Original Source: https://smashingmagazine.com/2020/11/reactive-variables-graphql-apollo-client/
In this article, we will look at how to set up reactive variables, how the GraphQL cache polices come into place in defining read and writes to the cache, and provide the ability for developers to add types that exist on the client-side alone so that we can structure queries for client-side variables same way we can for remote GraphQL data. After learning more about the fundamentals of reactive variables, we will build a simple app that switches the theme of our application to either dark mode or light mode based on the value of our reactive variable. We will be looking at how to query a reactive variable, how to update the value stored in a reactive variable, and how the change in value triggers updates in components that depend on the reactive variable for certain actions to occur.
The target audience for this article would include software developers who already use GraphqQL with state management tools like Context API or Redux and willing to explore a new pattern of handling state management in GraphQL, or GraphQL beginners who are looking for effective ways to handle globally shared local state within GraphQL without Making things too complicated with external tooling. To follow along with this, you should have an existing knowledge of ReactJS and CSS too.
A Quick Introduction To GraphQL
With GraphQL, you get exactly what you need, and also get the data returned as well as structured how you need it.
“GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.”
— GraphQL website
What Is Apollo Client In GraphQL?
Apollo Client helps you avoid manually tracking loading and error states. It also provides the ability to use GraphQL with modern React patterns like hooks, and so on.
“Apollo Client is a comprehensive state management library for JavaScript that enables you to manage both local and remote data with GraphQL. Use it to fetch, cache, and modify application data, all while automatically updating your UI.”
— “Introduction to Apollo Client,” Apollo Docs
Let’s define some terms here that you will need to understand to move forward:
Variable
A variable is a name you give to an assigned memory location where a value is stored. The variable name is used as a reference to the value stored in it when you need to make use of it.
Reactivity
We will explain reactivity as something that triggers change on its dependents when an update is passed to it. Like the local state in React triggers component updates, the reactive variables in Apollo GraphQL also automatically trigger component updates based on changes.
State management is a really important part of building a modern application. Having a global state is important when different components or screens require access to the same state value and possibly trigger changes when that particular state is changed.
In the next section, we will look at how to set up a reactive variable.
Writing Our First Reactive Variable
Here’s what a reactive variable looks like:
import { makeVar } from ‘@apollo/client’;
const myReactiveVariable = makeVar(/** An initial value can be passed in here.**/)
The makeVar is imported from Apollo Client and is used to declare our a reactive variable. The makeVar takes an initial value that the reactive variable would hold. The ease of constructing a reactive variable is amazing.
There are two ways to read data from our created reactive variable. The easiest way is to call our declared reactive variable which we have created above, as a function without an argument:
const variable = myReactiveVariable();
Getting the value of a reactive variable is that easy. In the code block above, we declared a variable that holds our reactive variable which was called without an argument to read the data it already holds.
We can also get the value of a reactive variable with the useQuery syntax we normally would use to fetch remote data in GraphQL. To explain how we can do this, let’s look at the Cache type and field policies.
Type And Field Policies
The cache type and field policies help you define how a specific field in your Apollo Client cache is read and written to. You do this by providing field policies to the constructor of inMemoryCache. Each field policy is defined inside the typePolicy that corresponds to the type which contains the field. Let’s define a typePolicy called Query and define a field policy for accessing a field called myReactiveVariable.
import { InMemoryCache } from ‘@apollo/client’;
// Here we import our reactive variable which we declared in another
// component
import { myReactiveVariable } from ‘./reactivities/variable.js’;
// The field policies hold the initial cached state of a field.
export default new InMemoryCache({
typePolicies: {
Query: {
fields: {
myReactiveVariable: {
read() {
return myReactiveVariable();
}
}
}
}
}
})
In the code snippet above, we declared a type called Query and defined a field called myReactiveVariable. Next, we added a read function that specifies what happens when the field’s cached value is read. Here’s what happens when the myReactiveVariable field cached value is being read:
We pass in the reactive variable we had declared in another component and imported here as the value the field returns.
Now that we have defined our typePolicies and fieldPolicies, let us go ahead and write our query to get the value store in our reactive variable. Here’s what the query would look like:
import { gql } from “@apollo/client”;
export const GET_REACTIVE_VARIABLE = gql`
query getReractiveVariable{
myReactiveVariable @client
}
`
The gql template literal tag we imported from Apollo Client above is used to write a GraphQL query in Apollo client.
The query name myReactiveVariable should match the field name declared in the field policy. If you have been using GraphQL, you will notice that this querying pattern is identical to the normal query you would write if it were to be a remote GraphQL API we were querying. The only difference is the @client placed after the field name. This instructs Apollo to resolve this particular query on the client and not on any external API.
That’s it! We have successfully set up our first reactive variable. The process looks a little bit lengthy initially but subsequently, you can declare a new reactive variable by simply declaring the reactive variable and adding a field policy for it.
To fetch the reactive variable, you can use the useQuery hook in any component where you need it.
Here’s an example.
import { useQuery } from ‘@apollo/client’;
import { GET_REACTIVE_VARIABLE } from ‘FILE_PATH_TO_YOUR_QUERY_FILE’;
const {loading, error, data} = useQeury(GET_DARK_MODE);
// you can track loading, error states, and data the same way with a normal query in Apollo
In the above code, we imported useQuery from @apollo/client. Next, we imported the GET_REACTIVE_VARIABLE query from the file it was exported from.
Lastly, we pass on to the useQuery hook in our query, and destructure loading, error, and data from it.
Modifying A reactive variable
Apollo client provides a beautiful way to modify a reactive variable — calling the function returned by makeVar and pass in a single argument to the function. The argument passed in is the new value the reactive variable will hold. Let us look at an example below where we modify our reactive variable which we declared above:
import { myReactiveVariable } from ‘PATH_TO_OUR_REACTIVE_VARIABLE_FILE’
myReactiveVariable(“A new value is in!”);
In the above code, we import myReactiveVariable and we update it by calling the variable and placing the new value inside of it.
It is so easy to update the values of a reactive variable. Once the value in a reactive variable is updated, corresponding actions are triggered in components that depend on the variable and the user-interface is adjusted automatically.
In the next section, we will build out a simple theme-changing application that switches themes from dark mode to light mode with a click of a button. The button changes itself based on the value of the current theme. This will help us put all that we have learned together by building out something that fully and simply illustrates the concept of reactive variables and show how the user interface is automatically triggered when the reactive variable is updated.
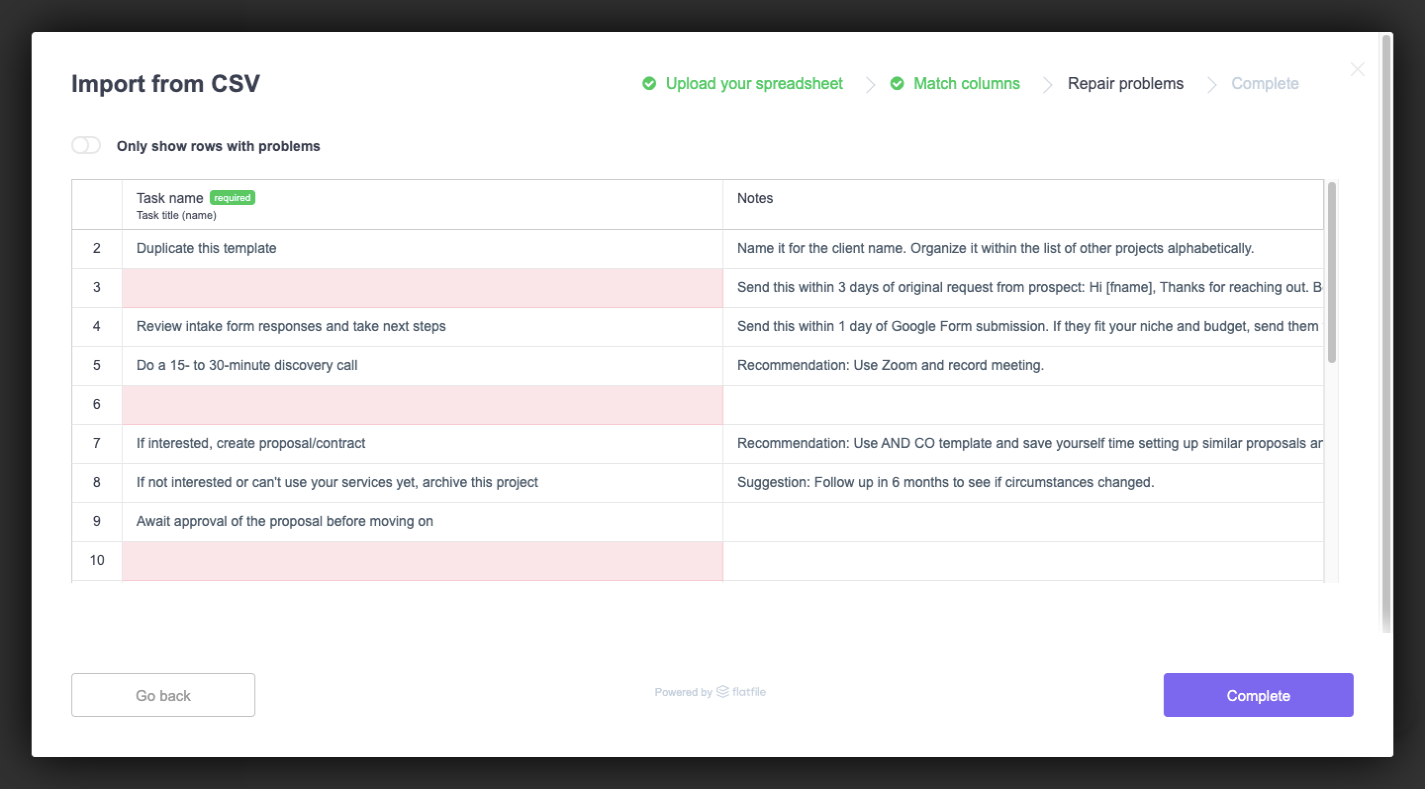
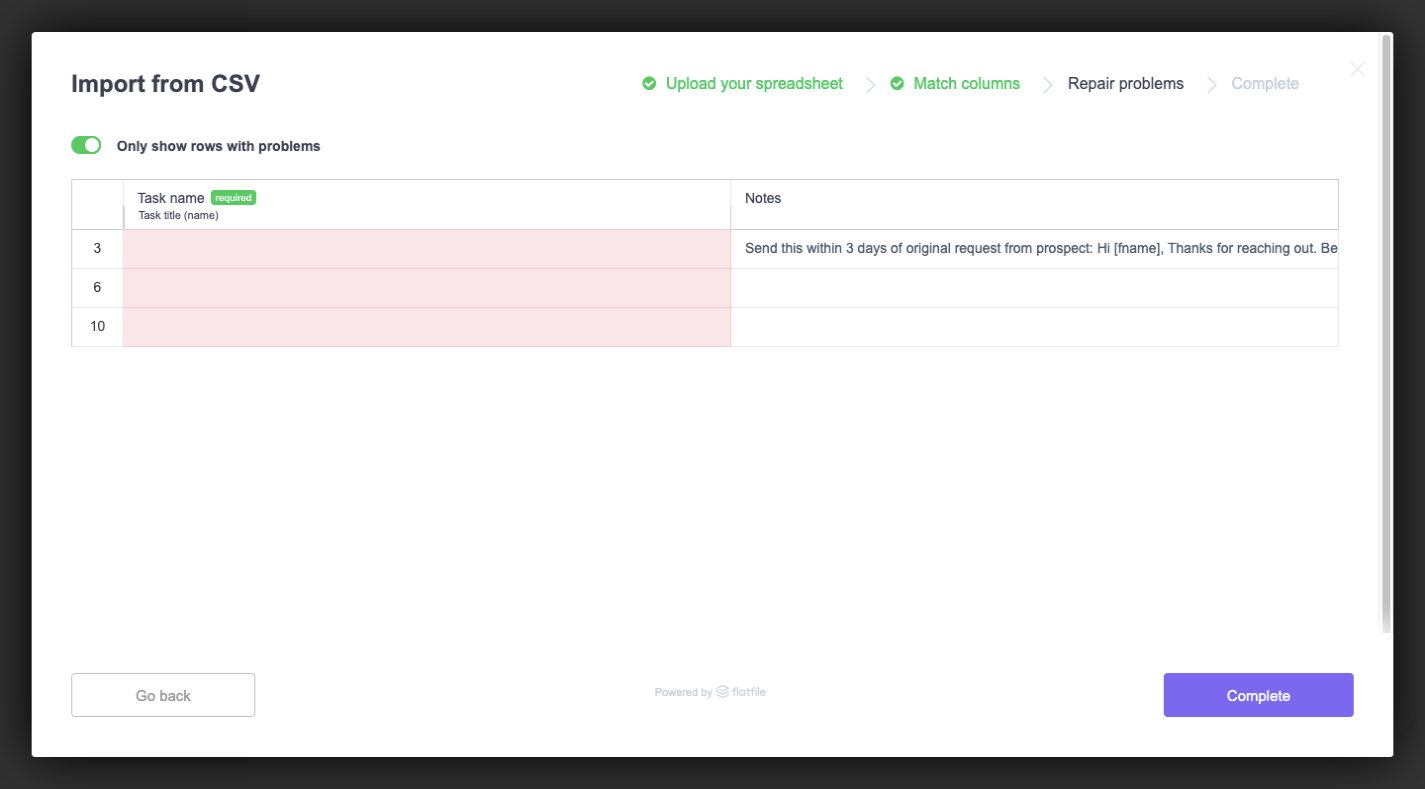
Here’s what our result will look like:
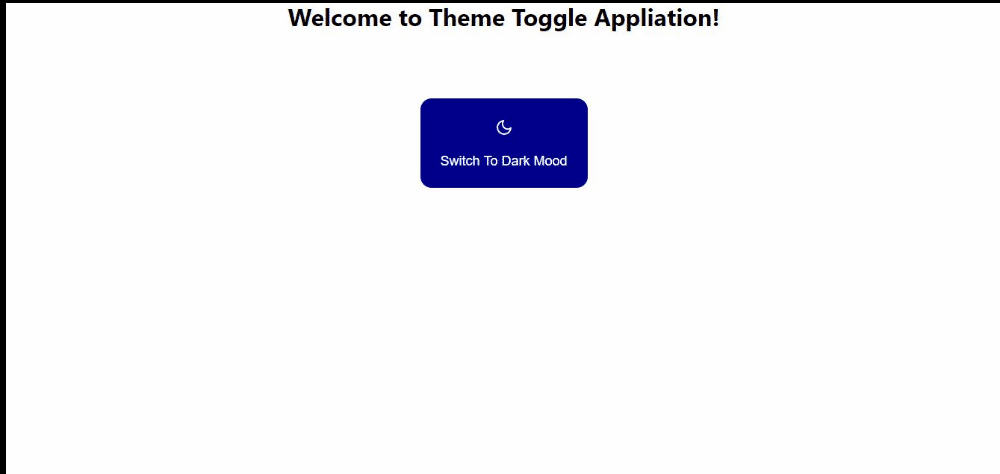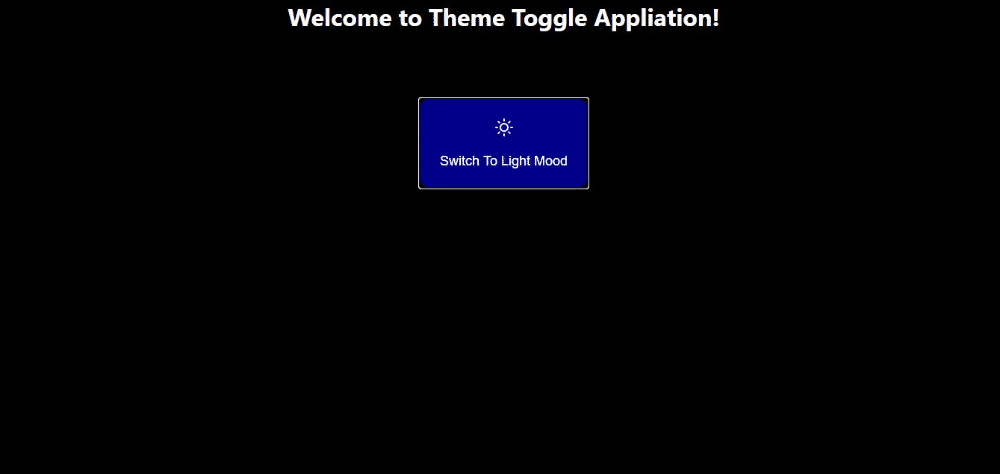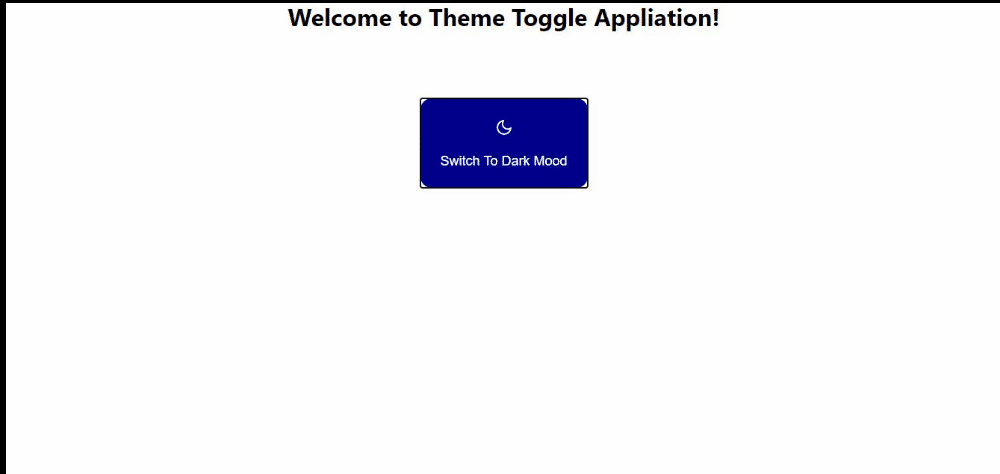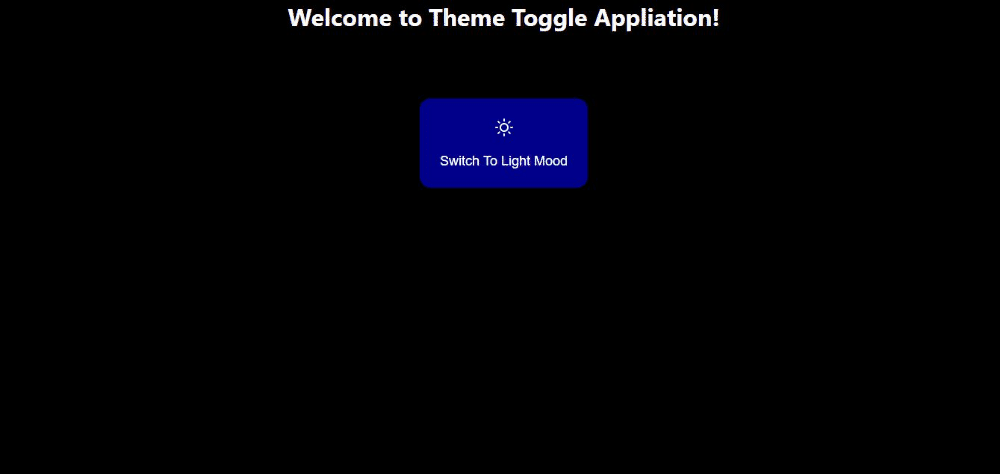 (Large preview)
(Large preview)
Let’s begin.
Setup
First, we create a new React app.
npx create-react-app theme_toggle
Next, let’s install the necessary libraries we need for Apollo and GraphQL including the react-feather library to get our icons and react-router-dom to setup routing
npm install @apollo/client graphql react-feather react-router-dom
Once we are done with all the installations, let’s go ahead and set up our graphQL, including defining our darkMode reactive variable.
Create a folder called graphql inside the src folder and then create a sub-folder called reactivities to house all the reactive variables. Here’s how the folder tree would look like:
src > graphql > reactivities > themeVariable.js
I decided to arrange our file and folder structure simulating a real-world use case so follow along.
Let’s go ahead to declare our reactive variable in the themeVariable.js file we just created:
import { makeVar, gql } from “@apollo/client”;
export const darkMode = makeVar(false);
Next, inside the same file let’s construct our query to get our reactive variable and specify that the query should be resolved on the client-side. We can decide to create a separate folder to house all our query, especially when we have many queries in our application, but for the sake of this tutorial, we will write the query inside the same file as the reactive variable and export them individually:
import { makeVar, gql } from “@apollo/client”;
export const darkMode = makeVar(false);
// This is the query to get the darkMode reactive variable.
export const GET_DARK_MODE = gql`
query getDarkMode{
darkMode @client
}
`
In the above piece of code, we see how straightforward it was to declare a reactive variable with the makeVar() and passed in an initial value of false for our new variable. Next, we imported gql from Apollo client and used it in writing our query.
Next, let’s create our cache.js file and define our type and field policies to control how variables will be queried and structured:
Create a file called cache.js inside the graphql folder. Inside cache.js here’s how we declare our policies:
import { InMemoryCache } from ‘@apollo/client’;
import { darkMode } from ‘./reactivities/themeVariable’;
export default new InMemoryCache({
typePolicies: {
Query: {
fields: {
darkMode: {
read() {
return darkMode();
}
}
}
}
}
})
In the above code, first, we imported inMemoryCache from Apollo client, and we imported our reactive variable from the file path where we stored it.
Next, we created a new instance of inMemoryCache and our field policy is defined inside of the typePolicy object. The code above defines a field policy for the darkMode field on the Query type.
There’s one final step to complete our setup for Apollo for our React app, we need to create a client.js file. The client.js file is a file you’re already familiar with if you use GraphQL before now. It holds the ApolloClient constructor which would finally get passed into the ApolloProvider on a top-level file (usually the index.js file). Our client.js file should be located directly inside the src folder.
src > client.js
import { ApolloClient } from ‘@apollo/client’;
import cache from ‘./graphql/cache’;
const client = new ApolloClient({
cache,
connectToDevTools: true,
});
export default client;
Here’s what we did above. We imported ApolloClient. Next, we imported our cache from where it was previously declared. Inside our ApolloClient constructor, we passed in our cache which we imported and set connectToDevTools as true to enable us to use the Apollo Dev Tools in our browser.
Finally, we need to pass in the new ApolloClient instance which we exported as client into ApolloProvider in our top-level index.js file inside the src folder. Open the index.js file and replace the code there with this.
import React from ‘react’;
import ReactDOM from ‘react-dom’;
import { ApolloProvider } from ‘@apollo/client’;
import ‘./index.css’;
import App from ‘./App’;
import client from ‘./client’;
ReactDOM.render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>,
document.getElementById(‘root’)
);
In the above code block, we wrapped our App component with the ApolloProvider and passed client (which we imported) to the Apollo provider. We did this in the top-level scope so that our entire app can access the ApolloProvider and the client.
We have successfully finished everything in the setup of Apollo and the reactive variable. You’ll notice that many things we did here were related to setting up Apollo which you would still have done even if you were using Apollo with other external API for managing context.
Since we are done with everything we need to set up Apollo and create our reactive variable, let’s now go ahead and set up our page and routing.
We would only have one route to a page called landingPage.jsx. Inside the src folder, create a folder called pages to house all the pages (in our case, we have just one page) and create a file called landingPage.jsx in it.
src > pages > landingPage.jsx
Inside our newly created page, let’s create a functional component with a h1 tag containing or heading. Here’s what will be in it.
import React from ‘react’;
const LandingPage = () => {
return (
<div
style={{
height: ‘100vh’,
backgroundColor: ‘white’,
}}
>
<h1>Welcome to Theme Toggle Appliation!</h1>
</div>
)
}
export default LandingPage
Next, let’s create our button component. Inside src, create a folder called components, and create a button.jsx file.
src > components > button.jsx
Inside our button component, here are the things we should import icons from react-feather, the useQuery hook from apollo/client, our query and reactive variable from the file it was exported from.
import React from ‘react’
import { Moon, Sun } from ‘react-feather’;
import { useQuery } from ‘@apollo/client’;
import { GET_DARK_MODE, darkMode as reactiveDarkMode } from ‘../graphql/reactivities/themeVariable’;
Inside the button component, let’s query our GraphQL client with the GET_DARK_MODE query like how we would normally query in GraphQL with Apollo.
…
const ButtonComponent = () => {
{loading, error, data} = useQuery(GET_DARK_MODE);
return (…)
}
export default ButtonComponent;
Next, we want to change the buttons based on the boolean value of our reactive variable that will be returned from data. To do this, we will create two buttons and use a ternary operator to display them conditionally based on the boolean value of our reactive variable:
…
const ButtonComponent = () => {
const {loading, error, data} = useQuery(GET_DARK_MODE);
return (
<div>
{
data.darkMode ? (
<button
style={{
backgroundColor: ‘#00008B’,
border: ‘none’,
padding: ‘2%’,
height: ‘120px’,
borderRadius: ’15px’,
color: ‘white’,
fontSize: ’18px’,
marginTop: ‘5%’,
cursor: ‘pointer’
}}
onClick={toggleMode}
>
<Sun />
<p>Switch To Light Mood</p>
</button>
) 🙁
<button
style={{
backgroundColor: ‘#00008B’,
border: ‘none’,
padding: ‘2%’,
height: ‘120px’,
borderRadius: ’15px’,
color: ‘white’,
fontSize: ’18px’,
marginTop: ‘5%’,
cursor: ‘pointer’
}}
onClick={toggleMode}
>
<Moon />
<p>Switch To Dark Mood</p>
</button>
)
}
</div>
)
}
export default ButtonComponent;
In the above code, we displayed both buttons conditionally with the ternary operator to display when the value of data.darkMode is either true or false. Our initial value as declared in our themeVariable.js is false.
Note: Remember that we can pull out darkMode from the data because we declared it this way in our cache.js field policy.
We added some CSS to the buttons to make them look better and also added the icons we imported from react-feather to each button.
If you noticed we had an onClick property passed into each button which called toggleMode. Let’s declare the function above but still inside the ButtonComponent:
…
const ButtonComponent = () => {
const toggleMode = () => {
console.log(“Clicked toggle mode!”)
}
return (…)
}
export default ButtonComponent;
Currently, we have a console.log() inside the toggleMode function. In a later part of this article, we will come back to properly write this function to update the value of the reactive variable.
Now let’s go back to the ladingPage.jsx file we created before now and add the button we just created:
import React from ‘react’;
import ButtonComponent from ‘../components/button’;
const LandingPage = () => {
return (
<div
style={{
height: ‘100vh’,
backgroundColor: ‘white’,
}}
>
<h1>Welcome to Theme Toggle Appliation!</h1>
<ButtonComponent />
</div>
)
}
export default LandingPage
To add the button, we simply imported it into our page and added it below the h1 element we already had on the page.
Here’s how our web app looks like at the moment.
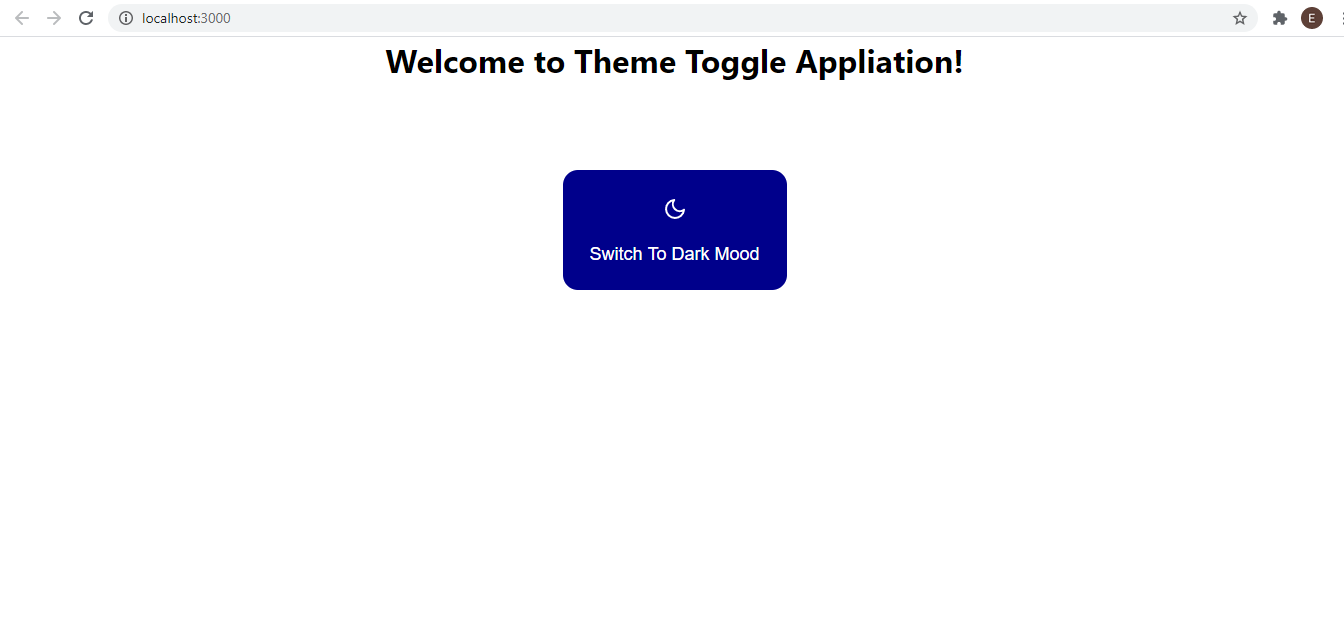
We are almost done building our app. Next, let’s change the background and text color of the page in the landingPage.jsx style to conditionally be black or white based on the boolean value of our reactive variable which would be toggled in the button component later. To do this, we will also use the useQuery hook to get the current value of our reactive variable.
Our landingPage.jsx file will finally look like this:
import React from ‘react’
import { useQuery } from ‘@apollo/client’;
import ButtonComponent from ‘../components/button’;
import { darkMode, GET_DARK_MODE } from ‘../graphql/reactivities/themeVariable’;
const LandingPage = () => {
const {loading, error, data} = useQuery(GET_DARK_MODE);
return (
<div style={{ height: ‘100vh’, backgroundColor: data.darkMode ? ‘black’ : ‘white’, color: data.darkMode ? ‘white’ : ‘black’ }}>
<h1>Welcome to Theme Toggle Appliation!</h1>
<ButtonComponent />
</div>
)
}
export default LandingPage
Pay attention to the way we change the backgroundColor and color of the div container conditionally based on the boolean value of the reactive variable returned. We make use of a ternary operator to set the backgroundColor to black or white depending on the value of data.darkMode. The same thing should be done for the value of color. This is all we need to for the landingPage.jsx component.
The final thing we will need to do to get our application to be working is to make our toggleMode function in the button component able to modify the reactive variable on click of the button. Let’s look at how to modify a reactive variable again, this time, in a real app example.
Modifying A Reactive Variable
As we’ve previously learned, to modify a reactive variable, all you need to do is to call the function returned by makeVar and pass in the new value inside of it. Here’s how that will work in our case:
Go to the button component and do this:
…
import { GET_DARK_MODE, darkMode } from ‘../graphql/reactivities/themeVariable’;
const ButtonComponent = () => {
const toggleMode = () => {
darkMode(!darkMode)
}
return (…)
}
export default ButtonComponent;
First, we imported the GET_DARK_MODE query and the darkMode reactive variable from the file they were exported from.
Next, we wrote an arrow function for toggleMode and called the darkMode function returned by makeVar and passed an invert of the current value it contained as the new value the reactive variable will carry when it is clicked on.
We have our entire app powered by a reactive variable and once there’s a change to the value held in the reactive variable, every component or page dependent on that variable for an action to trigger is updated and the user interface is updated with the current changes. We escaped all the hurdles of dispatch functions and other ambiguous steps we have to follow when using other state management libraries like Redux or Context API.
Conclusion
Reactive variables in Apollo client give you a sweet, easy to use, easy to update, and a consistent querying pattern with querying a regular remote GraphQL API. Learning to use reactive variables for state management is a plus to you because it gives you the flexibility of choice among many tools. reactive variables would enable you to manage locally shared global state among components without the extra boilerplate that would usually come with the dominant state management libraries that already exist.
Check out the finished code on GitHub.
Related Resources
Reactive Variables, Apollo Docs
Local State Management With Reactive Variables
Configuring The Cache, Apollo Docs















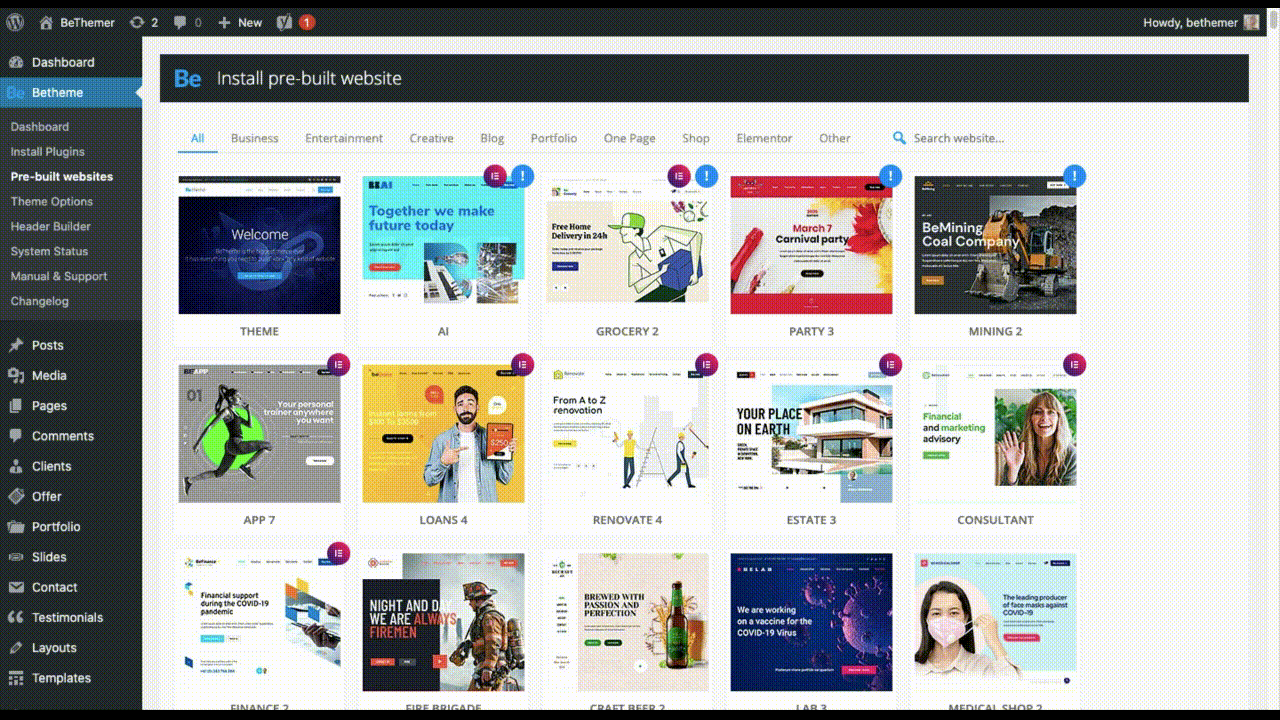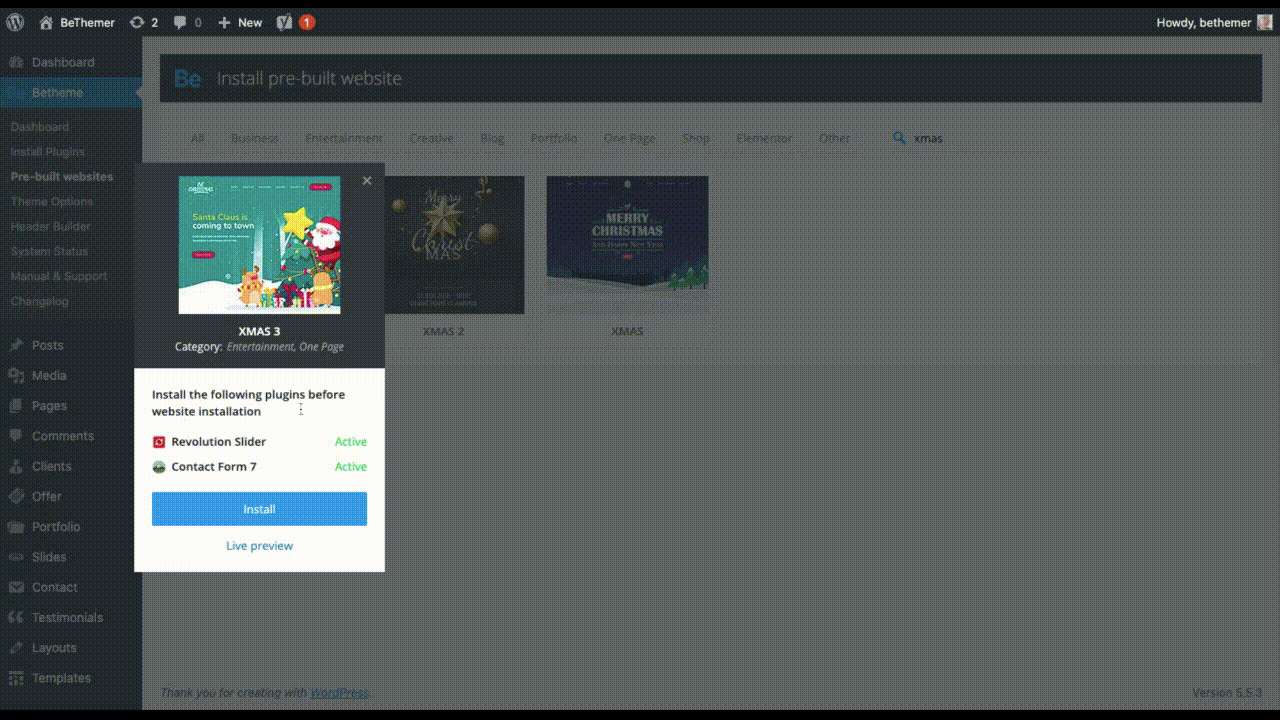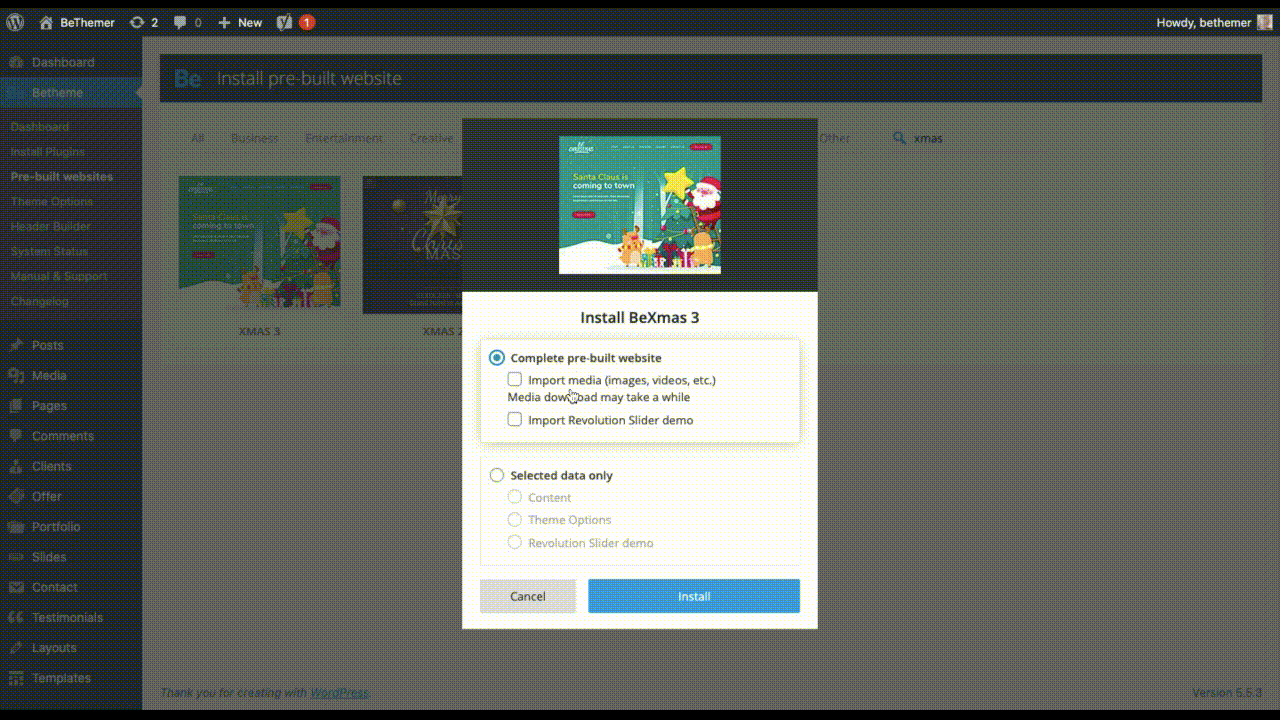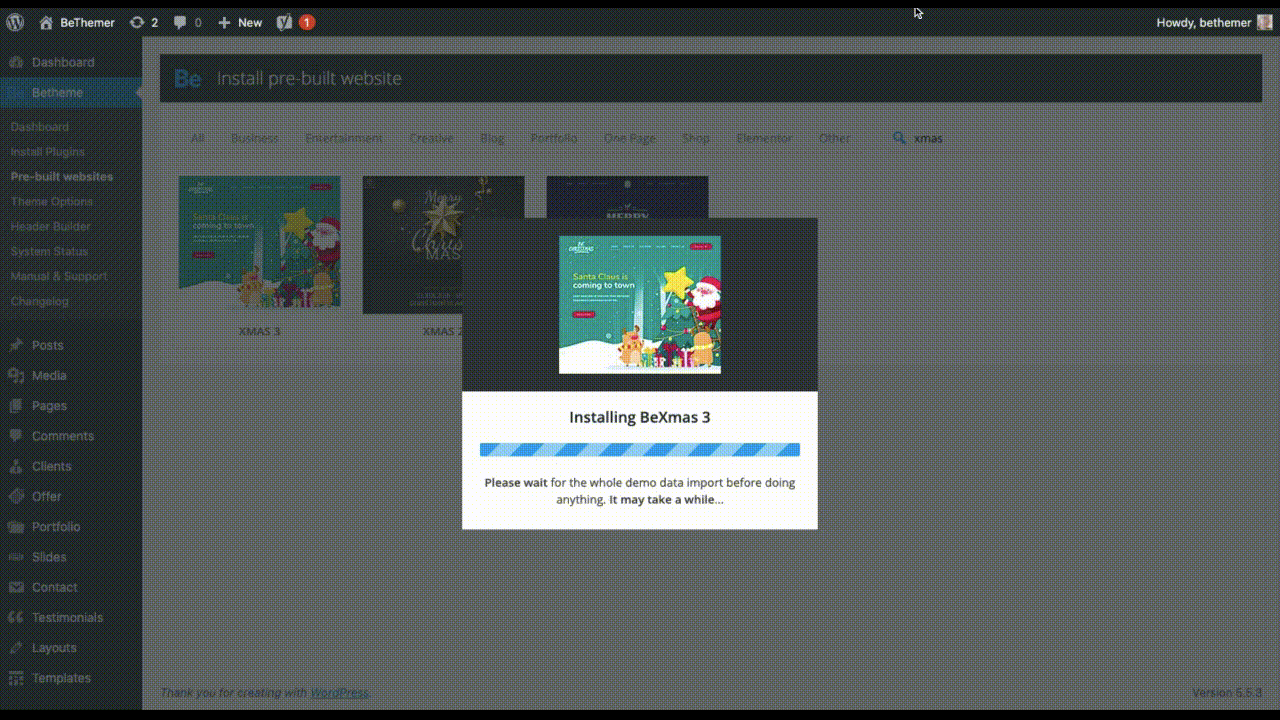
 The holidays are fast approaching. But that doesn’t mean it’s too late to get a new website online or to make your existing one look festive for the holiday season.
The holidays are fast approaching. But that doesn’t mean it’s too late to get a new website online or to make your existing one look festive for the holiday season.