Original Source: https://smashingmagazine.com/2023/10/passkeys-explainer-future-password-less-authentication/
Passkeys are a new way of authenticating applications and websites. Instead of having to remember a password, a third-party service provider (e.g., Google or Apple) generates and stores a cryptographic key pair that is bound to a website domain. Since you have access to the service provider, you have access to the keys, which you can then use to log in.
This cryptographic key pair contains both private and public keys that are used for authenticating messages. These key pairs are often known as asymmetric or public key cryptography.
Public and private key pair? Asymmetric cryptography? Like most modern technology, passkeys are described by esoteric verbiage and acronyms that make them difficult to discuss. That’s the point of this article. I want to put the complex terms aside and help illustrate how passkeys work, explain what they are effective at, and demonstrate what it looks like to work with them.
How Passkeys Work
Passkeys are cryptographic keys that rely on generating signatures. A signature is proof that a message is authentic. How so? It happens first by hashing (a fancy term for “obscuring”) the message and then creating a signature from that hash with your private key. The private key in the cryptographic key pair allows the signature to be generated, and the public key, which is shared with others, allows the service to verify that the message did, in fact, come from you.
In short, passkeys consist of two keys: a public and private. One verifies a signature while the other verifies you, and the communication between them is what grants you access to an account.
Here’s a quick way of generating a signing and verification key pair to authenticate a message using the SubtleCrypto API. While this is only part of how passkeys work, it does illustrate how the concept works cryptographically underneath the specification.
const message = new TextEncoder().encode(“My message”);
const keypair = await crypto.subtle.generateKey(
{ name: “ECDSA”, namedCurve: “P-256” },
true,
[ ‘sign’, ‘verify’ ]
);
const signature = await crypto.subtle.sign(
{ name: “ECDSA”, hash: “SHA-256” },
keypair.privateKey,
message
);
// Normally, someone else would be doing the verification using your public key
// but it’s a bit easier to see it yourself this way
console.log(
“Did my private key sign this message?”,
await crypto.subtle.verify(
{ name: “ECDSA”, hash: “SHA-256” },
keypair.publicKey,
signature,
message
)
);
Notice the three parts pulling all of this together:
Message: A message is constructed.
Key pair: The public and private keys are generated. One key is used for the signature, and the other is set to do the verification.
Signature: A signature is signed by the private key, verifying the message’s authenticity.
From there, a third party would authenticate the private key with the public key, verifying the correct pair of keys or key pair. We’ll get into the weeds of how the keys are generated and used in just a bit, but for now, this is some context as we continue to understand why passkeys can potentially erase the need for passwords.
Why Passkeys Can Replace Passwords
Since the responsibility of storing passkeys is removed and transferred to a third-party service provider, you only have to control the “parent” account in order to authenticate and gain access. This is a lot like requiring single sign-on (SSO) for an account via Google, Facebook, or LinkedIn, but instead, we use an account that has control of the passkey stored for each individual website.
For example, I can use my Google account to store passkeys for somerandomwebsite.com. That allows me to prove a challenge by using that passkey’s private key and thus authenticate and log into somerandomwebsite.com.
For the non-tech savvy, this typically looks like a prompt that the user can click to log in. Since the credentials (i.e., username and password) are tied to the domain name (somerandomwebsite.com), and passkeys created for a domain name are only accessible to the user at login, the user can select which passkey they wish to use for access. This is usually only one login, but in some cases, you can create multiple logins for a single domain and then select which one you wish to use from there.
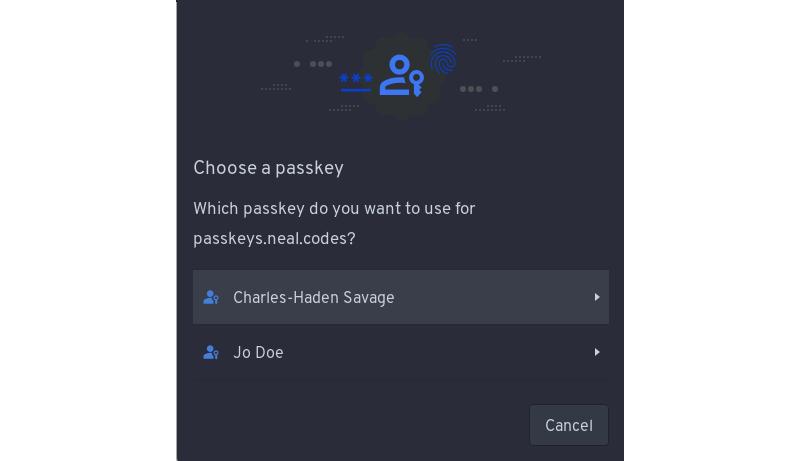
So, what’s the downside? Having to store additional cryptographic keys for each login and every site for which you have a passkey often requires more space than storing a password. However, I would argue that the security gains, the user experience from not having to remember a password, and the prevention of common phishing techniques more than offset the increased storage space.
How Passkeys Protect Us
Passkeys prevent a couple of security issues that are quite common, specifically leaked database credentials and phishing attacks.
Database Leaks
Have you ever shared a password with a friend or colleague by copying and pasting it for them in an email or text? That could lead to a security leak. So would a hack on a system that stores customer information, like passwords, which is then sold on dark marketplaces or made public. In many cases, it’s a weak set of credentials — like an email and password combination — that can be stolen with a fair amount of ease.
Passkeys technology circumvents this because passkeys only store a public key to an account, and as you may have guessed by the name, this key is expected to be made accessible to anyone who wants to use it. The public key is only used for verification purposes and, for the intended use case of passkeys, is effectively useless without the private key to go with it, as the two are generated as a pair. Therefore, those previous juicy database leaks are no longer useful, as they can no longer be used for cracking the password for your account. Cracking a similar private key would take millions of years at this point in time.
Phishing
Passwords rely on knowing what the password is for a given login: anyone with that same information has the same level of access to the same account as you do. There are sophisticated phishing sites that look like they’re by Microsoft or Google and will redirect you to the real provider after you attempt to log into their fake site. The damage is already done at that point; your credentials are captured, and hopefully, the same credentials weren’t being used on other sites, as now you’re compromised there as well.
A passkey, by contrast, is tied to a domain. You gain a new element of security: the fact that only you have the private key. Since the private key is not feasible to remember nor computationally easy to guess, we can guarantee that you are who you say we are (at least as long as your passkey provider is not compromised). So, that fake phishing site? It will not even show the passkey prompt because the domain is different, and thus completely mitigates phishing attempts.
There are, of course, theoretical attacks that can make passkeys vulnerable, like someone compromising your DNS server to send you to a domain that now points to their fake site. That said, you probably have deeper issues to concern yourself with if it gets to that point.
Implementing Passkeys
At a high level, a few items are needed to start using passkeys, at least for the common sign-up and log-in process. You’ll need a temporary cache of some sort, such as redis or memcache, for storing temporary challenges that users can authenticate against, as well as a more permanent data store for storing user accounts and their public key information, which can be used to authenticate the user over the course of their account lifetime. These aren’t hard requirements but rather what’s typical of what would be developed for this kind of authentication process.
To understand passkeys properly, though, we want to work through a couple of concepts. The first concept is what is actually taking place when we generate a passkey. How are passkeys generated, and what are the underlying cryptographic primitives that are being used? The second concept is how passkeys are used to verify information and why that information can be trusted.
Generating Passkeys
A passkey involves an authenticator to generate the key pair. The authenticator can either be hardware or software. For example, it can be a hardware security key, the operating system’s Trusted Platform Module (TPM), or some other application. In the cases of Android or iOS, we can use the device’s secure enclave.
To connect to an authenticator, we use what’s called the Client to Authenticator Protocol (CTAP). CTAP allows us to connect to hardware over different connections through the browser. For example, we can connect via CTAP using an NFC, Bluetooth, or a USB connection. This is useful in cases where we want to log in on one device while another device contains our passkeys, as is the case on some operating systems that do not support passkeys at the time of writing.
A passkey is built off another web API called WebAuthn. While the APIs are very similar, the WebAuthn API differs in that passkeys allow for cloud syncing of the cryptographic keys and do not require knowledge of whom the user is to log in, as that information is stored in a passkey with its Relying Party (RP) information. The two APIs otherwise share the same flows and cryptographic operations.
Storing Passkeys
Let’s look at an extremely high-level overview of how I’ve stored and kept track of passkeys in my demo repo. This is how the database is structured.
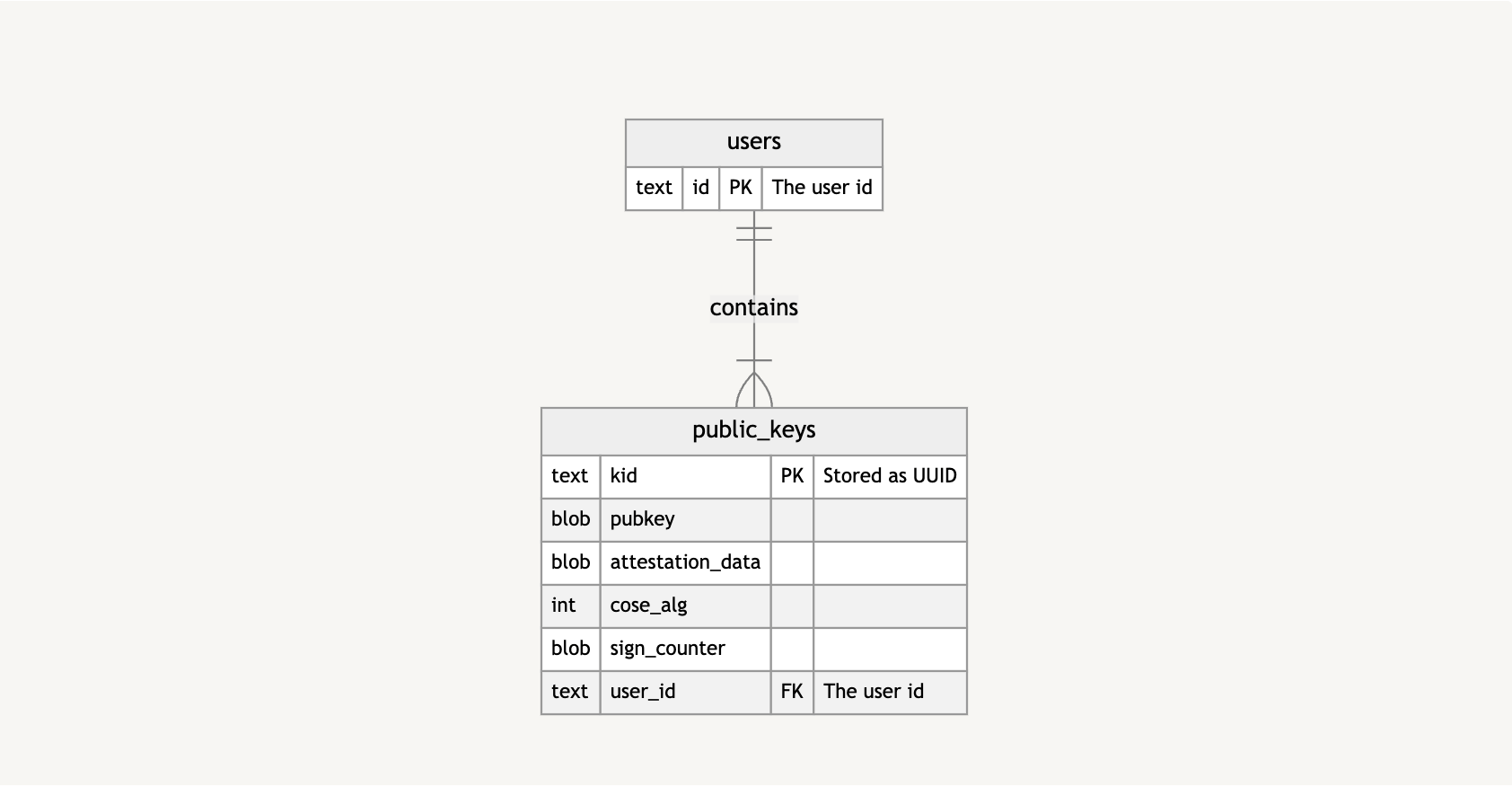
Basically, a users table has public_keys, which, in turn, contains information about the public key, as well as the public key itself.
From there, I’m caching certain information, including challenges to verify authenticity and data about the sessions in which the challenges take place.
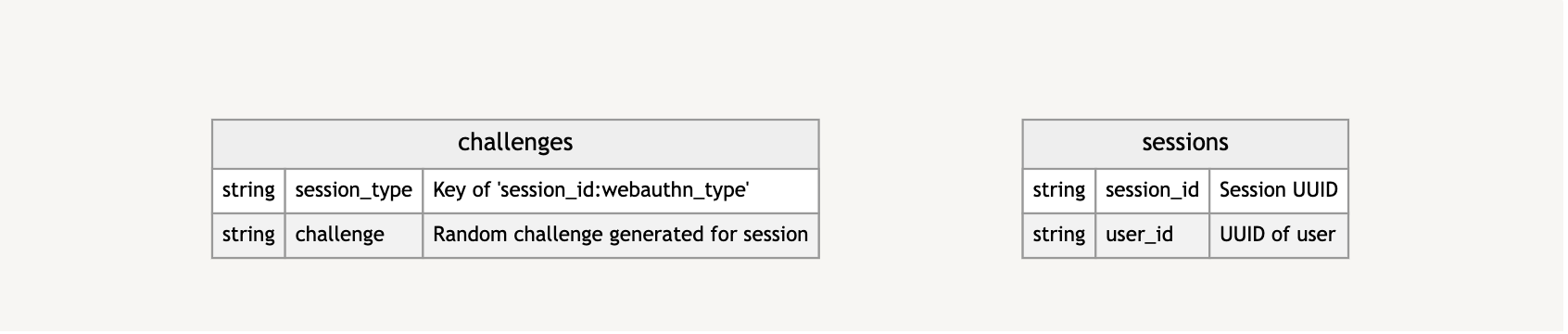
Again, this is only a high-level look to give you a clearer idea of what information is stored and how it is stored.
Verifying Passkeys
There are several entities involved in passkey:
The authenticator, which we previously mentioned, generates our key material.
The client that triggers the passkey generation process via the navigator.credentials.create call.
The Relying Party takes the resulting public key from that call and stores it to be used for subsequent verification.

In our case, you are the client and the Relying Party is the website server you are trying to sign up and log into. The authenticator can either be your mobile phone, a hardware key, or some other device capable of generating your cryptographic keys.
Passkeys are used in two phases: the attestation phase and the assertion phase. The attestation phase is likened to a registration that you perform when first signing up for a service. Instead of an email and password, we generate a passkey.
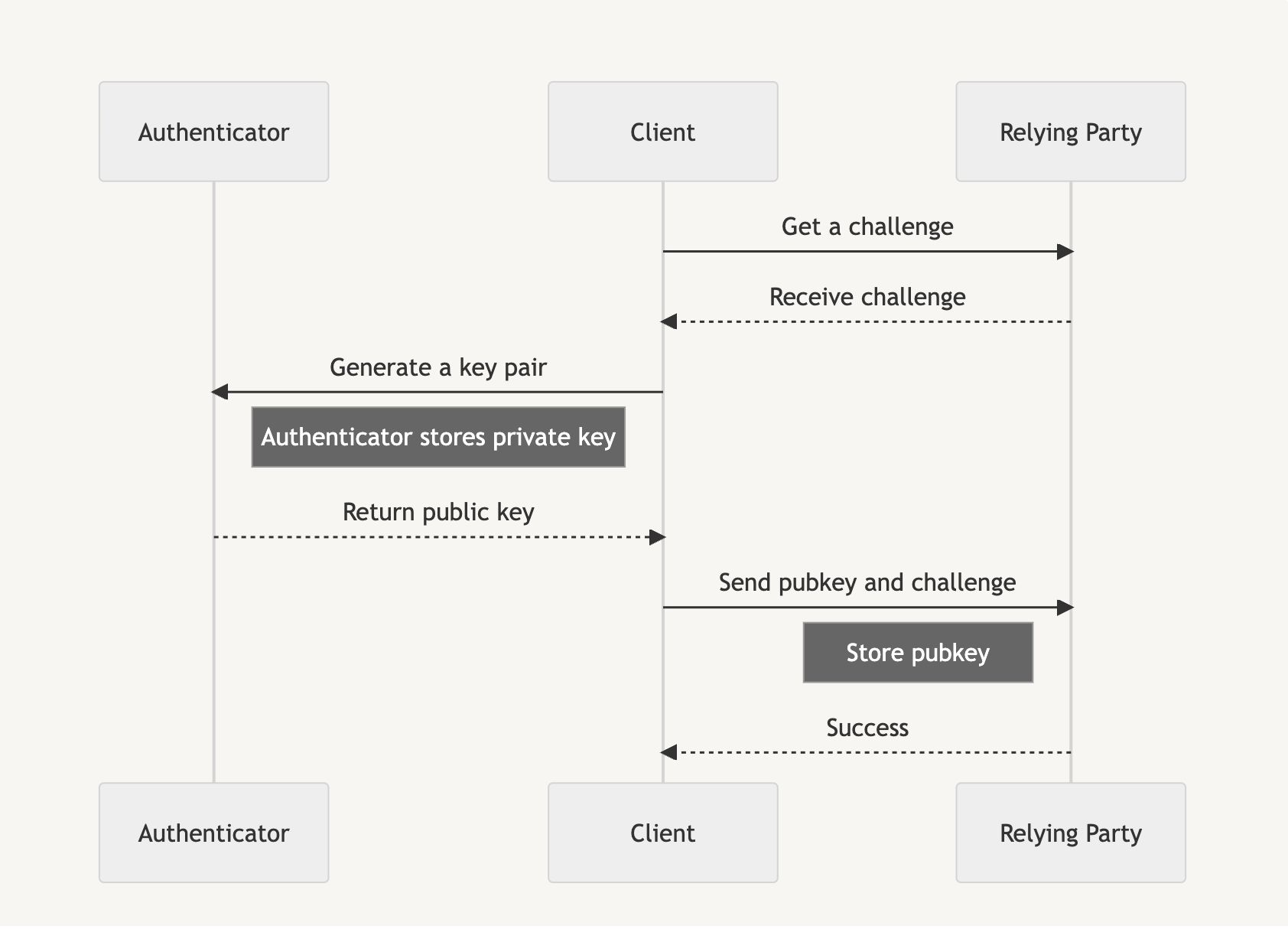
Assertion is similar to logging in to a service after we are registered, and instead of verifying with a username and password, we use the generated passkey to access the service.
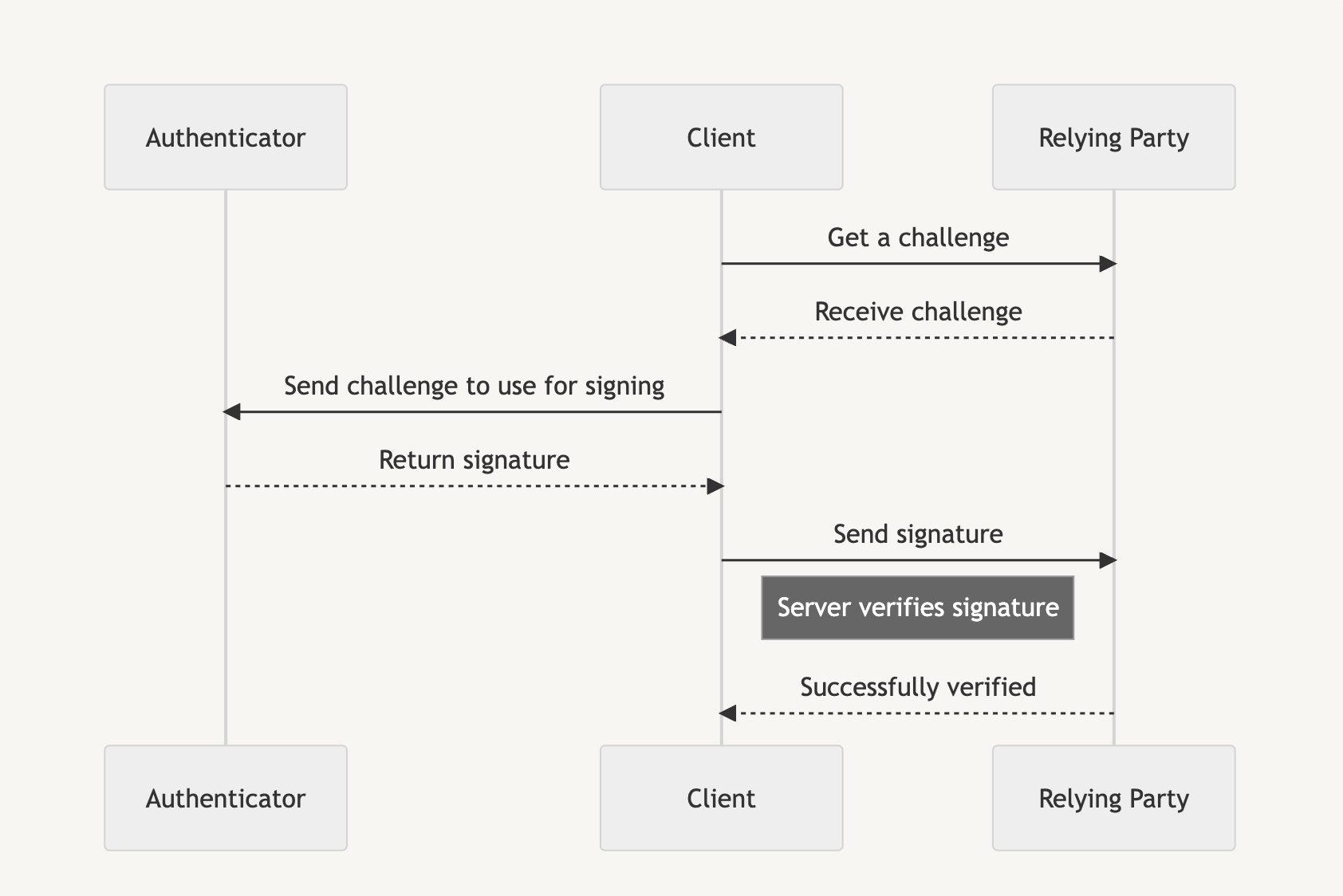
Each phase initially requires a random challenge generated by the Relying Party, which is then signed by the authenticator before the client sends the signature back to the Relying Party to prove account ownership.
Browser API Usage
We’ll be looking at how the browser constructs and supplies information for passkeys so that you can store and utilize it for your login process. First, we’ll start with the attestation phase and then the assertion phase.
Attest To It
The following shows how to create a new passkey using the navigator.credentials.create API. From it, we receive an AuthenticatorAttestationResponse, and we want to send portions of that response to the Relying Party for storage.
const { challenge } = await (await fetch(“/attestation/generate”)).json(); // Server call mock to get a random challenge
const options = {
// Our challenge should be a base64-url encoded string
challenge: new TextEncoder().encode(challenge),
rp: {
id: window.location.host,
name: document.title,
},
user: {
id: new TextEncoder().encode(“my-user-id”),
name: ‘John’,
displayName: ‘John Smith’,
},
pubKeyCredParams: [ // See COSE algorithms for more: https://www.iana.org/assignments/cose/cose.xhtml#algorithms
{
type: ‘public-key’,
alg: -7, // ES256
},
{
type: ‘public-key’,
alg: -256, // RS256
},
{
type: ‘public-key’,
alg: -37, // PS256
},
],
authenticatorSelection: {
userVerification: ‘preferred’, // Do you want to use biometrics or a pin?
residentKey: ‘required’, // Create a resident key e.g. passkey
},
attestation: ‘indirect’, // indirect, direct, or none
timeout: 60_000,
};
// Create the credential through the Authenticator
const credential = await navigator.credentials.create({
publicKey: options
});
// Our main attestation response. See: https://developer.mozilla.org/en-US/docs/Web/API/AuthenticatorAttestationResponse
const attestation = credential.response as AuthenticatorAttestationResponse;
// Now send this information off to the Relying Party
// An unencoded example payload with most of the useful information
const payload = {
kid: credential.id,
clientDataJSON: attestation.clientDataJSON,
attestationObject: attestation.attestationObject,
pubkey: attestation.getPublicKey(),
coseAlg: attestation.getPublicKeyAlgorithm(),
};
The AuthenticatorAttestationResponse contains the clientDataJSON as well as the attestationObject. We also have a couple of useful methods that save us from trying to retrieve the public key from the attestationObject and retrieving the COSE algorithm of the public key: getPublicKey and getPublicKeyAlgorithm.
Let’s dig into these pieces a little further.
Parsing The Attestation clientDataJSON
The clientDataJSON object is composed of a few fields we need. We can convert it to a workable object by decoding it and then running it through JSON.parse.
type DecodedClientDataJSON = {
challenge: string,
origin: string,
type: string
};
const decoded: DecodedClientDataJSON = JSON.parse(new TextDecoder().decode(attestation.clientDataJSON));
const {
challenge,
origin,
type
} = decoded;
Now we have a few fields to check against: challenge, origin, type.
Our challenge is the Base64-url encoded string that was passed to the server. The origin is the host (e.g., https://my.passkeys.com) of the server we used to generate the passkey. Meanwhile, the type is webauthn.create. The server should verify that all the values are expected when parsing the clientDataJSON.
Decoding TheattestationObject
The attestationObject is a CBOR encoded object. We need to use a CBOR decoder to actually see what it contains. We can use a package like cbor-x for that.
import { decode } from ‘cbor-x/decode’;
enum DecodedAttestationObjectFormat {
none = ‘none’,
packed = ‘packed’,
}
type DecodedAttestationObjectAttStmt = {
x5c?: Uint8Array[];
sig?: Uint8Array;
};
type DecodedAttestationObject = {
fmt: DecodedAttestationObjectFormat;
authData: Uint8Array;
attStmt: DecodedAttestationObjectAttStmt;
};
const decodedAttestationObject: DecodedAttestationObject = decode(
new Uint8Array(attestation.attestationObject)
);
const {
fmt,
authData,
attStmt,
} = decodedAttestationObject;
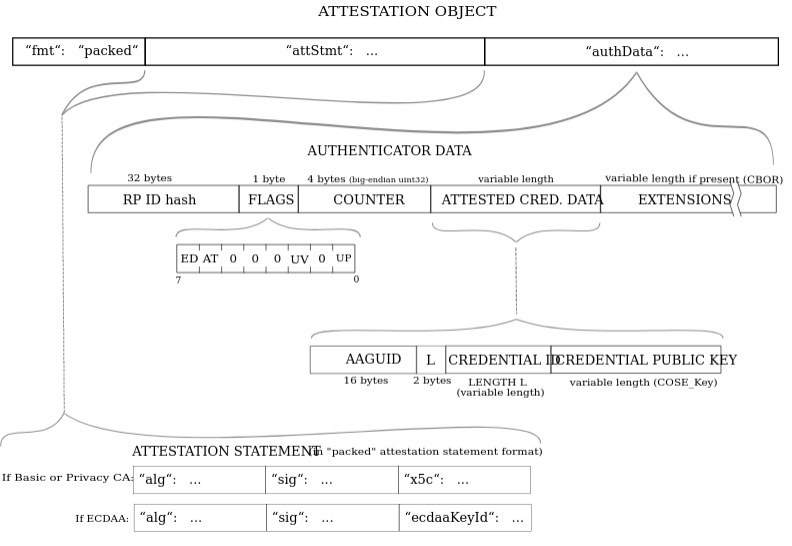
fmt will often be evaluated to “none” here for passkeys. Other types of fmt are generated through other types of authenticators.
Accessing authData
The authData is a buffer of values with the following structure:
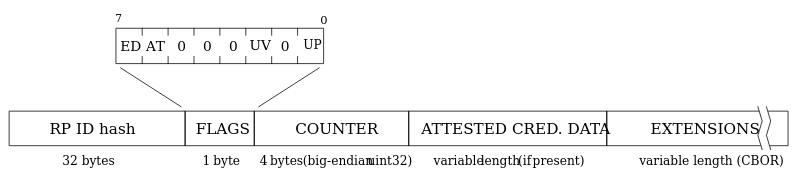
Name
Length (bytes)
Description
rpIdHash
32
This is the SHA-256 hash of the origin, e.g., my.passkeys.com.
flags
1
Flags determine multiple pieces of information (specification).
signCount
4
This should always be 0000 for passkeys.
attestedCredentialData
variable
This will contain credential data if it’s available in a COSE key format.
extensions
variable
These are any optional extensions for authentication.
It is recommended to use the getPublicKey method here instead of manually retrieving the attestedCredentialData.
A Note About The attStmt Object
This is often an empty object for passkeys. However, in other cases of a packed format, which includes the sig, we will need to perform some authentication to verify the sig. This is out of the scope of this article, as it often requires a hardware key or some other type of device-based login.
Retrieving The Encoded Public Key
The getPublicKey method can retrieve the Subject Public Key Info (SPKI) encoded version of the public key, which is a different from the COSE key format (more on that next) within the attestedCredentialData that the decodedAttestationObject.attStmt has. The SPKI format has the benefit of being compatible with a Web Crypto importKey function to more easily verify assertion signatures in the next phase.
// Example of importing attestation public key directly into Web Crypto
const pubkey = await crypto.subtle.importKey(
‘spki’,
attestation.getPublicKey(),
{ name: “ECDSA”, namedCurve: “P-256” },
true,
[‘verify’]
);
Generating Keys With COSE Algorithms
The algorithms that can be used to generate cryptographic material for a passkey are specified by their COSE Algorithm. For passkeys generated for the web, we want to be able to generate keys using the following algorithms, as they are supported natively in Web Crypto. Personally, I prefer ECDSA-based algorithms since the key sizes are quite a bit smaller than RSA keys.
The COSE algorithms are declared in the pubKeyCredParams array within the AuthenticatorAttestationResponse. We can retrieve the COSE algorithm from the attestationObject with the getPublicKeyAlgorithm method. For example, if getPublicKeyAlgorithm returned -7, we’d know that the key used the ES256 algorithm.
Name
Value
Description
ES512
-36
ECDSA w/ SHA-512
ES384
-35
ECDSA w/ SHA-384
ES256
-7
ECDSA w/ SHA-256
RS512
-259
RSASSA-PKCS1-v1_5 using SHA-512
RS384
-258
RSASSA-PKCS1-v1_5 using SHA-384
RS256
-257
RSASSA-PKCS1-v1_5 using SHA-256
PS512
-39
RSASSA-PSS w/ SHA-512
PS384
-38
RSASSA-PSS w/ SHA-384
PS256
-37
RSASSA-PSS w/ SHA-256
Responding To The Attestation Payload
I want to show you an example of a response we would send to the server for registration. In short, the safeByteEncode function is used to change the buffers into Base64-url encoded strings.
type AttestationCredentialPayload = {
kid: string;
clientDataJSON: string;
attestationObject: string;
pubkey: string;
coseAlg: number;
};
const payload: AttestationCredentialPayload = {
kid: credential.id,
clientDataJSON: safeByteEncode(attestation.clientDataJSON),
attestationObject: safeByteEncode(attestation.attestationObject),
pubkey: safeByteEncode(attestation.getPublicKey() as ArrayBuffer),
coseAlg: attestation.getPublicKeyAlgorithm(),
};
The credential id (kid) should always be captured to look up the user’s keys, as it will be the primary key in the public_keys table.
From there:
The server would check the clientDataJSON to ensure the same challenge is used.
The origin is checked, and the type is set to webauthn.create.
We check the attestationObject to ensure it has an fmt of none, the rpIdHash of the authData, as well as any flags and the signCount.
Optionally, we could check to see if the attestationObject.attStmt has a sig and verify the public key against it, but that’s for other types of WebAuthn flows we won’t go into.
We should store the public key and the COSE algorithm in the database at the very least. It is also beneficial to store the attestationObject in case we require more information for verification. The signCount is always incremented on every login attempt if supporting other types of WebAuthn logins; otherwise, it should always be for 0000 for a passkey.
Asserting Yourself
Now we have to retrieve a stored passkey using the navigator.credentials.get API. From it, we receive the AuthenticatorAssertionResponse, which we want to send portions of to the Relying Party for verification.
const { challenge } = await (await fetch(“/assertion/generate”)).json(); // Server call mock to get a random challenge
const options = {
challenge: new TextEncoder().encode(challenge),
rpId: window.location.host,
timeout: 60_000,
};
// Sign the challenge with our private key via the Authenticator
const credential = await navigator.credentials.get({
publicKey: options,
mediation: ‘optional’,
});
// Our main assertion response. See: <https://developer.mozilla.org/en-US/docs/Web/API/AuthenticatorAssertionResponse>
const assertion = credential.response as AuthenticatorAssertionResponse;
// Now send this information off to the Relying Party
// An example payload with most of the useful information
const payload = {
kid: credential.id,
clientDataJSON: safeByteEncode(assertion.clientDataJSON),
authenticatorData: safeByteEncode(assertion.authenticatorData),
signature: safeByteEncode(assertion.signature),
};
The AuthenticatorAssertionResponse again has the clientDataJSON, and now the authenticatorData. We also have the signature that needs to be verified with the stored public key we captured in the attestation phase.
Decoding The Assertion clientDataJSON
The assertion clientDataJSON is very similar to the attestation version. We again have the challenge, origin, and type. Everything is the same, except the type is now webauthn.get.
type DecodedClientDataJSON = {
challenge: string,
origin: string,
type: string
};
const decoded: DecodedClientDataJSON = JSON.parse(new TextDecoder().decode(assertion.clientDataJSON));
const {
challenge,
origin,
type
} = decoded;
Understanding The authenticatorData
The authenticatorData is similar to the previous attestationObject.authData, except we no longer have the public key included (e.g., the attestedCredentialData ), nor any extensions.
Name
Length (bytes)
Description
rpIdHash
32
This is a SHA-256 hash of the origin, e.g., my.passkeys.com.
flags
1
Flags that determine multiple pieces of information (specification).
signCount
4
This should always be 0000 for passkeys, just as it should be for authData.
Verifying The signature
The signature is what we need to verify that the user trying to log in has the private key. It is the result of the concatenation of the authenticatorData and clientDataHash (i.e., the SHA-256 version of clientDataJSON).
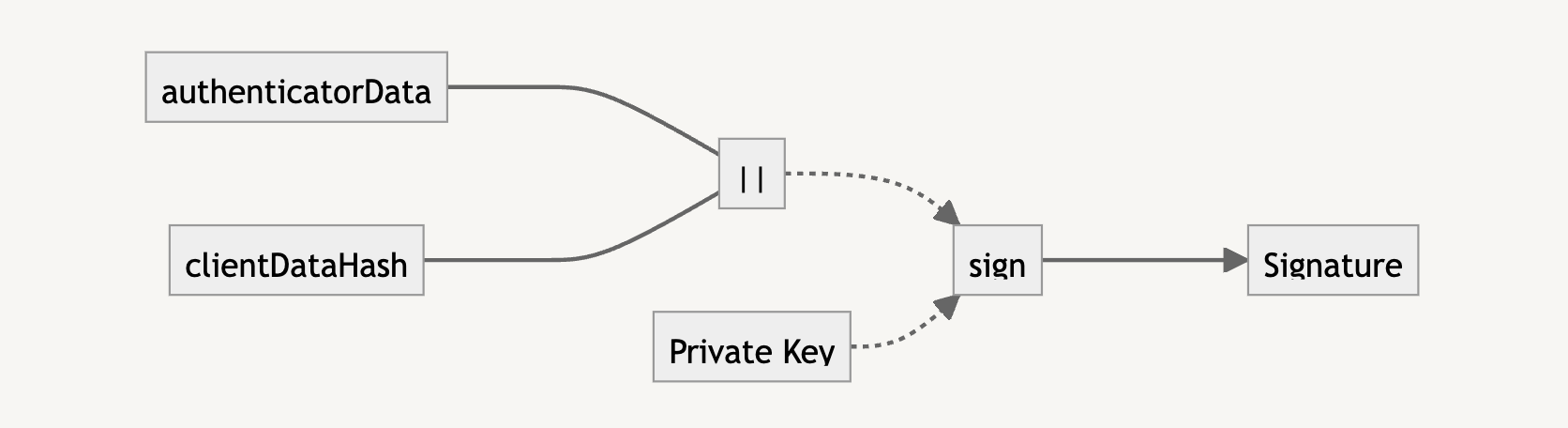
To verify with the public key, we need to also concatenate the authenticatorData and clientDataHash. If the verification returns true, we know that the user is who they say they are, and we can let them authenticate into the application.
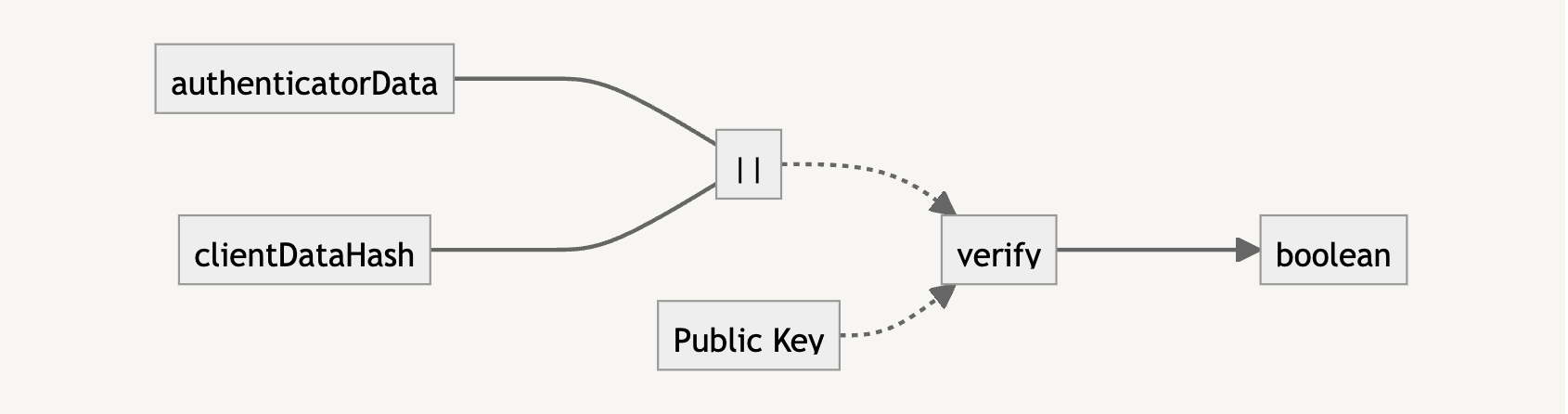
Here’s an example of how this is calculated:
const clientDataHash = await crypto.subtle.digest(
‘SHA-256′,
assertion.clientDataJSON
);
// For concatBuffer see: <https://github.com/nealfennimore/passkeys/blob/main/src/utils.ts#L31>
const data = concatBuffer(
assertion.authenticatorData,
clientDataHash
);
// NOTE: the signature from the assertion is in ASN.1 DER encoding. To get it working with Web Crypto
//We need to transform it into r|s encoding, which is specific for ECDSA algorithms)
//
// For fromAsn1DERtoRSSignature see: <https://github.com/nealfennimore/passkeys/blob/main/src/crypto.ts#L60>’
const isVerified = await crypto.subtle.verify(
{ name: ‘ECDSA’, hash: ‘SHA-256’ },
pubkey,
fromAsn1DERtoRSSignature(signature, 256),
data
);
Sending The Assertion Payload
Finally, we get to send a response to the server with the assertion for logging into the application.
type AssertionCredentialPayload = {
kid: string;
clientDataJSON: string;
authenticatorData: string;
signature: string;
};
const payload: AssertionCredentialPayload = {
kid: credential.id,
clientDataJSON: safeByteEncode(assertion.clientDataJSON),
authenticatorData: safeByteEncode(assertion.authenticatorData),
signature: safeByteEncode(assertion.signature),
};
To complete the assertion phase, we first look up the stored public key, kid.
Next, we verify the following:
clientDataJSON again to ensure the same challenge is used,
The origin is the same, and
That the type is webauthn.get.
The authenticatorData can be used to check the rpIdHash, flags, and the signCount one more time. Finally, we take the signature and ensure that the stored public key can be used to verify that the signature is valid.
At this point, if all went well, the server should have verified all the information and allowed you to access your account! Congrats — you logged in with passkeys!
No More Passwords?
Do passkeys mean the end of passwords? Probably not… at least for a while anyway. Passwords will live on. However, there’s hope that more and more of the industry will begin to use passkeys. You can already find it implemented in many of the applications you use every day.
Passkeys was not the only implementation to rely on cryptographic means of authentication. A notable example is SQRL (pronounced “squirrel”). The industry as a whole, however, has decided to move forth with passkeys.
Hopefully, this article demystified some of the internal workings of passkeys. The industry as a whole is going to be using passkeys more and more, so it’s important to at least get acclimated. With all the security gains that passkeys provide and the fact that it’s resistant to phishing attacks, we can at least be more at ease browsing the internet when using them.