Original Source: https://smashingmagazine.com/2024/06/what-are-css-container-style-queries-good-for/
We’ve relied on media queries for a long time in the responsive world of CSS but they have their share of limitations and have shifted focus more towards accessibility than responsiveness alone. This is where CSS Container Queries come in. They completely change how we approach responsiveness, shifting the paradigm away from a viewport-based mentality to one that is more considerate of a component’s context, such as its size or inline-size.
Querying elements by their dimensions is one of the two things that CSS Container Queries can do, and, in fact, we call these container size queries to help distinguish them from their ability to query against a component’s current styles. We call these container style queries.
Existing container query coverage has been largely focused on container size queries, which enjoy 90% global browser support at the time of this writing. Style queries, on the other hand, are only available behind a feature flag in Chrome 111+ and Safari Technology Preview.
The first question that comes to mind is What are these style query things? followed immediately by How do they work?. There are some nice primers on them that others have written, and they are worth checking out.
But the more interesting question about CSS Container Style Queries might actually be Why we should use them? The answer, as always, is nuanced and could simply be it depends. But I want to poke at style queries a little more deeply, not at the syntax level, but what exactly they are solving and what sort of use cases we would find ourselves reaching for them in our work if and when they gain browser support.
Why Container Queries
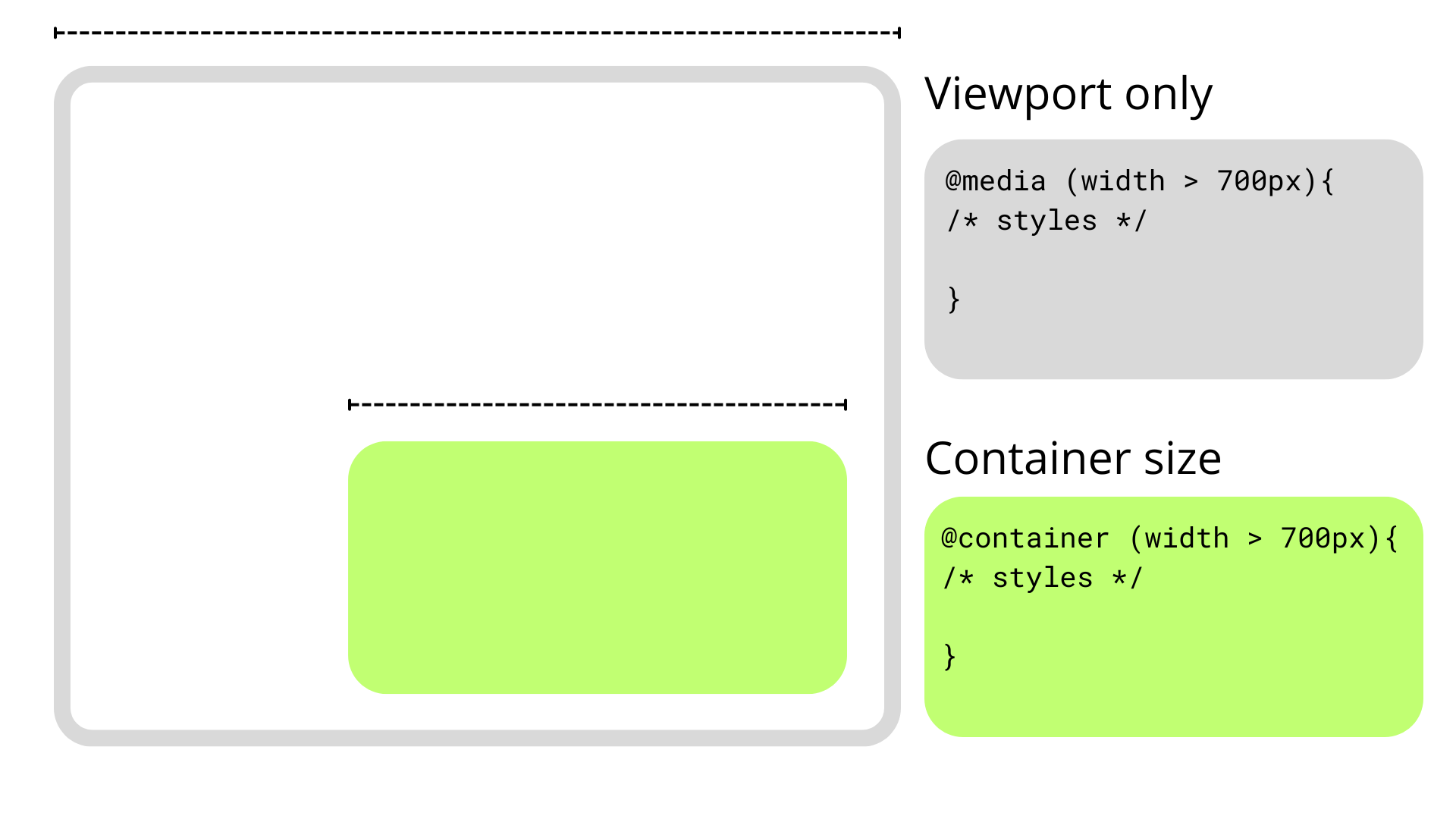
Talking purely about responsive design, media queries have simply fallen short in some aspects, but I think the main one is that they are context-agnostic in the sense that they only consider the viewport size when applying styles without involving the size or dimensions of an element’s parent or the content it contains.
This usually isn’t a problem since we only have a main element that doesn’t share space with others along the x-axis, so we can style our content depending on the viewport’s dimensions. However, if we stuff an element into a smaller parent and maintain the same viewport, the media query doesn’t kick in when the content becomes cramped. This forces us to write and manage an entire set of media queries that target super-specific content breakpoints.
Container queries break this limitation and allow us to query much more than the viewport’s dimensions.
How Container Queries Generally Work
Container size queries work similarly to media queries but allow us to apply styles depending on the container’s properties and computed values. In short, they allow us to make style changes based on an element’s computed width or height regardless of the viewport. This sort of thing was once only possible with JavaScript or the ol’ jQuery, as this example shows.
As noted earlier, though, container queries can query an element’s styles in addition to its dimensions. In other words, container style queries can look at and track an element’s properties and apply styles to other elements when those properties meet certain conditions, such as when the element’s background-color is set to hsl(0 50% 50%).
That’s what we mean when talking about CSS Container Style Queries. It’s a proposed feature defined in the same CSS Containment Module Level 3 specification as CSS Container Size Queries — and one that’s currently unsupported by any major browser — so the difference between style and size queries can get a bit confusing as we’re technically talking about two related features under the same umbrella.
We’d do ourselves a favor to backtrack and first understand what a “container” is in the first place.
Containers
An element’s container is any ancestor with a containment context; it could be the element’s direct parent or perhaps a grandparent or great-grandparent.
A containment context means that a certain element can be used as a container for querying. Unofficially, you can say there are two types of containment context: size containment and style containment.
Size containment means we can query and track an element’s dimensions (i.e., aspect-ratio, block-size, height, inline-size, orientation, and width) with container size queries as long as it’s registered as a container. Tracking an element’s dimensions requires a little processing in the client. One or two elements are a breeze, but if we had to constantly track the dimensions of all elements — including resizing, scrolling, animations, and so on — it would be a huge performance hit. That’s why no element has size containment by default, and we have to manually register a size query with the CSS container-type property when we need it.
On the other hand, style containment lets us query and track the computed values of a container’s specific properties through container style queries. As it currently stands, we can only check for custom properties, e.g. –theme: dark, but soon we could check for an element’s computed background-color and display property values. Unlike size containment, we are checking for raw style properties before they are processed by the browser, alleviating performance and allowing all elements to have style containment by default.
Did you catch that? While size containment is something we manually register on an element, style containment is the default behavior of all elements. There’s no need to register a style container because all elements are style containers by default.
And how do we register a containment context? The easiest way is to use the container-type property. The container-type property will give an element a containment context and its three accepted values — normal, size, and inline-size — define which properties we can query from the container.
/* Size containment in the inline direction */
.parent {
container-type: inline-size;
}
This example formally establishes a size containment. If we had done nothing at all, the .parent element is already a container with a style containment.
Size Containment
That last example illustrates size containment based on the element’s inline-size, which is a fancy way of saying its width. When we talk about normal document flow on the web, we’re talking about elements that flow in an inline direction and a block direction that corresponds to width and height, respectively, in a horizontal writing mode. If we were to rotate the writing mode so that it is vertical, then “inline” would refer to the height instead and “block” to the width.
Consider the following HTML:
<div class=”cards-container”>
<ul class=”cards”>
<li class=”card”></li>
</ul>
</div>
We could give the .cards-container element a containment context in the inline direction, allowing us to make changes to its descendants when its width becomes too small to properly display everything in the current layout. We keep the same syntax as in a normal media query but swap @media for @container
.cards-container {
container-type: inline-size;
}
@container (width < 700px) {
.cards {
background-color: red;
}
}
Container syntax works almost the same as media queries, so we can use the and, or, and not operators to chain different queries together to match multiple conditions.
@container (width < 700px) or (width > 1200px) {
.cards {
background-color: red;
}
}
Elements in a size query look for the closest ancestor with size containment so we can apply changes to elements deeper in the DOM, like the .card element in our earlier example. If there is no size containment context, then the @container at-rule won’t have any effect.
/* 👎
* Apply styles based on the closest container, .cards-container
*/
@container (width < 700px) {
.card {
background-color: black;
}
}
Just looking for the closest container is messy, so it’s good practice to name containers using the container-name property and then specifying which container we’re tracking in the container query just after the @container at-rule.
.cards-container {
container-name: cardsContainer;
container-type: inline-size;
}
@container cardsContainer (width < 700px) {
.card {
background-color: #000;
}
}
We can use the shorthand container property to set the container name and type in a single declaration:
.cards-container {
container: cardsContainer / inline-size;
/* Equivalent to: */
container-name: cardsContainer;
container-type: inline-size;
}
The other container-type we can set is size, which works exactly like inline-size — only the containment context is both the inline and block directions. That means we can also query the container’s height sizing in addition to its width sizing.
/* When container is less than 700px wide */
@container (width < 700px) {
.card {
background-color: black;
}
}
/* When container is less than 900px tall */
@container (height < 900px) {
.card {
background-color: white;
}
}
And it’s worth noting here that if two separate (not chained) container rules match, the most specific selector wins, true to how the CSS Cascade works.
So far, we’ve touched on the concept of CSS Container Queries at its most basic. We define the type of containment we want on an element (we looked specifically at size containment) and then query that container accordingly.
Container Style Queries
The third value that is accepted by the container-type property is normal, and it sets style containment on an element. Both inline-size and size are stable across all major browsers, but normal is newer and only has modest support at the moment.
I consider normal a bit of an oddball because we don’t have to explicitly declare it on an element since all elements are style containers with style containment right out of the box. It’s possible you’ll never write it out yourself or see it in the wild.
.parent {
/* Unnecessary */
container-type: normal;
}
If you do write it or see it, it’s likely to undo size containment declared somewhere else. But even then, it’s possible to reset containment with the global initial or revert keywords.
.parent {
/* All of these (re)set style containment */
container-type: normal;
container-type: initial;
container-type: revert;
}
Let’s look at a simple and somewhat contrived example to get the point across. We can define a custom property in a container, say a –theme.
.cards-container {
–theme: dark;
}
From here, we can check if the container has that desired property and, if it does, apply styles to its descendant elements. We can’t directly style the container since it could unleash an infinite loop of changing the styles and querying the styles.
.cards-container {
–theme: dark;
}
@container style(–theme: dark) {
.cards {
background-color: black;
}
}
See that style() function? In the future, we may want to check if an element has a max-width: 400px through a style query instead of checking if the element’s computed value is bigger than 400px in a size query. That’s why we use the style() wrapper to differentiate style queries from size queries.
/* Size query */
@container (width > 60ch) {
.cards {
flex-direction: column;
}
}
/* Style query */
@container style(–theme: dark) {
.cards {
background-color: black;
}
}
Both types of container queries look for the closest ancestor with a corresponding containment-type. In a style() query, it will always be the parent since all elements have style containment by default. In this case, the direct parent of the .cards element in our ongoing example is the .cards-container element. If we want to query non-direct parents, we will need the container-name property to differentiate between containers when making a query.
.cards-container {
container-name: cardsContainer;
–theme: dark;
}
@container cardsContainer style(–theme: dark) {
.card {
color: white;
}
}
Weird and Confusing Things About Container Style Queries
Style queries are completely new and bring something never seen in CSS, so they are bound to have some confusing qualities as we wrap our heads around them — some that are completely intentional and well thought-out and some that are perhaps unintentional and may be updated in future versions of the specification.
Style and Size Containment Aren’t Mutually Exclusive
One intentional perk, for example, is that a container can have both size and style containment. No one would fault you for expecting that size and style containment are mutually exclusive concerns, so setting an element to something like container-type: inline-size would make all style queries useless.
However, another funny thing about container queries is that elements have style containment by default, and there isn’t really a way to remove it. Check out this next example:
.cards-container {
container-type: inline-size;
–theme: dark;
}
@container style(–theme: dark) {
.card {
background-color: black;
}
}
@container (width < 700px) {
.card {
background-color: red;
}
}
See that? We can still query the elements by style even when we explicitly set the container-type to inline-size. This seems contradictory at first, but it does make sense, considering that style and size queries are computed independently. It’s better this way since both queries don’t necessarily conflict with each other; a style query could change the colors in an element depending on a custom property, while a container query changes an element’s flex-direction when it gets too small for its contents.

But We Can Achieve the Same Thing With CSS Classes and IDs
Most container query guides and tutorials I’ve seen use similar examples to demonstrate the general concept, but I can’t stop thinking no matter how cool style queries are, we can achieve the same result using classes or IDs and with less boilerplate. Instead of passing the state as an inline style, we could simply add it as a class.
<ol>
<li class=”item first”>
<img src=”…” alt=”Roi’s avatar” />
<h2>Roi</h2>
</li>
<li class=”item second”><!– etc. –></li>
<li class=”item third”><!– etc. –></li>
<li class=”item”><!– etc. –></li>
<li class=”item”><!– etc. –></li>
</ol>
Alternatively, we could add the position number directly inside an id so we don’t have to convert the number into a string:
<ol>
<li class=”item” id=”item-1″>
<img src=”…” alt=”Roi’s avatar” />
<h2>Roi</h2>
</li>
<li class=”item” id=”item-2″><!– etc. –></li>
<li class=”item” id=”item-3″><!– etc. –></li>
<li class=”item” id=”item-4″><!– etc. –></li>
<li class=”item” id=”item-5″><!– etc. –></li>
</ol>
Both of these approaches leave us with cleaner HTML than the container queries approach. With style queries, we have to wrap our elements inside a container — even if we don’t semantically need it — because of the fact that containers (rightly) are unable to style themselves.
We also have less boilerplate-y code on the CSS side:
#item-1 {
background: linear-gradient(45deg, yellow, orange);
}
#item-2 {
background: linear-gradient(45deg, grey, white);
}
#item-3 {
background: linear-gradient(45deg, brown, peru);
}
See the Pen Style Queries Use Case Replaced with Classes [forked] by Monknow.
As an aside, I know that using IDs as styling hooks is often viewed as a no-no, but that’s only because IDs must be unique in the sense that no two instances of the same ID are on the page at the same time. In this instance, there will never be more than one first-place, second-place, or third-place player on the page, making IDs a safe and appropriate choice in this situation. But, yes, we could also use some other type of selector, say a data-* attribute.
There is something that could add a lot of value to style queries: a range syntax for querying styles. This is an open feature that Miriam Suzanne proposed in 2023, the idea being that it queries numerical values using range comparisons just like size queries.
Imagine if we wanted to apply a light purple background color to the rest of the top ten players in the leaderboard example. Instead of adding a query for each position from four to ten, we could add a query that checks a range of values. The syntax is obviously not in the spec at this time, but let’s say it looks something like this just to push the point across:
/* Do not try this at home! */
@container leaderboard style(4 >= –position <= 10) {
.item {
background: linear-gradient(45deg, purple, fuchsia);
}
}
In this fictional and hypothetical example, we’re:
Tracking a container called leaderboard,
Making a style() query against the container,
Evaluating the –position custom property,
Looking for a condition where the custom property is set to a value equal to a number that is greater than or equal to 4 and less than or equal to 10.
If the custom property is a value within that range, we set a player’s background color to a linear-gradient() that goes from purple to fuschia.
This is very cool, but if this kind of behavior is likely to be done using components in modern frameworks, like React or Vue, we could also set up a range in JavaScript and toggle on a .top-ten class when the condition is met.
See the Pen Style Ranged Queries Use Case Replaced with Classes [forked] by Monknow.
Sure, it’s great to see that we can do this sort of thing directly in CSS, but it’s also something with an existing well-established solution.
Separating Style Logic From Logic Logic
So far, style queries don’t seem to be the most convenient solution for the leaderboard use case we looked at, but I wouldn’t deem them useless solely because we can achieve the same thing with JavaScript. I am a big advocate of reaching for JavaScript only when necessary and only in sprinkles, but style queries, the ones where we can only check for custom properties, are most likely to be useful when paired with a UI framework where we can easily reach for JavaScript within a component. I have been using Astro an awful lot lately, and in that context, I don’t see why I would choose a style query over programmatically changing a class or ID.
However, a case can be made that implementing style logic inside a component is messy. Maybe we should keep the logic regarding styles in the CSS away from the rest of the logic logic, i.e., the stateful changes inside a component like conditional rendering or functions like useState and useEffect in React. The style logic would be the conditional checks we do to add or remove class names or IDs in order to change styles.
If we backtrack to our leaderboard example, checking a player’s position to apply different styles would be style logic. We could indeed check that a player’s leaderboard position is between four and ten using JavaScript to programmatically add a .top-ten class, but it would mean leaking our style logic into our component. In React (for familiarity, but it would be similar to other frameworks), the component may look like this:
const LeaderboardItem = ({position}) => {
<li className={item ${position >= 4 && position <= 10 ? “top-ten” : “”}} id={item-${position}}>
<img src=”…” alt=”Roi’s avatar” />
<h2>Roi</h2>
</li>;
};
Besides this being ugly-looking code, adding the style logic in JSX can get messy. Meanwhile, style queries can pass the –position value to the styles and handle the logic directly in the CSS where it is being used.
const LeaderboardItem = ({position}) => {
<li className=”item” style={{“–position”: position}}>
<img src=”…” alt=”Roi’s avatar” />
<h2>Roi</h2>
</li>;
};
Much cleaner, and I think this is closer to the value proposition of style queries. But at the same time, this example makes a large leap of assumption that we will get a range syntax for style queries at some point, which is not a done deal.
Conclusion
There are lots of teams working on making modern CSS better, and not all features have to be groundbreaking miraculous additions.
Size queries are definitely an upgrade from media queries for responsive design, but style queries appear to be more of a solution looking for a problem.
It simply doesn’t solve any specific issue or is better enough to replace other approaches, at least as far as I am aware.
Even if, in the future, style queries will be able to check for any property, that introduces a whole new can of worms where styles are capable of reacting to other styles. This seems exciting at first, but I can’t shake the feeling it would be unnecessary and even chaotic: styles reacting to styles, reacting to styles, and so on with an unnecessary side of boilerplate. I’d argue that a more prudent approach is to write all your styles declaratively together in one place.
Maybe it would be useful for web extensions (like Dark Reader) so they can better check styles in third-party websites? I can’t clearly see it. If you have any suggestions on how CSS Container Style Queries can be used to write better CSS that I may have overlooked, please let me know in the comments! I’d love to know how you’re thinking about them and the sorts of ways you imagine yourself using them in your work.






 Meet Smart Interface Design Patterns, our video course on interface design & UX.
Meet Smart Interface Design Patterns, our video course on interface design & UX.