Original Source: https://smashingmagazine.com/2021/10/static-first-madlib-generator-portable-text-netlify-builder-functions/
Creating an interactive experience with fiction can be a chore with traditional content management tools. Writing the prose, creating the forms, combining them in the frontend — these are often the domain of three different people.
Let’s make it the domain of just one content creator in which the user will fill out a form before reading the story — creating odd and often funny stories. This type of experience was popularized as “Madlibs.”
Generate your own madlibs in the demo;
Look through the final code on Github;
Get a fully-built version set up in your accounts.

How The Generator Will Work
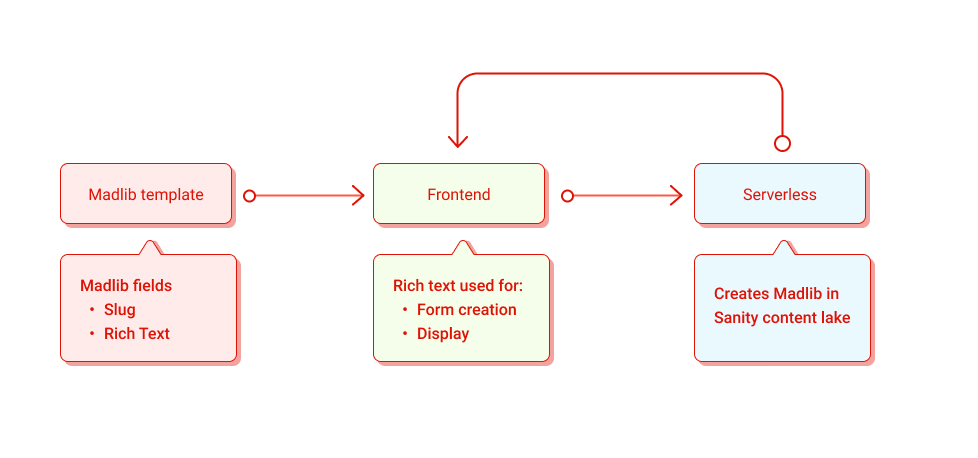
An editor can create a series of madlibs that an end-user can fill out and save a copy with their unique answers. The editor will be working with the Sanity Studio inside a rich-text field that we’ll craft to provide additional information for our front-end to build out forms.
For the editor, it will feel like writing standard paragraph content. They’ll be able to write like they’re used to writing. They can then create specific blocks inside their content that will specify a part of speech and display text.
The front-end of the application can then use that data to both display the text and build a form. We’ll use 11ty to create the frontend with some small templates. The form that is built will display to the user before they see the text. They’ll know what type of speech and general context for the phrases and words they can enter.
After the form is submitted, they’ll be given their fully formed story (with hopefully hilarious results). This creation will only be set within their browser. If they wish to share it, they can then click the “Save” button. This will submit the entire text to a serverless function in Netlify to save it to the Sanity data store. Once that has been created, a link will appear for the user to view the permanent version of their madlib and share it with friends.
Since 11ty is a static site generator, we can’t count on a site rebuild to generate each user’s saved Madlib on the fly. We can use 11ty’s new Serverless mode to build them on request using Netlify’s On-Demand Builders to cache each Madlib.
The Tools
Sanity.io
Sanity.io is a unified content platform that believes that content is data and data can be used as content. Sanity pairs a real-time data store with three open-source tools: a powerful query language (GROQ), a CMS (Sanity Studio), and a rich-text data specification (Portable Text).
Portable Text
Portable Text is an open-source specification designed to treat rich text as data. We’ll be using Portable Text for the rich text that our editors will enter into a Sanity Studio. Data will decorate the rich text in a way that we can create a form on the fly based on the content.
11ty And 11ty Serverless
11ty is a static site generator built in Node. It allows developers to ingest data from multiple sources, write templates in multiple templating engines, and output simple, clean HTML.
In the upcoming 1.0 release, 11ty is introducing the concept of 11ty Serverless. This update allows sites to use the same templates and data to render pages via a serverless function or on-demand builder. 11ty Serverless begins to blur the line between “static site generator” and server-rendered page.
Netlify On-Demand Builders
Netlify has had serverless functions as part of its platform for years. For example, an “On-Demand Builder” is a serverless function dedicated to serving a cached file. Each builder works similarly to a standard serverless function on the first call. Netlify then caches that page on its edge CDN for each additional call.
Building The Editing Interface And Datastore
Before we can dive into serverless functions and the frontend, it would be helpful to have our data set up and ready to query.
To do this, we’ll set up a new project and install Sanity’s Studio (an open-source content platform for managing data in your Sanity Content Lake).
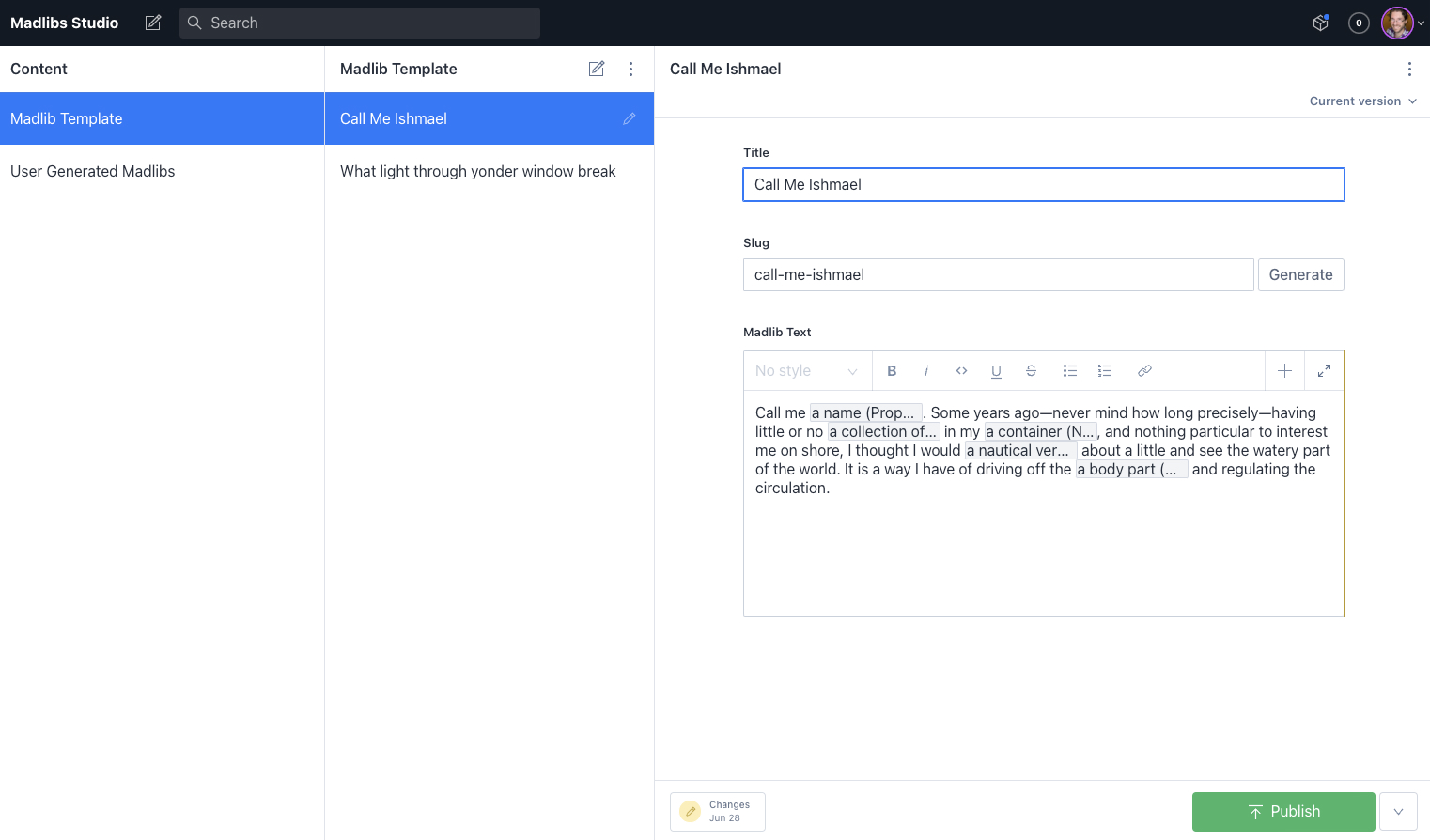
To create a new project, we can use Sanity’s CLI tools.
First, we need to create a new project directory to house both the front-end and the studio. I’ve called mine madlibs.
From inside this directory in the command line, run the following commands:
npm i -g @sanity/cli
sanity init
The sanity init command will run you through a series of questions. Name your project madlibs, create a new dataset called production, set the “output path” to studio, and for “project template,” select “Clean project with no predefined schemas.”
The CLI creates a new Sanity project and installs all the needed dependencies for a new studio. Inside the newly created studio directory, we have everything we need to make our editing experience.
Before we create the first interface, run sanity start in the studio directory to run the studio.
Creating The madlib Schema
A set of schema defines the studio’s editing interface. To create a new interface, we’ll create a new schema in the schema folder.
// madlibs/studio/schemas/madlib.js
export default {
// Name in the data
name: ‘madlib’,
// Title visible to editors
title: ‘Madlib Template’,
// Type of schema (at this stage either document or object)
type: ‘document’,
// An array of fields
fields: [
{
name: ‘title’,
title: ‘Title’,
type: ‘string’
},
{
title: ‘Slug’,
name: ‘slug’,
type: ‘slug’,
options: {
source: ‘title’,
maxLength: 200, // // will be ignored if slugify is set
}
},
]
}
The schema file is a JavaScript file that exports an object. This object defines the data’s name, title, type, and any fields the document will have.
In this case, we’ll start with a title string and a slug that can be generated from the title field. Once the file and initial code are created, we need to add this schema to our schema.js file.
// /madlibs/studio/schema/schema.js
// First, we must import the schema creator
import createSchema from ‘part:@sanity/base/schema-creator’
// Then import schema types from any plugins that might expose them
import schemaTypes from ‘all:part:@sanity/base/schema-type’
// Imports our new schema
import madlib from ‘./madlib’
// Then we give our schema to the builder and provide the result to Sanity
export default createSchema({
// We name our schema
name: ‘default’,
// Then proceed to concatenate our document type
// to the ones provided by any plugins that are installed
types: schemaTypes.concat([
// document
// adds the schema to the list the studio will display
madlib,
])
})
Next, we need to create a rich text editor for our madlib authors to write the templates. Sanity has a built-in way of handling rich text that can convert to the flexible Portable Text data structure.
To create the editor, we use an array field that contains a special schema type: block.
The block type will return all the default options for rich text. We can also extend this type to create specialty blocks for our editors.
export default {
// Name in the data
name: ‘madlib’,
// Title visible to editors
title: ‘Madlib Template’,
// Type of schema (at this stage either document or object)
type: ‘document’,
// An array of fields
fields: [
{
name: ‘title’,
title: ‘Title’,
type: ‘string’
},
{
title: ‘Slug’,
name: ‘slug’,
type: ‘slug’,
options: {
source: ‘title’,
maxLength: 200, // // will be ignored if slugify is set
}
},
{
title: ‘Madlib Text’,
name: ‘text’,
type: ‘array’,
of: [
{
type: ‘block’,
name: ‘block’,
of: [
// A new type of field that we’ll create next
{ type: ‘madlibField’ }
]
},
]
},
]
}
This code will set up the Portable Text editor. It builds various types of “blocks.” Blocks roughly equate to top-level data in the JSON data that Portable Text will return. By default, standard blocks take the shape of things like paragraphs, headers, lists, etc.
Custom blocks can be created for things like images, videos, and other data. For our madlib fields, we want to make “inline” blocks — blocks that flow within one of these larger blocks. To do that, the block type can accept its own of array. These fields can be any type, but we’ll make a custom type and add it to our schema in our case.
Creating A Custom Schema Type For The Madlib Field
To create a new custom type, we need to create a new file and import the schema into schema.js as we did for a new document type.
Instead of creating a schema with a type of document, we need to create one of type: object.
This custom type needs to have two fields: the display text and the grammar type. By structuring the data this way, we open up future possibilities for inspecting our content.
Alongside the data fields for this type, we can also specify a custom preview to show more than one field displayed in the rich text. To make this work, we define a React component that will accept the data from the fields and display the text the way we want it.
// /madlibs/studio/schemas/object/madLibField.js
import React from ‘react’
// A React Component that takes hte value of data
// and returns a simple preview of the data that can be used
// in the rich text editor
function madlibPreview({ value }) {
const { text, grammar } = value
return (
{text} ({grammar})
);
}
export default {
title: ‘Madlib Field Details’,
name: ‘madlibField’,
type: ‘object’,
fields: [
{
name: ‘displayText’,
title: ‘Display Text’,
type: ‘string’
},
{
name: ‘grammar’,
title: ‘Grammar Type’,
type: ‘string’
}
],
// Defines a preview for the data in the Rich Text editor
preview: {
select: {
// Selects data to pass to our component
text: ‘displayText’,
grammar: ‘grammar’
},
// Tells the field which preview to use
component: madlibPreview,
},
}
Once that’s created, we can add it to our schemas array and use it as a type in our Portable Text blocks.
// /madlibs/studio/schemas/schema.js
// First, we must import the schema creator
import createSchema from ‘part:@sanity/base/schema-creator’
// Then import schema types from any plugins that might expose them
import schemaTypes from ‘all:part:@sanity/base/schema-type’
import madlib from ‘./madlib’
// Import the new object
import madlibField from ‘./objects/madlibField’
// Then we give our schema to the builder and provide the result to Sanity
export default createSchema({
// We name our schema
name: ‘default’,
// Then proceed to concatenate our document type
// to the ones provided by any plugins that are installed
types: schemaTypes.concat([
// documents
madlib,
//objects
madlibField
])
})
Creating The Schema For User-generated Madlibs
Since the user-generated madlibs will be submitted from our frontend, we don’t technically need a schema for them. However, if we create a schema, we get an easy way to see all the entries (and delete them if necessary).
We want the structure for these documents to be the same as our madlib templates. The main differences in this schema from our madlib schema are the name, title, and, optionally, making the fields read-only.
// /madlibs/studio/schema/userLib.js
export default {
name: ‘userLib’,
title: ‘User Generated Madlibs’,
type: ‘document’,
fields: [
{
name: ‘title’,
title: ‘Title’,
type: ‘string’,
readOnly: true
},
{
title: ‘Slug’,
name: ‘slug’,
type: ‘slug’,
readOnly: true,
options: {
source: ‘title’,
maxLength: 200, // // will be ignored if slugify is set
},
},
{
title: ‘Madlib Text’,
name: ‘text’,
type: ‘array’,
readOnly: true,
of: [
{
type: ‘block’,
name: ‘block’,
of: [
{ type: ‘madlibField’ }
]
},
]
},
]
}
With that, we can add it to our schema.js file, and our admin is complete. Before we move on, be sure to add at least one madlib template. I found the first paragraph of Moby Dick worked surprisingly well for some humorous results.
Building The Frontend With 11ty
To create the frontend, we’ll use 11ty. 11ty is a static site generator written in and extended by Node. It does the job of creating HTML from multiple sources of data well, and with some new features, we can extend that to server-rendered pages and build-rendered pages.
Setting Up 11ty
First, we’ll need to get things set up.
Inside the main madlibs directory, let’s create a new site directory. This directory will house our 11ty site.
Open a new terminal and change the directory into the site directory. From there, we need to install a few dependencies.
// Create a new package.json
npm init -y
// Install 11ty and Sanity utilities
npm install @11ty/eleventy@beta @sanity/block-content-to-html @sanity/client
Once these have been installed, we’ll add a couple of scripts to our package.json
// /madlibs/site/package.json
“scripts”: {
“start”: “eleventy –serve”,
“build”: “eleventy”
},
Now that we have a build and start script, let’s add a base template for our pages to use and an index page.
By default, 11ty will look in an _includes directory for our templates, so create that directory and add a base.njk file to it.
<!DOCTYPE html>
<html lang=”en”>
<head>
<meta charset=”UTF-8″>
<meta name=”viewport” content=”width=device-width, initial-scale=1.0″>
<title>Madlibs</title>
{# Basic reset #}
<link rel=”stylesheet” href=”https://unpkg.com/some-nice-basic-css/global.css” />
</head>
<body>
<nav class=”container navigation”>
<a class=”logo” href=”/”>Madlibs</a>
</nav>
<div class=”stack container bordered”>
{# Inserts content from a page file and renders it as html #}
{{ content | safe }}
</div>
{% block scripts %}
{# Block to insert scripts from child templates #}
{% endblock %}
</body>
</html>
Once we have a template, we can create a page. First, in the root of the site directory, add an index.html file. Next, we’ll use frontmatter to add a little data — a title and the layout file to use.
—
title: Madlibs
layout: ‘base.njk’
—
<p>Some madlibs to take your mind off things. They’re stored in <a href=”https://sanity.io”>Sanity.io</a>, built with <a href=”https://11ty.dev”>11ty</a>, and do interesting things with Netlify serverless functions.</p>
Now you can start 11ty by running npm start in the site directory.
Creating Pages From Sanity Data Using 11ty Pagination
Now, we want to create pages dynamically from data from Sanity. To do this, we’ll create a JavaScript Data file and a Pagination template.
Before we dive into those files, we need to create a couple of utilities for working with the Sanity data.
Inside the site directory, let’s create a utils directory.
The first utility we need is an initialized Sanity JS client. First, create a file named sanityClient.js in the new utils directory.
// /madlibs/site/utils/sanityClient.js’
const sanityClient = require(‘@sanity/client’)
module.exports = sanityClient({
// The project ID
projectId: ‘<YOUR-ID>’,
// The dataset we created
dataset: ‘production’,
// The API version we want to use
// Best practice is to set this to today’s date
apiVersion: ‘2021-06-07’,
// Use the CDN instead of fetching directly from the data store
useCdn: true
})
Since our rich text is stored as Portable Text JSON, we need a way to convert the data to HTML. We’ll create a utility to do this for us. First, create a file named portableTextUtils.js in the utils directory.
For Sanity and 11ty sites, we typically will want to convert the JSON to either Markdown or HTML. For this site, we’ll use HTML to have granular control over the output.
Earlier, we installed @sanity/block-content-to-html, which will help us serialize the data to HTML. The package will work on all basic types of Portable Text blocks and styles. However, we have a custom block type that needs a custom serializer.
// Initializes the package
const toHtml = require(‘@sanity/block-content-to-html’)
const h = toHtml.h;
const serializers = {
types: {
madlibField: ({ node }) => {
// Takes each node of type madlibField
// and returns an HTML span with an id, class, and text
return h(‘span’, node.displayText, { id: node._key, className: ’empty’ })
}
}
}
const prepText = (data) => {
// Takes the data from a specific Sanity document
// and creates a new htmlText property to contain the HTML
// This lets us keep the Portable Text data intact and still display HTML
return {
…data,
htmlText: toHtml({
blocks: data.text, // Portable Text data
serializers: serializers // The serializer to use
})
}
}
// We only need to export prepText for our functions
module.exports = { prepText }
The serializers object in this code has a types object. In this object, we create a specialized serializer for any type. The key in the object should match the type given in our data. In our case, this is madlibField. Each type will have a function that returns an element written using hyperscript functions.
In this case, we create a span with children of the displayText from the current data. Later we’ll need unique IDs based on the data’s _key, and we’ll need a class to style these. We provide those in an object as the third argument for the h() function. We’ll use this same serializer setup for both our madlib templates and the user-generated madlibs.
Now that we have our utilities, it’s time to create a JavaScript data file. First, create a _data in the site directory. In this file, we can add global data to our 11ty site. Next, create a madlibs.js file. This file is where our JavaScript will run to pull each madlib template. The data will be available to any of our templates and pages under the madlibs key.
// Get our utilities
const client = require(‘../utils/sanityClient’)
const {prepText} = require(‘../utils/portableTextUtils’)
// The GROQ query used to find specific documents and
// shape the output
const query = *[_type == “madlib”]{
title,
“slug”: slug.current,
text,
_id,
“formFields”: text[]{
children[_type == “madlibField”]{
displayText,
grammar,
_key
}
}.children[]
}
module.exports = async function() {
// Fetch data based on the query
const madlibs = await client.fetch(query);
// Prepare the Portable Text data
const preppedMadlib = madlibs.map(prepText)
// Return the full array
return preppedMadlib
}
To fetch the data, we need to get the utilities we just created. The Sanity client has a fetch() method to pass a GROQ query. We’ll map over the array of documents the query returns to prepare their Portable Text and then return that to 11ty’s data cascade.
The GROQ query in this code example is doing most of the work for us. We start by requesting all documents with a _type of madlib from our Sanity content lake. Then we specify which data we want to return. The data starts simply: we need the title, slug, rich text, and id from the document, but we also want to reformat the data into a set of form fields, as well.
To do that, we create a new property on the data being returned: formFields. This looks at the text data (a Portable Text array) and loops over it with the [] operator. We can then build a new project on this data like we’re doing with the entire document with the {} operator.
Each text object has a children array. We can loop through that, and if the item matches the filter inside the [], we can run another projection on that. In this case, we’re filtering all children that have a _type == “madlibField”. In other words, any inline block that has an item with the type we created. We need the displayText, grammar, and _key for each of these. This will return an array of text objects with the children matching our filter. We need to flatten this to be an array of children. To do this, we can add the .children[] after the projects. This will return a flat array with just the children elements we need.
This gives us all the documents in an array with just the data we need (including newly reformatted items).
To use them in our 11ty build, we need a template that will use Pagination.
In the root of the site, create a madlib.njk file. This file will generate each madlib page from the data.
—
layout: ‘base.njk’
pagination:
data: madlibs
alias: madlib
size: 1
permalink: “madlibs/{{ madlib.slug | slug }}/index.html”
—
In the front matter of this file, we specify some data 11ty can use to generate our pages:
layout
The template to use to render the page.
pagination
An object with pagination information.
pagination.data
The data key for pagination to read.
pagination.alias
A key to use in this file for ease.
pagination.size
The number of madlibs per page (in this case, 1 per page to create individual pages).
permalink
The URLs at which each of these should live (can be partially generated from data).
With that data in place, we can specify how to display each piece of data for an item in the array.
—
layout: ‘base.njk’
pagination:
data: madlibs
alias: madlib
size: 1
permalink: “madlibs/{{ madlib.slug | slug }}/index.html”
—
<h2>{{ madlib.title }}</h2>
<p><em>Instructions:</em> Fill out this form, submit it and get your story. It will hopfully make little-to-no sense. Afterward, you can save the madlib and send it to your friends.</p>
<div class=”madlibtext”>
<a href=”#” class=”saver”>Save it</a>
{{ madlib.htmlText | safe }}
</div>
<h2>Form</h2>
<form class=”madlibForm stack”>
{% for input in madlib.formFields %}
<label>
{{ input.displayText }} ({{ input.grammar }})
<input type=”text” class=”libInput” name={{input._key}}>
</label>
{% endfor %}
<button>Done</button>
</form>
We can properly format the title and HTML text. We can then use the formFields array to create a form that users can enter their unique answers.
There’s some additional markup for use in our JavaScript — a form button and a link to save the finalized madlib. The link and madlib text will be hidden (no peeking for our users!).
For every madlib template, you created in your studio, 11ty will build a unique page. The final URLs should look like this
http://localhost:8080/madlibs/the-slug-in-the-studio/
Making The Madlibs Interactive
With our madlibs generated, we need to make them interactive. We’ll sprinkle a little JavaScript and CSS to make them interactive. Before we can use CSS and JS, we need to tell 11ty to copy the static files to our built site.
Copying Static Assets To The Final Build
In the root of the site directory, create the following files and directories:
assets/css/style.css — for any additional styling,
assets/js/madlib.js — for the interactions,
.eleventy.js — the 11ty configuration file.
When these files are created, we need to tell 11ty to copy the assets to the final build. Those instructions live in the .eleventy.js configuration file.
module.exports = function(eleventyConfig) {
eleventyConfig.addPassthroughCopy(“assets/”);
}
This instructs 11ty to copy the entire assets directory to the final build.
The only necessary CSS to make the site work is a snippet to hide and show the madlib text. However, if you want the whole look and feel, you can find all the styles in this file.
.madlibtext {
display: none
}
.madlibtext.show {
display: block;
}
Filling In The Madlib With User Input And JavaScript
Any frontend framework will work with 11ty if you set up a build process. For this example, we’ll use plain JavaScript to keep things simple. The first task is to take the user data in the form and populate the generic madlib template that 11ty generated from our Sanity data.
// Attach the form handler
const form = document.querySelector(‘.madlibForm’)
form.addEventListener(‘submit’, completeLib);
function showText() {
// Find the madlib text in the document
const textDiv = document.querySelector(‘.madlibtext’)
// Toggle the class “show” to be present
textDiv.classList.toggle(‘show’)
}
// A function that takes the submit event
// From the event, it will get the contents of the inputs
// and write them to page and show the full text
function completeLib(event) {
// Don’t submit the form
event.preventDefault();
const { target } = event // The target is the form element
// Get all inputs from the form in array format
const inputs = Array.from(target.elements)
inputs.forEach(input => {
// The button is an input and we don’t want that in the final data
if (input.type != ‘text’) return
// Find a span by the input’s name
// These will both be the _key value
const replacedContent = document.getElementById(input.name)
// Replace the content of the span with the input’s value
replacedContent.innerHTML = input.value
})
// Show the completed madlib
showText();
}
This functionality comes in three parts: attaching an event listener, taking the form input, inserting it into the HTML, and then showing the text.
When the form is submitted, the code creates an array from the form’s inputs. Next, it finds elements on the page with ids that match the input’s name — both created from the _key values of each block. It then replaces the content of that element with the value from the data.
Once that’s done, we toggle the full madlib text to show on the page.
We need to add this script to the page. To do this, we create a new template for the madlibs to use. In the _includes directory, create a file named lib.njk. This template will extend the base template we created and insert the script at the bottom of the page’s body.
{% extends ‘base.njk’ %}
{% block scripts %}
<script>
var pt = {{ madlib.text | dump | safe }}
var data = {
libId: {{ madlib._id }},
libTitle: {{ madlib.title }}
}
</script>
<script src=”/assets/js/madlib.js”></script>
{% endblock %}
Then, our madlib.njk pagination template needs to use this new template for its layout.
—
layout: ‘lib.njk’
pagination:
data: madlibs
alias: madlib
size: 1
permalink: “madlibs/{{ madlib.slug | slug }}/index.html”
—
// page content
We now have a functioning madlib generator. To make this more robust, let’s allow users to save and share their completed madlibs.
Saving A User Madlib To Sanity With A Netlify Function
Now that we have a madlib displayed to the user, we need to create the link for saving send the information to Sanity.
To do that, we’ll add some more functionality to our front-end JavaScript. But, first, we need to add some more data pulled from Sanity into our JavaScript, so we’ll add a couple of new variables in the scripts block on the lib.njk template.
{% extends ‘base.njk’ %}
{% block scripts %}
<script>
// Portable Text data
var pt = {{ madlib.text | dump | safe }}
var data = {
libId: {{ madlib._id }},
libTitle: {{ madlib.title }}
}
</script>
<script src=”/assets/js/madlib.js”></script>
{% endblock %}
We can write a script to send it and the user-generated answers to a serverless function to send to Sanity with that additional data.
// /madlibs/site/assets/js/madlib.js
// … completeLib()
async function saveLib(event) {
event.preventDefault();
// Return an Map of ids and content to turn into an object
const blocks = Array.from(document.querySelectorAll(‘.empty’)).map(item => {
return [item.id, { content: item.outerText }]
})
// Creates Object ready for storage from blocks map
const userContentBlocks = Object.fromEntries(blocks);
// Formats the data for posting
const finalData = {
userContentBlocks,
pt, // From nunjucks on page
…data // From nunjucks on page
}
// Runs the post data function for createLib
postData(‘/.netlify/functions/createLib’, finalData)
.then(data => {
// When post is successful
// Create a div for the final link
const landingZone = document.createElement(‘div’)
// Give the link a class
landingZone.className = “libUrl”
// Add the div after the saving link
saver.after(landingZone)
// Add the new link inside the landing zone
landingZone.innerHTML = <a href=”/userlibs/${data._id}/” class=”savedUrl”>Your url is /userlibs/${data._id}/</a>
}).catch(error => {
// When errors happen, do something with them
console.log(error)
});
}
async function postData(url = ”, data = {}) {
// A wrapper function for standard JS fetch
const response = await fetch(url, {
method: ‘POST’,
mode: ‘cors’,
cache: ‘no-cache’,
credentials: ‘same-origin’,
headers: {
‘Content-Type’: ‘application/json’
},
body: JSON.stringify(data)
});
return response.json(); // parses JSON response into native JavaScript objects
}
We add a new event listener to the “Save” link in our HTML.
The saveLib function will take the data from the page and the user-generated data and combine them in an object to be handled by a new serverless function. The serverless function needs to take that data and create a new Sanity document. When creating the function, we want it to return the _id for the new document. We use that to create a unique link that we add to the page. This link will be where the newly generated page will be.
Setting Up Netlify Dev
To use Netlify Functions, we’ll need to get our project set up on Netlify. We want Netlify to build and serve from the site directory. To give Netlify this information, we need to create a netlify.toml file at the root of the entire project.
[build]
command = “npm run build” # Command to run
functions = “functions” # Directory we store the functions
publish = “_site” # Folder to publish (11ty automatically makes the _site folder
base = “site” # Folder that is the root of the build
To develop these locally, it’s helpful to install Netlify’s CLI globally.
npm install -g netlify-cli
Once that’s installed, you can run netlify dev in your project. This will take the place of running your start NPM script.
The CLI will run you through connecting your repository to Netlify. Once it’s done, we’re ready to develop our first function.
Creating A Function To Save Madlibs To Sanity
Since our TOML file sets the functions directory to functions, we need to create the directory. Inside the directory, make a createLib.js file. This will be the serverless function for creating a madlib in the Sanity data store.
The standard Sanity client we’ve been using is read-only. To give it write permissions, we need to reconfigure it to use an API read+write token. To generate a token, log into the project dashboard and go to the project settings for your madlibs project. In the settings, find the Tokens area and generate a new token with “Editor” permissions. When the token is generated, save the string to Netlify’s environment variables dashboard with the name SANITY_TOKEN. Netlify Dev will automatically pull these environment variables into the project while running.
To reconfigure the client, we’ll require the file from our utilities, and then run the .config() method. This will let us set any configuration value for this specific use. We’ll set the token to the new environment variable and set useCdn to false.
// Sanity JS Client
// The build client is read-only
// To use to write, we need to add an API token with proper permissions
const client = require(‘../utils/sanityClient’)
client.config({
token: process.env.SANITY_TOKEN,
useCdn: false
})
The basic structure for a Netlify function is to export a handler function that is passed an event and returns an object with a status code and string body.
// Grabs local env variables from .env file
// Not necessary if using Netlify Dev CLI
require(‘dotenv’).config()
// Sanity JS Client
// The build client is read-only
// To use to write, we need to add an API token with proper permissions
const client = require(‘../utils/sanityClient’)
client.config({
token: process.env.SANITY_TOKEN,
useCdn: false
})
// Small ID creation package
const { nanoid } = require(‘nanoid’)
exports.handler = async (event) => {
// Get data off the event body
const {
pt,
userContentBlocks,
id,
libTitle
} = JSON.parse(event.body)
// Create new Portable Text JSON
// from the old PT and the user submissions
const newBlocks = findAndReplace(pt, userContentBlocks)
// Create new Sanity document object
// The doc’s _id and slug are based on a unique ID from nanoid
const docId = nanoid()
const doc = {
_type: “userLib”,
_id: docId,
slug: { current: docId },
madlib: id,
title: ${libTitle} creation,
text: newBlocks,
}
// Submit the new document object to Sanity
// Return the response back to the browser
return client.create(doc).then((res) => {
// Log the success into our function log
console.log(Userlib was created, document ID is ${res._id})
// return with a 200 status and a stringified JSON object we get from the Sanity API
return { statusCode: 200, body: JSON.stringify(doc) };
}).catch(err => {
// If there’s an error, log it
// and return a 500 error and a JSON string of the error
console.log(err)
return {
statusCode: 500, body: JSON.stringify(err)
}
})
}
// Function for modifying the Portable Text JSON
// pt is the original portable Text
// mods is an object of modifications to make
function findAndReplace(pt, mods) {
// For each block object, check to see if a mod is needed and return an object
const newPT = pt.map((block) => ({
…block, // Insert all current data
children: block.children.map(span => {
// For every item in children, see if there’s a modification on the mods object
// If there is, set modContent to the new content, if not, set it to the original text
const modContent = mods[span._key] ? mods[span._key].content : span.text
// Return an object with all the original data, and a new property
// displayText for use in the frontends
return {
…span,
displayText: modContent
}
})
}))
// Return the new Portable Text JSON
return newPT
}
The body is the data we just submitted. For ease, we’ll destructure the data off the event.body object. Then, we need to compare the original Portable Text and the user content we submitted and create the new Portable Text JSON that we can submit to Sanity.
To do that, we run a find and replace function. This function maps over the original Portable Text and for every child in the blocks, replace its content with the corresponding data from the modfications object. If there isn’t a modification, it will store the original text.
With modified Portable Text in hand, we can create a new object to store as a document in the Sanity content lake. Each document needs a unique identifier (which we can use the nanoid NPM package to create. We’ll also let this newly created ID be the slug for consistency.
The rest of the data is mapped to the proper key in our userLib schema we created in the studio and submitted with the authenticated client’s .create() method. When success or failure returns from Sanity, we pass that along to the frontend for handling.
Now, we have data being saved to our Sanity project. Go ahead and fill out a madlib and submit. You can view the creation in the studio. Those links that we’re generating don’t work yet, though. This is where 11ty Serverless comes in.
Setting Up 11ty Serverless
You may have noticed when we installed 11ty that we used a specific version. This is the beta of the upcoming 1.0 release. 11ty Serverless is one of the big new features in that release.
Installing The Serverless Plugin
11ty Serverless is an included plugin that can be initialized to create all the boilerplate for running 11ty in a serverless function. To get up and running, we need to add the plugin to our .eleventy.js configuration file.
const { EleventyServerlessBundlerPlugin } = require(“@11ty/eleventy”);
module.exports = function (eleventyConfig) {
eleventyConfig.addPassthroughCopy(“assets/”);
eleventyConfig.addPlugin(EleventyServerlessBundlerPlugin, {
name: “userlibs”, // the name to use for the functions
functionsDir: “./functions/”, // The functions directory
copy: [“utils/”], // Any files that need to be copied to make our scripts work
excludeDependencies: [“./_data/madlibs.js”] // Exclude any files you don’t want to run
});
};
After creating this file, restart 11ty by rerunning netlify dev. On the next run, 11ty will create a new directory in our functions directory named userlibs (matching the name in the serverless configuration) to house everything it needs to have to run in a serverless function. The index.js file in this directory is created if it doesn’t exist, but any changes you make will persist.
We need to make one small change to the end of this file. By default, 11ty Serverless will initialize using standard serverless functions. This will run the function on every load of the route. That’s an expensive load for content that can’t be changed after it’s been generated. Instead, we can change it to use Netlify’s On-Demand Builders. This will build the page on the first request and cache the result for any later requests. This cache will persist until the next build of the site.
To update the function, open the index.js file and change the ending of the file.
// Comment this line out
exports.handler = handler
// Uncomment these lines
const { builder } = require(“@netlify/functions”);
exports.handler = builder(handler);
Since this file is using Netlify’s functions package, we also need to install that package.
npm install @netlify/functions
Creating A Data File For User-generated Madlibs
Now that we have an On-Demand Builder, we need to pull the data for user-generated madlibs. We can create a new JavaScript data file in the _data file named userlibs.js. Like our madlibs data file, the file name will be the key to get this data in our templates.
// /madlibs/site/_data/userlibs.js
const client = require(‘../utils/sanityClient’)
const {prepText} = require(‘../utils/portableTextUtils’)
const query = *[_type == “userLib”]{
title,
“slug”: slug.current,
text,
_id
}
module.exports = async function() {
const madlibs = await client.fetch(query);
// Protect against no madlibs returning
if (madlibs.length == 0) return {“404”: {}}
// Run through our portable text serializer
const preppedMadlib = madlibs.map(prepText)
// Convert the array of documents into an object
// Each item in the Object will have a key of the item slug
// 11ty’s Pagination will create pages for each one
const mapLibs = preppedMadlib.map(item => ([item.slug, item]))
const objLibs = Object.fromEntries(mapLibs)
return objLibs
}
This data file is similar to what we wrote earlier, but instead of returning the array, we need to return an object. The object’s keys are what the serverless bundle will use to pull the correct madlib on request. In our case, we’ll make the item’s slug the key since the serverless route will be looking for a slug.
Creating A Pagination Template That Uses Serverless Routes
Now that the plugin is ready, we can create a new pagination template to use the generated function.
In the root of our site, add a userlibs.njk template. This template will be like the madlibs.njk template, but it will use different data without any interactivity.
—
layout: ‘base.njk’
pagination:
data: userLibs
alias: userlib
size: 1
serverless: eleventy.serverless.path.slug
permalink:
userlibs: “/userlibs/:slug/”
—
<h2>{{ userlib.title }}</h2>
<div>
{{ userlib.htmlText | safe }}
</div>
In this template, we use base.njk to avoid including the JavaScript. We specify the new userlibs data for pagination.
To pull the correct data, we need to specify what the lookup key will be. On the pagination object, we do this with the serverless property. When using serverless routes, we get access to a new object: eleventy.serverless. On this object, there’s a path object that contains information on what URL the user requested. In this case, we’ll have a slug property on that object. That needs to correspond to a key on our pagination data.
To get the slug on our path, we need to add it to the permalink object. 11ty Serverless allows for more than one route for a template. The route’s key needs to match the name provided in the .eleventy.js configuration. In this case, it should be userlibs. We specify the static /userlibs/ start to the path and then add a dynamic element: :slug/. This slug will be what gets passed to eleventy.serverless.path.slug.
Now, the link that we created earlier by submitting a madlib to Sanity will work.
Next Steps
Now we have a madlib generator that saves to a data store. We build only the necessary pages to allow a user to create a new madlib. When they create one, we make those pages on-demand with 11ty and Netlify Functions. From here, we can extend this further.
Statically build the user-generated content as well as render them on request.
Create a counter for the total number of madlibs saved by each madlib template.
Create a list of words users use by parts of speech.
When you can statically build AND dynamically render, what sorts of applications does this open up?
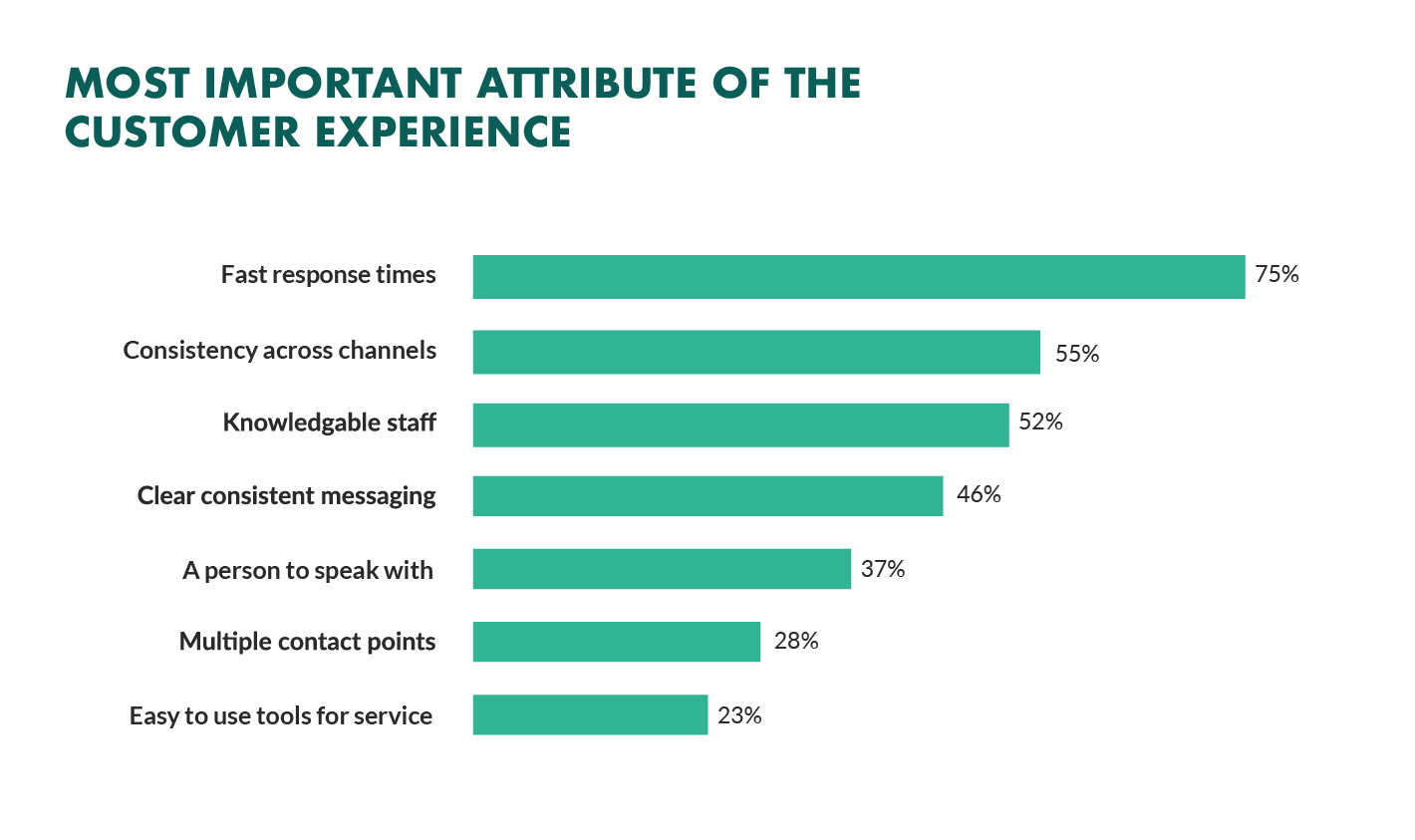
 Not so long ago, customers only had a couple of ways to interact with brands.
Not so long ago, customers only had a couple of ways to interact with brands.