their brand, their reputation with their customers. This makes you and your client part of the same money-making team.
Make The Announcement
So now you’ve detailed exactly what you’ve done for your client so far. You’ve offered to provide even more value going forward. You’ve laid the foundation to announce your new higher rate. Be clear about what your rates are now, and what they’re going to be in the near future. This is no time to get wishy-washy or timid, no excuses or apologies are necessary – or appropriate.
You work very hard to provide a valuable service to your clients. If you really believe you deserve a raise, your client will believe it as well. If you don’t believe you deserve a raise, they’ll believe that also. So be firm and give a solid ‘no’ to any offers to haggle. If this means you lose a client or two, then so be it. Perhaps you can refer them to another service provider who is more in line with their price range.
The Icing On The Cake
But don’t just stop there! There’s one more important step to clinching the deal and making your clients thrilled to give you more money. The final part of your email ought to include some sort of plan of action you intend to take in the next 2 weeks, 30 days, 3 months, or whatever block of time you feel is appropriate to the work you do.
Give your client something to look forward to, so that they can immediately see the benefit to keeping you around. How long would it take them to find another designer as organized and dedicated as you are? If they are a valuable client, they won’t be interested in finding out.
Why take time out of their schedule to find someone cheaper to do an inferior job when they have a superstar offering them the perfect solution right now? When your clients know they are getting real value, saving real time, and making real revenue, they’re less likely to quibble on price.
In Conclusion
If all of this sounds like more work than you may have signed up for in the beginning, that’s a good indication to re-evaluate your relationship to providing value for your clients. If you think about it, you’re already getting paid a certain rate for the type of work you do.
Logically, there is no reason to request more money for the exact same thing you’re doing now – going above and beyond your current level is the only way to confidently ask for a raise. As the saying goes, the more you give, the more you get; and nowhere is that more true than in the freelancer-client dynamic.
The post Freelancers: Tips for Increasing Your Rates appeared first on Hongkiat.
Original Source: https://abduzeedo.com/dorica-lamp-greek-styled-industrial-design
DORICA Lamp: Greek Styled Industrial Design

abduzeedo0712—24
Discover DORICA, the wireless rechargeable table lamp blending classical beauty and modern tech, redefining industrial design.
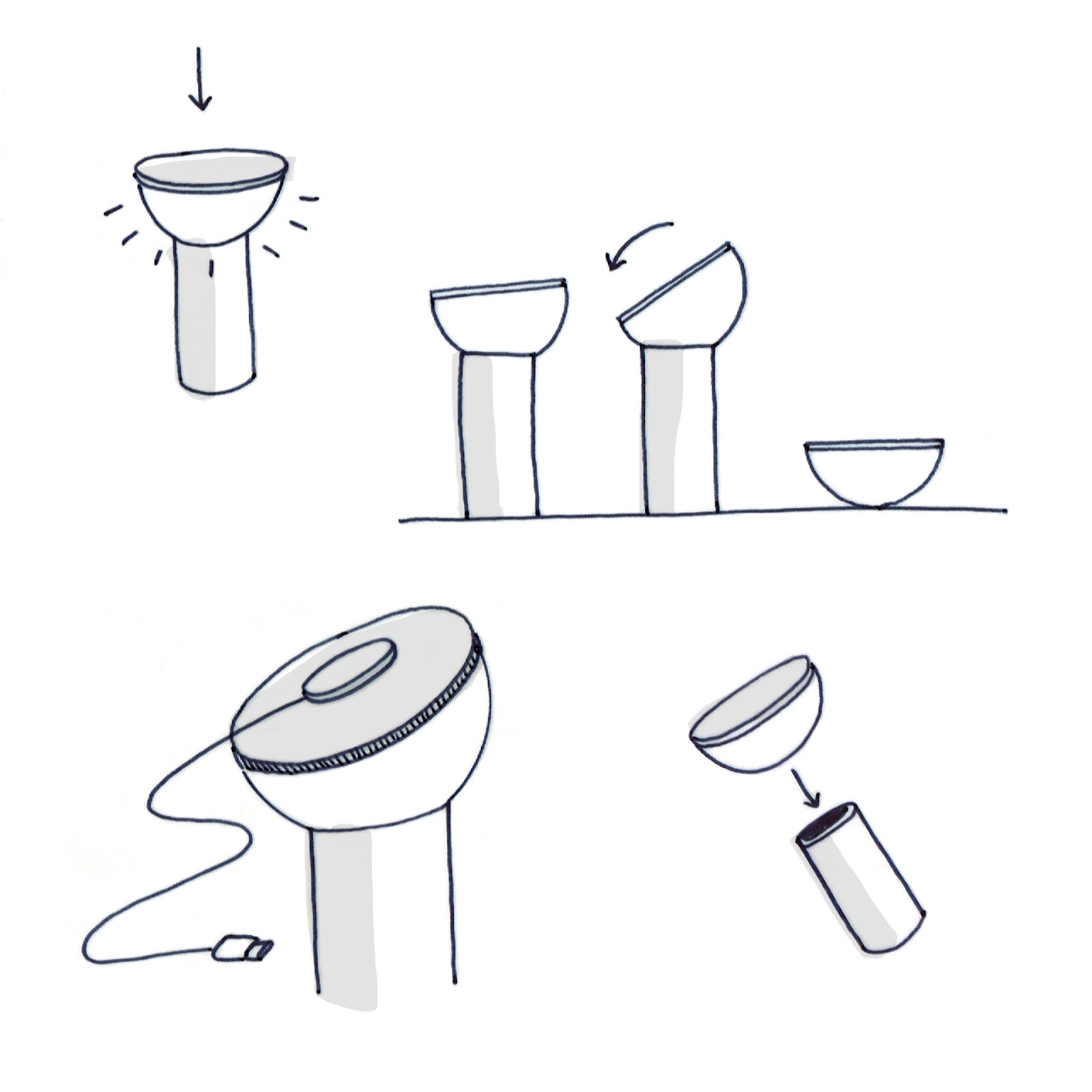
Introducing the DORICA wireless rechargeable table lamp, a stunning innovation in industrial design. Created by OSMO Design, DORICA draws inspiration from the ancient Greek Doric order, blending classical elegance with cutting-edge technology to create a versatile and aesthetically pleasing lighting solution. For more details, visit DORICA Lamp on Behance.
Past Glory, Present Inspiration
The design of DORICA is rooted in the timeless elegance of the Doric order, the oldest and most iconic of the Greek architectural styles. The lamp’s minimalist form—a combination of a cylinder and a half-sphere—pays homage to this classical inspiration while offering modern functionality. The cylinder represents stability and permanence, while the half-sphere symbolizes dynamism and freedom of movement.
Shaping Light: The Half-Sphere’s Illuminating Versatility
The primary goal behind DORICA’s design was to create an intimate, personal product that adapts to various lighting needs and situations. The half-sphere, which acts as the lamp’s illuminating body, can be oriented in multiple directions, providing flexible lighting options. This feature makes DORICA not only versatile but also immediately recognizable.
Classical Beauty Meets Modern Tech
The innovation of DORICA extends beyond its design aesthetics. The half-sphere can detach from the base and function independently, thanks to a magnet that allows it to attach to any metal surface. This feature enhances its versatility, enabling it to be used both indoors and outdoors, with or without its base. Such flexibility is a hallmark of exceptional industrial design, blending form and function seamlessly.
Versatility in Use
DORICA’s adaptability is one of its most striking features. Whether it’s used as a traditional table lamp or detached to serve as a portable light source, DORICA meets diverse lighting needs with ease. The ability to attach the half-sphere to various metal surfaces expands its utility, making it suitable for a range of environments—from cozy indoor settings to vibrant outdoor spaces.
The DORICA wireless rechargeable table lamp by OSMO Design is a shining example of how industrial design can merge historical inspiration with modern innovation. Its minimalist yet impactful form, versatile functionality, and user-centered design make it a standout piece in any setting. DORICA not only illuminates spaces but also enhances the aesthetic appeal of any environment it graces.
For more insights into the DORICA lamp and its exceptional design, explore the project on Behance.
Industrial design artifacts


Original Source: https://www.hongkiat.com/blog/spoof-location-iphone-methods/
Do you ever feel like taking a digital break from being constantly pinned on the map? Whether it’s family or friends keeping tabs through the Find My app, sometimes you just need a moment of privacy – or perhaps you’re planning a surprise and need to keep your actual whereabouts under wraps.
Well, this post is all about that. Read on to find out more!
Advanced Method: Use Spoofing Software
The first method on our list involves using the iMyFone AnyTo app. This software allows you to spoof your location easily, without needing much technical knowledge. Importantly, there’s no need to jailbreak your iPhone.
Here’s a guide on how to use iMyFone AnyTo to achieve this:
Download iMyFone AnyTo for your operating system and install it on your computer.
Open iMyFone AnyTo and click “Get Started.” Connect your iPhone to your computer using an original or MFi-certified cable. Make sure to trust the computer on your iPhone and enter your passcode if needed.

Select the cable connection for stability. Ensure your iPhone doesn’t lock automatically by setting Auto-Lock to “Never” under Settings > Display & Brightness > Auto-Lock.
Once your device is connected, a map will appear. Enter the Teleport Mode, type the name or coordinates of your desired location, or simply pin a location on the map.

Click the “Move” button to update your location to the new destination.
Once you’ve set your desired fake location or route, all location-based apps on your iPhone, including Find My, will reflect this change. This ensures that any app that uses your location data will now show your new, spoofed location.
Additional Features of iMyFone AnyTo
Beyond simply changing your location, iMyFone AnyTo also lets you design custom routes and easily revert to your original location.
Creating a Route
Two-Spot Mode: Transition from your current spot to a chosen destination with customized movements to simulate realistic travel patterns.

Multi-Spot Mode: Design a route involving multiple stops, enhancing the realism of your movement simulation.
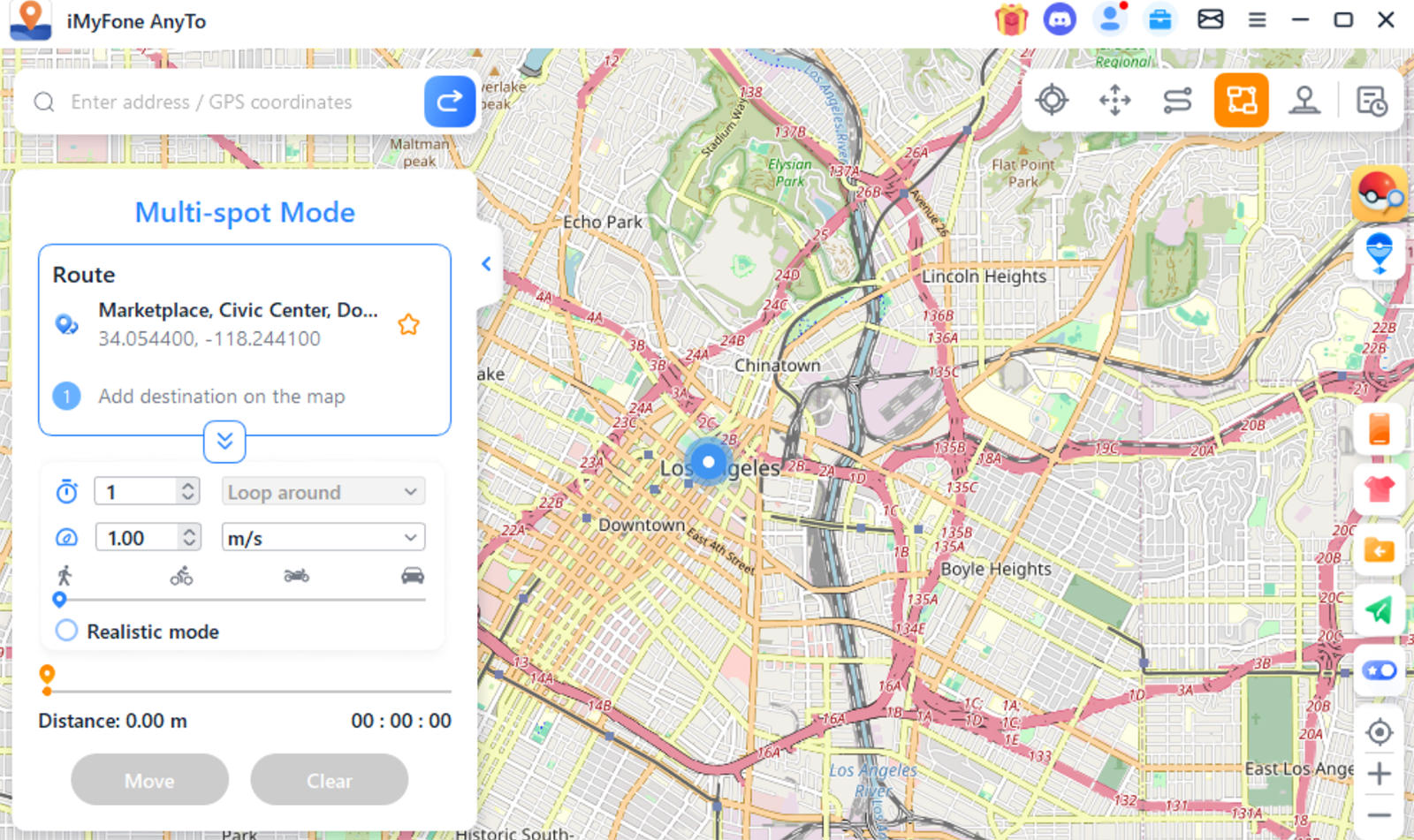
Resetting Your Location
To revert to your original location, simply click the “Reset Location” button on the software’s dashboard. Should your location not update immediately, a restart of your device will ensure the changes take effect.
Here’s a video to learn more about the app:
Method 2: Disable “Share My Location”
Turning off your shared location is perhaps the easiest method to hide your device’s location. By disabling this feature, anyone you have previously shared your location with will no longer be able to see it. Follow these steps to turn off “Share My Location” on your iPhone:
Navigate to the Settings app.
Scroll to “Privacy & Security” and select it.
At the top, tap “Location Services.”
Find and tap “Share My Location.”
Switch the toggle to off.
Method 3: Enable Airplane Mode
Enabling Airplane Mode is perhaps a more straightforward approach to hiding your location and requires fewer steps compared to disabling “Share My Location.”
When Airplane Mode is activated, your iPhone disconnects from all networks, effectively freezing your last known location. To resume normal tracking, simply swipe down and turn off Airplane Mode.
Method 4: Use Another Apple Device
If you have an additional Apple device, you can configure it to share its location instead of your primary iPhone.
Here’s how to set it up:
Open the Find My app on the secondary device.
Tap the “Me” tab at the bottom right corner.
Enable location sharing from this device, not your primary iPhone.
By doing this, the location displayed to others will be that of the secondary device, allowing you to maintain privacy about your actual whereabouts.
Conclusion
There you have it – four discreet ways to freeze your location on an iPhone. These methods allow you to effectively freeze or spoof your iPhone’s location without raising suspicions.
Quick fixes like turning off “Share My Location” or enabling Airplane Mode are simple yet effective; for other scenarios, such as creating a route, an app like iMyFone AnyTo may come in handy.
The post Top 4 Methods to Spoof Location on iPhone appeared first on Hongkiat.
Original Source: https://www.hongkiat.com/blog/laravel-alternatives/
While Laravel is popular for its rich features and ease of use, there are many other PHP frameworks that might better suit your needs.
In this article, we will explore 10 great alternatives to Laravel, each with its own unique strengths and features. Whether you’re looking for something lightweight, highly customizable, or built for high performance, I believe there’s an option here for you.
Without further ado, let’s jump in to see the full list.
FrameworkX

FrameworkX is a lightweight PHP microframework created by Christian Luck, designed for building high-performance, real-time applications. It uses an event-driven, non-blocking architecture based on ReactPHP components, making it ideal for high-concurrency and real-time updates such as chat apps and live notifications.
Unlike Laravel, FrameworkX is minimalistic and doesn’t include built-in features like an ORM, templating engine, or expressive helper functions. This minimalism provides flexibility, allowing you to choose and integrate your own preferred libraries for templating, database abstraction, and other functionalities.
Check out our post on how to get started with FrameworkX.
PHP Minimum Requirement: 7.1
PROS
High-performance and real-time capabilities
Lightweight and minimalistic
Event-driven architecture based on ReactPHP components
CONS
Requires more manual integration to incorporate other features
Less expressive syntax compared to Laravel
Requires some getting used to if you are not familiar with event-driven architecture
Visit FrameworkX
CodeIgniter

CodeIgniter is a lightweight PHP framework originally developed by EllisLab and now maintained by the CodeIgniter Foundation. Similar to Laravel, it follows a more structured architecture and offers many essential features for an MVC framework.
However, it lacks some of Laravel’s expressive syntax, like the Eloquent ORM and built-in front-end integrations. Despite this, its simplicity makes it easy to pick up for developers with fair experience in PHP, object-oriented programming, and MVC concepts.
PHP Minimum Requirement: 8.1
PROS
Lean, minimal, and easy to learn
Good documentation and community support
Built-in page cache module
CONS
Smaller ecosystem compared to Laravel
No built-in ORM
No built-in templating engine like Blade
Lack of expressive syntax
Lack of built-in front-end integration
Visit CodeIgniter
Laminas

Laminas, formerly known as Zend Framework, is a PHP framework designed for enterprise-grade applications. It offers a collection of professional PHP packages for developing web applications and services. These components are framework-agnostic and comply with PSR (PHP Standard Recommendations), so they can be used outside Laminas.
Laminas differs significantly from Laravel. While Laravel focuses on developer experience, rapid development, and includes full-stack features built-in like Eloquent ORM and Blade, Laminas offers a more modular approach. It provides more flexibility but may require more configuration and setup time compared to Laravel.
PHP Minimum Requirement: 8.1.0
PROS
Highly modular and customizable
Strong focus on security and enterprise-level features
Scalable and suitable for large-scale applications
First-party ecosystem: Mezzio, API Tools, and MVC framework
CONS
Less expressive syntax
No built-in CLI, ORM, and templating engine
May require more manual integration for some of its components
Visit Laminas
Slim

Slim is a PHP micro-framework developed by Josh Lockhart that focuses on essentials like routing, middleware, and HTTP request handling.
Unlike Laravel’s full-stack approach, Slim does not include a full MVC layer, a native template engine, or a database abstraction layer, so you’ll need to use your own preferred libraries and components if you need one.
This minimal footprint, however, makes Slim a great choice if you’re looking to create lightweight RESTful APIs or microservices.
PHP Minimum Requirement: 8.1
PROS
Lightweight and fast
Simple and easy to use
Ideal for small to medium-sized projects and APIs
Extensible with middleware and third-party components
CONS
Limited built-in features compared to full-stack frameworks
Requires additional libraries for ORM and templating engine
Visit Slim
Nette

Nette is a mature and feature-rich PHP framework created by David Grudl. It offers a comprehensive set of tools and components for building web applications, including a powerful templating engine called Latte, forms handling, database abstraction, and many other components.
Nette differs from Laravel in its focus. While Laravel prioritizes developer experience with features like Eloquent ORM, Blade, and the Artisan CLI included and pre-configured, Nette provides its first-party components separately. This allows you to choose which tools and libraries you’d need to include in your project. Despite its modularity, it provides a base application or skeleton to help you quickly start your projects.
PHP Minimum Requirement: 8.1
PROS
Matured and battle-tested framework, built since 2004
Comprehensive set of tools and components for building websites
Provides base or skeleton with flexible structure
Powerful templating engine: Latte
Good documentation and community support
CONS
Less opinionated than Laravel
Requires more manual configuration and setup
Smaller ecosystem compared to Laravel
Visit Nette
Phalcon

Phalcon is a unique PHP framework. Unlike the others, it is delivered as a C extension. Designed to optimize speed by bypassing PHP’s interpreter and leveraging lower-level system resources directly, it includes full-stack features like a first-party ORM library, router, caching, and more.
Phalcon sets itself apart from Laravel with its architecture as a C extension. Unlike Laravel, which is implemented purely in PHP, Phalcon requires installing a PHP extension, so you need to be comfortable with commands like apt and PHP .ini configuration files to enable the extension. I think Phalcon is ideal for projects where performance is critical and can handle heavy workloads with minimal overhead.
PHP Minimum Requirement: 8.0
PROS
High performance due to its nature as a C extension
Full-stack features included like ORM, caching, dependency injection, i18n, templating engine, and router
CONS
Requires installing a PHP extension, which can be overwhelming for beginners
Much smaller ecosystem compared to Laravel
Visit Phalcon
Yii2

Yii2 is a PHP framework created by Qiang Xue, offering extensive features like an ORM, RESTful API, debugging tools, a boilerplate generator, and much more.
Yii2, I think, is quite similar to Laravel in its approach and principles. Unlike some frameworks where features are in separate modules, Yii2 has them built-in and pre-configured with MVC architecture. It also provides a starter kit with basic interfaces and functionality, similar to Laravel Breeze. Additionally, Yii2 also provides solid first-party modules like the Mailing module, i18n module, Docker for localhost, a first-party templating engine, and front-end integration with Bootstrap.
PHP Minimum Requirement: 7.3
PROS
Support for PHP 7.3, if you still need it
One of the earliest frameworks in PHP. It’s solid and battle-tested
First-party modules and tools included and pre-configured
Gii, one of its unique features to generate codes
Great documentation and community support
CONS
Smaller ecosystem compared to Laravel
Less expressive syntax compared to Laravel
Has a somewhat unusual namespacing pattern
Visit Yii2
Spiral

Spiral is a high-performance PHP framework developed by the team at Spiral Scout. It is built around RoadRunner, a PHP application server written in Go, which enables it to handle heavy workloads efficiently and reduce the overhead that may commonly occur in traditional PHP applications.
Spiral uses a classic MVC approach and features a routing system similar to Laravel. However, it exclusively runs with RoadRunner, offering twice the performance out of the box compared to typical PHP MVC frameworks. It also includes components like JOBS, Worker, and BirdDog, specifically optimized for RoadRunner, leading to more optimized and faster applications.
PHP Minimum Requirement: 8.1
PROS
High performance due to its integration with RoadRunner
General-purpose framework that allows you to build MVC, CQRS, Event-Driven, and CLI apps
First-party ORM library, CycleORM, which I think looks neat!
CONS
Some learning curves, probably requires learning RoadRunner and how it works
Smaller ecosystem compared to Laravel
Visit Spiral
Neutomic

Neutomic is a lightweight PHP framework designed for environments that require long-running processes. Built on top of RevoltPHP, Neutomic supports event-driven, non-blocking I/O operations, making it efficient for handling concurrent tasks.
Neutomic differs from Laravel in its use of an event-driven, non-blocking architecture, while Laravel uses a traditional synchronous design by default. Neutomic requires third-party libraries for features like ORM and templating, whereas Laravel includes these features built-in. To get started with an example of a Neutomic application, you can check out the skeleton repository at neutomic/skeleton.
PHP Minimum Requirement: 8.3
PROS
Lightweight and minimalistic
High-performance and efficient for handling concurrent tasks
Event-driven architecture based on RevoltPHP and Amp components
CONS
Requires more manual integration to incorporate other features, but it provides a skeleton to help you get started
Less expressive syntax compared to Laravel
Requires some getting used to if you are not familiar with event-driven architecture
Visit Neutomic
The post 10 Alternative Frameworks to Laravel appeared first on Hongkiat.
Original Source: https://www.webdesignerdepot.com/top-7-wordpress-plugins/
WordPress is a hands-down favorite of website designers and developers. Renowned for its flexibility and ease of use, WordPress offers a vast array of tools to select from. Including an ecosystem of plugins designers/developers can put to use to enhance the flexibility of any WordPress website.
Original Source: https://smashingmagazine.com/2024/07/customer-journey-maps-figma-miro-templates/
User journey maps are a remarkably effective way to visualize the user’s experience for the entire team. Instead of pointing to documents scattered across remote fringes of Sharepoint, we bring key insights together — in one single place.
Let’s explore a couple of helpful customer journey templates to get started and how companies use them in practice.
This article is part of our ongoing series on UX. You might want to take a look at Smart Interface Design Patterns 🍣 and the upcoming live UX training as well. Use code BIRDIE to save 15% off.
AirBnB Customer Journey Blueprint
AirBnB Customer Journey Blueprint (also check Google Drive example) is a wonderful practical example of how to visualize the entire customer experience for two personas, across eight touch points, with user policies, UI screens and all interactions with the customer service — all on one single page.

Now, unlike AirBnB, your product might not need a mapping against user policies. However, it might need other lanes that would be more relevant for your team. For example, include relevant findings and recommendations from UX research. List key actions needed for the next stage. Include relevant UX metrics and unsuccessful touchpoints.
Whatever works for you, works for you — just make sure to avoid assumptions and refer to facts and insights from research.
Spotify Customer Journey Map
Spotify Customer Journey Blueprint (high resolution) breaks down customer experiences by distinct user profiles, and for each includes mobile and desktop views, pain points, thoughts, and actions. Also, notice branches for customers who skip authentication or admin tasks.

Getting Started With Journey Maps
To get started with user journey maps, we first choose a lens: Are we reflecting the current state or projecting a future state? Then, we choose a customer who experiences the journey — and we capture the situation/goals that they are focusing on.

Next, we list high-level actions users are going through. We start by defining the first and last stages and fill in between. Don’t get too granular: list key actions needed for the next stage. Add the user’s thoughts, feelings, sentiments, and emotional curves.

Eventually, add user’s key touchpoints with people, services, tools. Map user journey across mobile and desktop screens. Transfer insights from other research (e.g., customer support). Fill in stage after stage until the entire map is complete.
Then, identify pain points and highlight them with red dots. Add relevant jobs-to-be-done, metrics, channels if needed. Attach links to quotes, photos, videos, prototypes, Figma files. Finally, explore ideas and opportunities to address pain points.
Free Customer Journey Maps Templates (Miro, Figma)
You don’t have to reinvent the wheel from scratch. Below, you will find a few useful starter kits to get up and running fast. However, please make sure to customize these templates for your needs, as every product will require its own specific details, dependencies, and decisions.

User Journey Map Template (Figma), by Estefanía Montaña B.
Customer Journey Mapping (PDF), by Taras Bakusevych
End-To-End User Experience Map (Figma), by Justin Tan
Customer Journey Map Template (Figma), by Ed Biden
Customer Journey Map Template (Miro), by Matt Anderson
Customer Journey Map (Miro), by Hustle Badger
Customer Experience Map Template (Miro), by Essense
The Customer Journey Map (Miro), by RSPRINT
Wrapping Up
Keep in mind that customer journeys are often non-linear, with unpredictable entry points and integrations way beyond the final stage of a customer journey map. It’s in those moments when things leave a perfect path that a product’s UX is actually stress-tested.
So consider mapping unsuccessful touchpoints as well — failures, error messages, conflicts, incompatibilities, warnings, connectivity issues, eventual lock-outs and frequent log-outs, authentication issues, outages, and urgent support inquiries.
Also, make sure to question assumptions and biases early. Once they live in your UX map, they grow roots — and it might not take long until they are seen as the foundation of everything, which can be remarkably difficult to challenge or question later. Good luck, everyone!
Meet Smart Interface Design Patterns
If you are interested in UX and design patterns, take a look at Smart Interface Design Patterns, our 10h-video course with 100s of practical examples from real-life projects — with a live UX training later this year. Everything from mega-dropdowns to complex enterprise tables — with 5 new segments added every year. Jump to a free preview. Use code BIRDIE to save 15% off.
 Meet Smart Interface Design Patterns, our video course on interface design & UX.
Meet Smart Interface Design Patterns, our video course on interface design & UX.
Jump to the video course →
100 design patterns & real-life
examples.
10h-video course + live UX training. Free preview.
Original Source: https://abduzeedo.com/revitalizing-freeda-language-schools-branding-and-visual-identity
Revitalizing Freeda Language School’s Branding and Visual Identity

abduzeedo0703—24
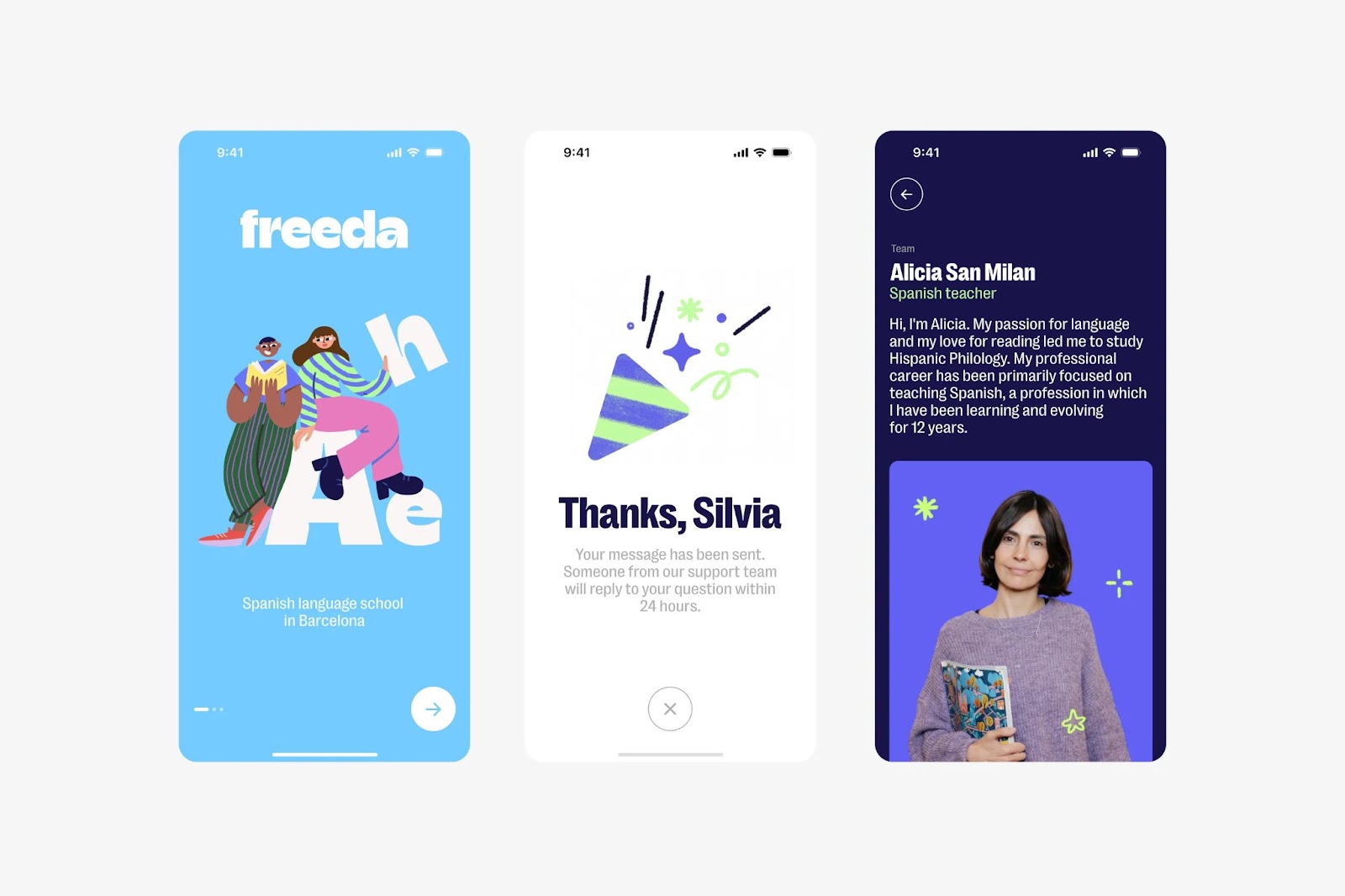
Discover how Freeda Language School’s updated branding and visual identity reflect a vibrant, engaging learning experience.
Freeda Language School, a renowned institution in Barcelona, recognized the need for a refreshed visual identity after a decade. Designer Ilía Tuma took on this challenge, collaborating closely with Freeda’s team to modernize their brand. This article explores the new branding and visual identity that encapsulate Freeda’s dynamic spirit and commitment to engaging education.
Freeda’s original visual identity, crafted ten years ago, no longer reflected the school’s evolving ethos and vibrant student experience. As a former student, Ilía Tuma saw the opportunity to infuse the brand with elements that emphasize humanity, friendliness, and an engaging learning environment. The goal was to create a design that resonates with modern students while preserving the essence of Freeda.
Collaborative Design Process
The redesign process was a collaborative effort between Tuma and the Freeda team. This close cooperation ensured that the new visual identity would authentically reflect the school’s values and vision. The team aimed to create a brand that is not only modern and inviting but also inspiring and effective in conveying Freeda’s educational mission.
Key Elements of the New Visual Identity
1. Friendly Illustrations: The updated identity features illustrations that capture the essence of the student experience at Freeda. These visuals add a personal and welcoming touch, making the brand feel more relatable and engaging.
2. Expressive Colors: A vibrant color palette was chosen to reflect the dynamic and energetic atmosphere of the school. These colors help convey a sense of enthusiasm and joy in learning, aligning with Freeda’s commitment to a positive educational journey.
3. Modern Typography: The typography used in the new branding is both expressive and modern, enhancing the brand’s unique character. It ensures readability and adds a contemporary flair to the overall design.
4. Dynamic Design System: The new design system is versatile and cohesive, allowing for consistent application across various platforms and materials. This ensures that Freeda’s visual identity remains strong and recognizable in all contexts.
The updated visual identity for Freeda Language School not only modernizes the brand but also reinforces its commitment to providing a joyful and effective educational experience. The new design makes learning at Freeda both inviting and inspiring, appealing to students from around the world.
Looking ahead, this revitalized brand identity aligns seamlessly with Freeda’s vision for the future. It positions the school as a leader in language education, ready to continue attracting and inspiring students globally. The collaboration between Ilía Tuma and Freeda exemplifies how thoughtful design can enhance and elevate an educational brand.
Branding and visual identity artfiacts
For more information make sure to check out Ilía Tuma website at tuma.world